Concurrency:
When the execution of two or more pieces of code act as if they run at the same time.
To have concurrency, you need to run code in an environment that can switch execution between different parts of your code when it is running. This is often implemented using things such as fibers, threads, and processes.
Parallelism:
When the execution of two or more pieces of code run at the same time.
To have parallelism, you need hardware that can do two things at once. This might be multiple cores in a CPU, multiple CPUs in a computer, or multiple computers connected together.
Topic 33. Breaking Temporal Coupling
Two aspects of time: concurrency & ordering
Coupling in time (Temporal coupling):
Assuming that one method should also come after the other in time order
We need to allow for concurrency and to think about decoupling any time or order dependencies. In doing so, we can gain flexibility and reduce any time-based dependencies in many areas of development: workflow analysis, architecture, design, and deployment. The result will be systems that are easier to reason about, that potentially respond faster and more reliably. (p.293)
Tip 56. Analyze Workflow to improve concurrency
Looking for concurrency:
To find out what can happen at the same time, and what must happen in a strict order, one can use an activity diagram
An activity diagram consists of a set of actions drawn as rounded boxes. The arrow leaving an action leads to either another action (which can start once the first action completes) or to a thick line called a synchronization bar. Once all the actions leading into a synchronization bar are complete, you can then proceed along any arrows leaving the bar. An action with no arrows leading into it can be started at any time.
You can use activity diagrams to maximize parallelism by identifying activities that could be performed in parallel, but aren’t. (p. 294)
Example of activity diagram:
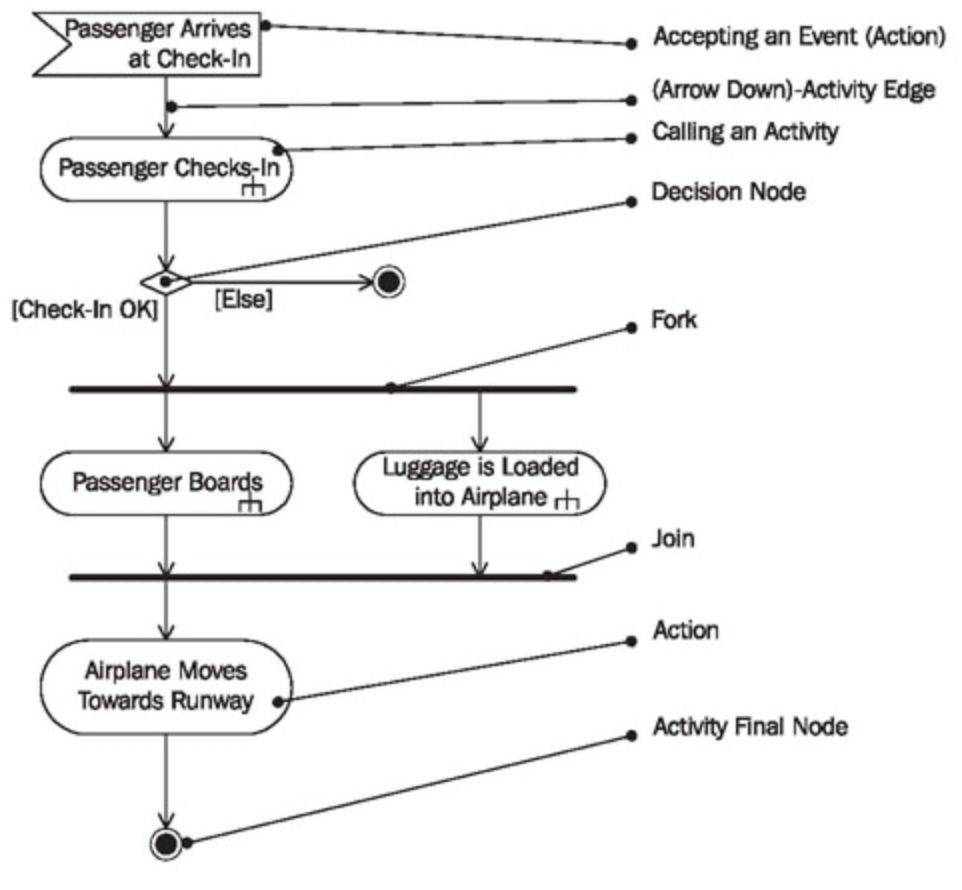
Actions that are forked can potentially be done concurrently.
Opportunities for concurrency:
(Software mechanism)
Actitivies that take time, but not time in our code.
Opportunities for parallelism:
(Hardware concern)
Work that are relatively independent—where each can proceed without waiting for anything from the others.
ex) take a large piece of work, split it into independent chunks, process each in parallel, then combine the results.
Topic 34. Shared State is incorrect state
Tip 57. Shared State is incorrect state
Make the state of the memory atomic.
Semaphores and other forms of Mutual Exclusion:
A semaphore is simply a thing that only one process can own at a time. It acts as a key for control access.
Classically, the operation to grab the semaphore was called P, and the operation to release it was called V. Today we use terms such as lock/unlock, claim/release. (p.302)
A process without control will be suspended until the semaphore is unlocked.
Drawbacks:
There are some problems with this approach. Probably the most significant is that it only works because everyone who accesses the pie case agrees on the convention of using the semaphore. If someone forgets (that is, some developer writes code that doesn’t follow the convention) then we’re back in chaos. (p. 302)
Make the resource transactional:
Centralizing control by centralizing resource access points into a single function, including the use of a semaphore.
Also, we need to ensure the semaphore will unlock upon failure so that the other processes won’t stall forever.
Non-transactional updates:
Whenever two or more instances of your code can access some resource at the same time, you’re looking at a potential problem.
Tip 58. Random failures are often concurrency issues
Topic 35. Actors and Processes
Actor:
An independent virtual processor with its own local (and private) state. Each actor has a mailbox. When a message appears in the mailbox and the actor is idle, it kicks into life and processes the message. When it finishes processing, it processes another message in the mailbox, or, if the mailbox is empty, it goes back to sleep.
When processing a message, an actor can create other actors, send messages to other actors that it knows about, and create a new state that will become the current state when the next message is processed.
Process:
A general-purpose virtual processor, often implemented by the OS to facilitate concurrency.
Processes can be constrained (by convention) to behave like actors.
Characteristics of Actors:
- Non-central — there is no orchestrated scheduling
- the message and local state of an actor can only be accessed by that actor
- Uni-directional communication
- An actor processes each message to completion, and only processes one message at a time.
As a result, actors execute concurrently, asynchronously, and share nothing. If you had enough physical processors, you could run an actor on each. If you have a single processor, then some runtime can handle the switching of context between them. Either way, the code running in the actors is the same. (p. 310)
Tip 59. Use actors for concurrency without shared state
Because actors have their own states and can only process one message at a time, there are no collisions and deadlocks. (unlike semaphores that have the risk of stalling in the lock state forever)
In the actor model, there’s no need to write any code to handle concurrency, as there is no shared state. There’s also no need to code in explicit end-to-end “do this, do that” logic, as the actors work it out for themselves based on the messages they receive.
There’s also no mention of the underlying architecture. This set of components work equally well on a single processor, on multiple cores, or on multiple networked machines. (p. 315)
소감
- 병렬 처리에 관한 지식이 있어서 그런지 이 부분은 읽기가 훨씬 쉬웠다...
- Actor라는 개념은 생소했지만 concurrency를 프로그래머가 의식할 필요는 없다는 점에서 굉장히 매력적인 방법론이라고 생각한다.
질문
- Python library인 Ray의 actor들도 이런 원리인가?
