'실리콘밸리에서 날아온 데이터 분야 커리어 특강' 한기용님의 강의 중 중요하다고 생각하는 부분을 정리했습니다.
데이터 엔지니어가 알아야 하는 기술
- SQL: 기본 SQL, Hive, Presto, SparkSQL
- 프로그래밍 언어: 파이썬, 스칼라, 자바
- 데이터 웨어하우스: Redshift, Snowflake, BigQuery
- ETL/ELT Framework: Airflow 등
- 대용량 분산 처리: Spark, YARN
- 클라우드 컴퓨팅: AWS, GCP, Azure
- 기타 상식: 머신러닝, A/B테스트, 통계
Roadmap: https://github.com/datastacktv/data-engineer-roadmap
데이터 분석가가 알아야 하는 기술
데이터를 기반으로 지표를 정의하고 시각화하고 다양한 분석을 통해 회사/팀의 방향/정책 결정에 도움을 제공
- 비즈니스 도메인 지식
- 데이터 관련 질문 대답: 질문들이 굉장히 많고 반복적이기에 어떻게 '셀프 서비스'로 만들 수 있는지가 관건
- SQL
- 대시보드 설계: Tableau, Looker, Excel, PPT
- 파이썬
- 데이터 모델링
- 통계 지식
- 좋은 지표를 정의하는 능력
데이터 분석가의 딜레마
- 보통 많은 수의 긴급한 데이터 관련 질문들에 시달림
- 좋은 데이터 인프라 없이는 일을 잘하기 힘들다
- 고과 기준이 불명확함
- 커리어에서 다음은 무엇인가?에 대한 질문을 지속적으로 함
지표/KPI와 시각화 툴
- KPI: Key Performance Indicator
- 정량적인 숫자
- 조직 내에서 달성하고자 하는 중요한 목표
- 잘 정의된 KPI을 문서화
- KPI의 수는 적을수록 좋음: 충돌 방지
- 지표는 더 큰 개념: KPI가 중요 지표
좋은 지표의 특성
- 3A: Accessible, Actionable, Auditable
- 지표를 확인하기 쉬어야 함: 시각화 툴
- 지표 등랑의 의미가 분명해야 함
- 데이터 기반으로 검증이 가능해야 함
데이터 과학자가 알아야 하는 기술
- 가설 설정 능력: 지표 기반 접근
- 머신러닝/인공지능에 대한 깊은 지식과 경험
- 코딩 능력: 파이썬, SQL
- 통계 지식, 수학 지식
- 끈기와 열정: 박사 학위가 도움이 되는 이유 중의 하나
- 점진적인 개선을 수행할 능력: 짧은 사이클로 반복할 필요, 애자일 기반의 모델링
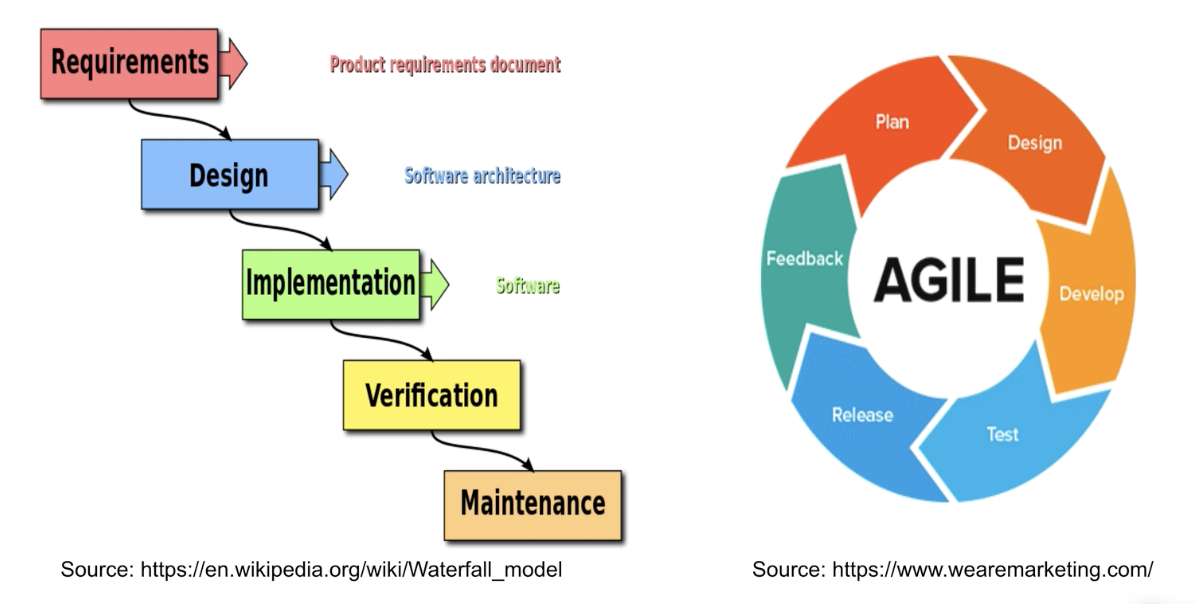
폭포수 개발방법론 vs. 애자일 개발방법론:
A/B테스트
- 모델의 최종적인 성능 평가는 A/B 테스트를 통해 이뤄지는 것이 일반적.
- 훈련용 데이터를 가지고만 검증하는 것은 불충분: 훈련용 데이터의 bias 때문에
- Control group & Test group: 극히 일부 사용자들에게만 새로운 기능을 노출하고 통제 집단과 비교.
- 어떤 지표를 가지고 성공/실패를 결정할지 선제적으로 정해야함: A/B 테스트를 제안하는 사람과 분석하는 사람은 분리되어야 객관적으로 진행이 됨
Ex: 먼저 5%에게 새 기능 노출. 나머지 95%의 사용자와 매출액과 같은 중요 지표를 기반 비교. 5% 대상으로 문제가 없으면 10%, 20% 점진적으로 노출된 유저 비율을 증가시킴. 그리고 최종적으로 모든 유저에게 노출.
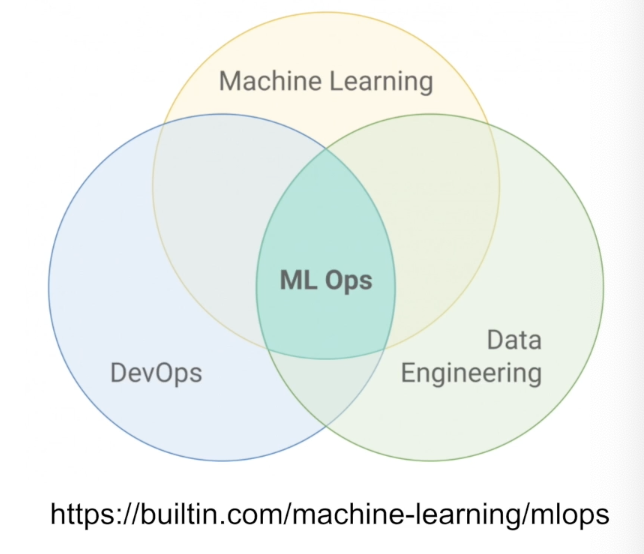
MLOps
DevOps란
- 개발자가 만든 코드를 시스템에 반영하는 프로세스 (CI/CD, deployment)
- 시스템이 제대로 동작하는 모니터링 하고 이슈 감지 및 해결
MLOps
- DevOps와 동일하지만 차이점은 서비스 코드가 아니라 ML 모델
- 모델을 지속적으로 빌딩(CT: continuous training)하고 배포
- 성능 모니터링
- 이슈 감지 후 해결
알아야 할 기술
- 데이터 엔지니어 지식:
- 파이썬/자바/스칼라
- 데이터 파이프라인과 데이터 웨어하우스
- DevOps 지식:
- CI/CD, 서비스 모니터링
- 컨테이너 기술: K8S, Docker
- 클라우드: AWS, GCP, Azure
- 머신러닝 관련 경험/지식
- 모델 빌딩 framework: SageMaker, Kuberflow, MLflow
- 모델 빌딩 framework: SageMaker, Kuberflow, MLflow
데이터 디스커버리 서비스
- 데이터가 커지면 테이블과 대시보드의 수 증가하면 정보 과잉과 혼란이 야기됨
- 주기적인 테이블과 대시보드 클리업이 필수
- 아문센(리프트), 데이터허브(링크드인), 셀렉트스타

우리는 데이터와 하나다