개요
이전 글에서 어떤 선배 분이 해당 질문을 하였다.
1. Redis 외에 동시성을 해결하는 방법은 없는가?
2. Redis가 정말 싱글 스레드가 맞는가?
3. Redis를 사용한 동시성 처리에서 발생할 수 있는 문제점은 없을까?
4. 동시성 처리 하나만을 위해서 Redis를 쓰는 것이 과연 옳은 것일까?
5. 동시성 이슈 해결 -> Redis 공식이 고착화된 이유는 무엇인가?이 글은 해당 질문에 대한 답변이다.
Redis 외에 동시성을 해결하는 방법은 없는가?
있다. 아주 명확하게. 다만 상황을 판단하고 이 많은 방법들 중에서 Redis를 선택한 것이다.
데이터베이스 수준에서 해결
비관적 락 (Pessimistic Lock)
- SELECT ... FOR UPDATE를 사용하여 트랜잭션이 완료될 때까지 다른 트랜잭션의 접근을 차단하는 방법
BEGIN;
SELECT like_count FROM retrospect WHERE id = 1 FOR UPDATE;
UPDATE retrospect SET like_count = like_count + 1 WHERE id = 1;
COMMIT;- 데이터 정합성을 강하게 보장하나 다른 접근을 막아버려 성능 저하가 발생한다. 경합이 많을 경우 데드락도 발생할 수 있다.
낙관적 락 (Optimistic Lock)
- version 필드와 Version 어노테이션을 사용하여 갱신 충돌을 감지하고, 충돌이 발생하면 재시도한다. 버전 관리를 생각하면 편하다.
@Entity
public class Retrospect {
@Id
private Long id;
@Version
private Long version;
private int likeCount;
}- 경합이 적을 경우 성능이 좋으나, 충돌 발생 시 재시도를 하므로 복잡성이 증가한다.
데이터베이스 원자적 연산
UPDATE retrospect SET like_count = like_count + 1 WHERE id = ?;- 간단하고 빠르며, 동시성 제어를 방지하나, 트래픽이 많아지면 성능 저하가 발생하고, 조회 쿼리가 많아지만 부하가 발생할 가능성이 크다. 즉 느리다.
애플리케이션 수준
Redisson 분산 락
- 이전에 했던 방식이다.
- Redis를 이용한 분산 락을 사용하여 특정 Key에 대한 동시 접근을 방지하며 비관적 락처럼 작동하지만 DB가 아닌 Redis에서 동작하므로 성능 부담이 적다. 또한 DB를 직접 갱신하기에 항상 최신 상태를 유지한다.
- 하지만, 락 획득까지의 대기가 필요하므로 상당히 느리며, 매 요청마다 DB 접근이 필요하기에 DB 부하가 높고, 트래픽이 높으면 락 획득에서 병목 현상이 발생할 수 있다.
메시지 큐 (Kafka, RebbitMQ, SQS)
- 동시 요청이 많을 때, 좋아요 요청을 메시지 큐(Kafka, SQS)에 넣고 순차적으로 처리하는 방식
- 즉 병렬 처리가 가능하며, 데이터 정합성 유지가 가능하다.
- 하지만, 큐를 별도로 관리해야 하며, 지연이 발생할 수 있다.
그러면 이 많은 방법들 중에 왜 Redis를 선택하였는가?
우선, 현재 API의 예상 상황을 나열해보자.
- 좋아요 기능은 매우 빈번하게 사용
- 모든 회고(Retrospect)에 적용되며, 회원들은 추천 회고를 평가하는 주요 기준으로 사용
따라서 처리 속도가 매우 중요하며, 수많은 요청을 감당할 수 있어야 함
- 모든 회고(Retrospect)에 적용되며, 회원들은 추천 회고를 평가하는 주요 기준으로 사용
- 정확한 정합성이 필수적이지 않음
- 좋아요 수는 정수(Integer) 값 하나일 뿐이며, 정합성이 약간 흔들려도 서비스에 큰 영향이 없음
- 만약 몇 초 차이로 동기화가 안 되더라도 좋아요 수가 크게 어긋나는 일은 없을 것이므로, 실시간 동기화가 반드시 필요하지 않음
- 그러나, 느리더라도 정확해야 함
- 추천 회고를 평가하는 데 사용되는 점수이기 때문에, 값이 잘못 반영되면 추천 시스템에 문제가 생길 수 있음
- 일부 요청이 무시되어 좋아요 토글 기능이 불안정하면 UX에 치명적인 영향을 줄 수 있음
위 상황에서 다른 방법들을 대입해보자.
- 비관적 락
- 좋아요 기능은 매우 빈번하게 사용되는데, 이 방법을 사용하면 다른 요청이 데이터를 수정할 때까지 기다려야 하며, 동시 요청이 많아지면 DB의 부하가 심해지고, 데드락 문제가 발생할 수 있음
- 낙관적 락
- 충돌이 발생하지 않으면 성능이 좋지만, 좋아요 같은 기능에서는 많은 사용자가 동시에 요청을 보내므로 충돌이 빈번하게 발생할 가능성이 높음
- 즉, 동시성이 낮은 환경에서는 효과적이지만, 높은 트래픽이 발생하는 좋아요 기능에는 적합하지 않음
- 데이터베이스 원자적 연산
- 동시성 문제는 해결되지만, 트래픽이 많아질 경우 DB 부하가 심각해질 수 있음
- 조회 쿼리가 많아지면 성능이 저하될 가능성이 큼 -> 회고는 조회의 빈번함이 정말 큰데, 해당 원자적 연산을 사용하면 DB가 맛이 갈 가능성이 높음
- 수많은 트래픽을 처리하기 위해 DB에 모든 요청이 직접 가는 것은 비효율적
- Redisson 분산 락
- 좋아요 요청을 순차적으로 처리하므로 정합성을 보장할 수 있음 (이건 Redis도 마찬가지)
- 하지만 트래픽이 몰리면 락을 획득하는 과정에서 병목이 발생할 가능성이 큼
- 즉, 좋아요 API의 응답 속도가 느려질 수 있음
- 메시지 큐 (Kafka, RabbitMQ, SQS)
- 좋아요 요청을 큐에 넣고 순차적으로 처리하면 데이터 정합성을 유지할 수 있음
- 하지만, 실시간 반응성이 떨어질 가능성이 높음
- 큐의 소비 속도가 빨라도, 처리량이 많아지면 대기 시간이 발생할 가능성이 있음
즉, 위의 이유로, 인메모리 기반이기에 빠르게 처리할 수 있고, Redis의 원자적 연산을 사용하여 동시 여러 요청이 와도 동시성 문제가 발생하지 않는다.
또한, DB에서 처리하지 않고 Redis에 좋아요 수를 관리하기에 DB 부하가 줄어들고, 좋아요 수를 조회할 때도 Redis에서 직접 가져오기에 데이터 불일치 문제는 발생하지 않는다.
그리고 DB는 수직 확장에 한계가 있으나, Redis는 클러스터 구성을 통해 확장이 가능해, 트래픽이 많아져도 성능 저하가 발생하지 않는다. (Auto Scaling을 생각하면 편하다.)
Redis가 정말 싱글 스레드가 맞는가?
- Redis는 싱글 스레드지만, 특정 작업은 멀티스레드로 수행한다.
싱글 스레드인 경우
- 기본적인 요청 처리 로직(SET, GET, INCR 등)은 싱글 스레드에서 실행된다.
- 즉, 같은 순간에 여러 클라이언트가 같은 데이터를 수정하는 경우라도, 요청이 직렬적으로 처리된다.
멀티 스레드인 경우
- redis document에서 single thread로 검색해 보면 다음과 같은 글을 볼 수 있다.
Redis는 single thread이며 multiplexing이란 기술을 사용하여 단일 프로세스가 모든 클라이언트 요청을 처리합니다.
모든 요청이 순차적으로 처리되며, 이는 Node.js의 작동 방식과 매우 유사합니다.
Redis 2.4부터는 디스크 I/O와 관련된 느린 I/O 작업을 백그라운드에서 수행하기 위해 여러 개의 스레드를 사용하지만 Redis가 단일 스레드를 사용하여 모든 요청을 처리한다는 사실은 바뀌지 않습니다.
Multiplexing이란?
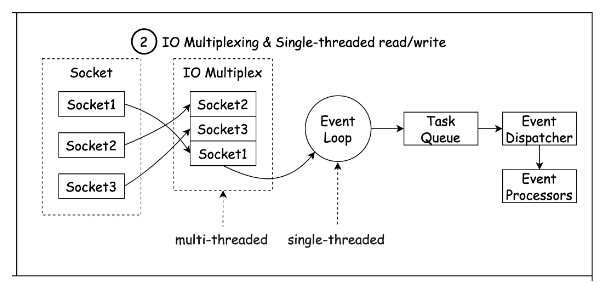
- 하나의 통신채널을 통해 다량의 데이터를 전송하는 데 사용되는 기술
- 즉, 매 요청마다 새로운 프로세스나 쓰레드를 생성하는 게 아니라 요청의 개수와 상관없이 한 개의 프로세스나 스레드를 이용하여 작업을 처리하는 것이다.
- 모든 작업처리는 단일 콜스택에서 이루어지고 비동기 처리는 Queue를 이용하여 이벤트 루프 방식으로 동작한다.
- 여러 개의 소켓이 동시에 연결되어 있고, 이들을 관찰하면서 들어오는 작업을 처리한다.
즉 순서를 정리해보면 다음과 같다.
- Redis는 새로운 클라이언트 연결, 클라이언트에서 들어오는 데이터 또는 I/O 작업 완료와 같은 이벤트가 발생하기를 기다리는 단일 이벤트 루프를 사용
- 새 클라이언트가 Redis에 연결되면 이벤트 루프에 등록되고 이벤트 루프는 들어오는 데이터에 대한 연결을 모니터링
- 클라이언트로부터 데이터가 도착하면 이벤트 루프는 이벤트 유형을 결정하고 그에 따라 처리
- 클라이언트의 요청에 I/O작업이 필요한 경우 이벤트 루프는 다른 클라이언트의 연결의 진행을 차단하지 않고 작업을 비동기적으로 수행
- 이벤트 루프가 여러 클라이언트의 이벤트를 처리할 때 각 클라이언트에 대해 보류 중인 작업 대기열을 유지 관리합니다. 이를 통해 Redis는 실제 처리가 단일 스레드 내에서 발생하더라도 동시에 여러 클라이언트에 서비스를 제공
즉, 기본적인 요청들은 전부 싱글 스레드를 사용하지만, I/O 작업등을 백그라운드에서 처리할 때는 비동기적으로 처리된다.
이는 위의 작업들이 상당히 오래 걸리기에, 이를 싱글 스레드로 처리하면 다른 요청의 지연이 발생하기에 해당 작업에 한해서 멀티 스레드로 처리한다.
즉, Single Thread라는 의미는 클라이언트의 요청인 Redis의 명령어를 처리하는 것에만 유의미하다.
프로덕션 환경에서 KEYS 명령어를 사용하면 안 되는 이유
위와 연결해서 프로덕션 환경에서 KEYS 명령어를 사용하면 안 되는 이유도 설명할 수 있다.
KEYS 명령어는 다음과 같이 동작한다.
KEYS *
KEYS user:*- KEYS 명령어는 Redis에 저장된 모든 키를 검색
- 특정 패턴(예: user:*)을 지정하면, 해당 패턴과 일치하는 모든 키를 찾아 반환
즉, KEYS는 Redis의 모든 데이터를 대상으로 스캔하는 방식으로 동작하기에 상당히 오래 걸리는 작업이다.
그런데 이건 일종의 명령어이므로 싱글 스레드 기반으로 동작한다. 즉, 데이터 크기가 커질수록 실행 시간이 길어지고, 해당 시간동안 Redis가 다른 요청을 처리하지 못한다.
이로 인해 실시간으로 동작하는 프로덕션에서 해당 명령을 실행하면 다음 문제가 발생한다.
- 모든 키를 검색하기에 CPU 사용량이 급증하고 응답이 지연된다.
- 이로 인해 Redis를 사용하는 API(로그인, 좋아요)를 사용할 수 없고 이는 서비스 장애로 이어진다.
- 클러스터 환경에서는 KEYS를 실행해도 원하는 결과를 얻을 수 없고, 특정 노드에만 과부하된다.
만약 해당 기능이 진짜로 필요하다면, 점직적으로 키를 검색하며 작은 단위로 데이터를 검색할 수 있는 SCAN 명령어를 쓰자.
SCAN 0 MATCH user:* COUNT 100Redis를 사용한 동시성 처리에서 발생할 수 있는 문제점은 없을까?
- DB와 함께 저장할 경우 서로 불일치하고 데이터가 유실될 수 있는 데이터 정합성 문제가 발생한다.
- 이는 Redis에만 좋아요 수를 저장하는 것으로 해결했다.
- 하지만 지금 해결되지 않은 문제는 Redis 자체가 장애가 발생하면? 이다.
- 현재 API 중에는 Redis를 사용하는 API들이 존재한다.
- 회원가입/로그인 API 중 Refresh Token을 저장하고 대조하는 API
- 위의 좋아요 API
- 하지만 Redis가 장애가 발생하면 해당 API를 사용할 수 없게 되고, 이 중 로그인 API는 가장 많이 사용하는 API이기에 심각한 문제가 발생한다.
- Redis를 재시작하면 해당 데이터들은 전부 초기화되며 이는 정말 심각한 문제이다.
- 현재 API 중에는 Redis를 사용하는 API들이 존재한다.
해결 방안
- AOF(Append-Only File) 활성화하여 데이터 영구 저장
- Redis 장애 발생 시, Fallback(대체 데이터 조회) 로직 적용
- Redis Sentinel 또는 Redis Cluster 구성하여 고가용성(High Availability) 확보
다음 해결 방안이 있고 이는 다음 글에서 구현해보는 것으로 한다.
동시성 처리 하나만을 위해서 Redis를 쓰는 것이 과연 옳은 것일까?
- 당연히 비효율적이다. 만약 단순한 동시성 제어 문제만을 해결하기 위해 Redis를 도입한다면, 이는 오버 엔지니어링일 가능성이 높다.
- 하지만 현재는 동시성 처리 외에도 캐싱, 세션 관리, 메시지 브로커, 랭킹 시스템, 분산 락, 스트림 처리 등 여러 기능을 활용하고 있다.
- 실제로 로그인 API에서도 RT 저장 후 서로 대조하여 탈취 여부를 확인하는 로직도 존재.
- 메시지 브로커일 경우 현재 SQS를 사용하지만, 후에 요금 문제로 리펙토링해야 할 경우 Redis로 리펙토링할 수도 있다.
- 자주 조회되는 데이터(좋아요 수 등)에 대해 DB 부하를 줄이기 위해 캐시 용도로 활용 중이다.
- 향후 추천 시스템, 실시간 데이터 처리, 랭킹 시스템 등에 Redis를 추가적으로 활용할 가능성이 있다.
동시성 이슈 해결 -> Redis 공식이 고착화된 이유는 무엇인가?
- 하나의 데이터를 동시에 여러 개의 요청이 수정하려 할 때, 데이터가 꼬일 수 있는 동시성 문제를 해결하기 위해 다음 조건이 필요하다.
- 원자적 연산 제공 → 여러 요청이 동시에 와도 하나씩 처리될 것.
- 빠른 성능 (고성능 트랜잭션 가능) → 트래픽이 몰려도 성능이 유지될 것
- 확장성 → 요청이 많아질 때, 안정적으로 처리할 수 있을 것
- 위 조건은 Redis로 한번에 충족이 가능하며, 이는 가장 간편한 방법이 되었기에 고착화가 되었다고 생각한다.
- 원자적 연산 제공 -> INCR, DECR, HINCRBY, SETNX 등의 원자적 연산
- 여러 요청이 동시에 발생해도, Redis 내부에서는 하나씩 직렬 실행
- 빠른 성능 -> Redis는 인메모리 기반으로 일반적인 RDBMS보다 빠르게 데이터 읽기/쓰기가 가능함
- 확장성 -> Redis는 클러스터(Cluster) 구성을 통해 수평 확장이 가능하며, 대량의 트래픽을 안정적으로 처리 가능
- 원자적 연산 제공 -> INCR, DECR, HINCRBY, SETNX 등의 원자적 연산
하지만 만능은 아니다.
- DB랑 같이 저장하면?
- 동기화가 제대로 되지 않을 경우 데이터가 꼬일 수 있다. (처음 API가 이랬다.)
- Write-Through 또는 Write-Behind 패턴 적용하여 Redis-DB 간 동기화 유지
- Redis와 DB가 동기화되도록 TTL(Time-To-Live) 설정을 조정
- Redis에서 일정 주기로 DB에 동기화하는 배치 작업 추가 (@Scheduled 활용)
- Redis 장애 발생 시, DB에서 데이터를 복구하는 로직 추가
- 나는 Redis에만 저장하는 것으로 해결했다.
- 동기화가 제대로 되지 않을 경우 데이터가 꼬일 수 있다. (처음 API가 이랬다.)
- Redis가 장애가 생겨서 재시작을 하면?
- Redis는 메모리 기반의 DB이기에 재시작 시 안의 데이터들은 전부 사라지며 이는 큰 문제이다.
- 추가적으로 AOF(Append-Only File) 또는 RDB Snapshot 활성화하여 데이터 백업 설정하자. (다음 할 일)
- Redis는 메모리 기반의 DB이기에 재시작 시 안의 데이터들은 전부 사라지며 이는 큰 문제이다.
즉, 해당 질문을 통해 Redis의 안정성에 대한 이슈가 새로 발견되었고, 다음 할 일을 이걸로 정했다.
Reference
