1. 본 강의를 수강하는 목적
-
지난 2021년 7월부터 12월까지 수강했던 패스트캠퍼스 K-digital training AI 데이터 사이언티스트 과정이 끝난 후, 데이터 사이언티스트로 거듭나기 위한 준비를 하던 중 원티드 프리온보딩 AI/ML 과정을 발견하게 되었다.
-
마침 해당 강의가 패스트캠퍼스 교육과정 중 final project로 kaggle Jigsaw Rate Severity of Toxic Comments 를 진행하며 공부했던 NLP 심화 과정임을 확인하였고, final project를 하면서 NLP에 대해 관심이 높아졌던지라 망설임 없이 신청하게 되었다.
-
그렇게 참여하게 된 본 과정에서 가장 바라는 것은 당연히 취업일 것이다. 패스트캠퍼스 AI 과정을 수료한 후 개인적으로 취업준비를 하며 부딪혔던 한계점은 1) AI/ML 직군에 취업을 준비하는 데에 있어 스스로 직무 분석이나 지향하는 업무를 특정하지 못했다는 것과, 2) 현재 내가 알고 있는 지식과 보유한 포트폴리오가 너무나 빈약하다는 점이었다.
-
이러한 문제로 인해 취업이 쉽게 풀리지 않았고, 특히 내가 지향하는 직무가 확정되지 않았다는 점으로 인해 개인 포트폴리오를 만들고자 할 때 일관적인 작업을 진행하지 못하게 되어 결국 악순환으로 이어졌다.
-
이런 상황에서 다수의 기업에서 원하는 직군이 특정되어 있고, 해당 직군의 분야가 final project에서 다뤄봤던 NLP이며, 정해진 직무로 취업 연계가 가능한 원티드 프리온보딩 AI/ML 과정은 내가 취업을 하는 데에 부족했던 모든 부분을 채워줄 수 있다고 생각했다.
-
해당 과정을 통해 NLP 분야의 직무를 구체화하고, 나의 skill stack을 어떤 방향으로 쌓을 것인지 설정하여 알맞은 포트폴리오를 만들어서 최종적으로 기업이 찾는 실무자로 거듭나기를 바라며 1주차를 과제를 진행한다.
2. 과제 - Paperwithcode NLP sub task
- Paperwithcode에서 NLP 분야 중 관심있는 task를 다음 두 개로 정해보았다.
2-1. Emotion Classfication
1) 문제 정의
-
Emotion Classification(감정 분류)이란 문장에 드러나는 작성자의 감정을 분류하는 것으로 정의할 수 있다.
-
예컨대 '이 영화를 보고 없던 암이 생겼습니다.'와 같은 문장이 있다면 해당 문장에서 드러나는 감정을 부정적인 감정 중 '답답함' 혹은 '분노'라고 분류하는 것이다.(물론 다분히 비유적인 표현이라 생각한다. 이런 문장의 감정 분류를 하기 위해서는 정말 많은 학습을 해야 하지 않을까?)
-
해당 기술을 적용할 수 있는 분야로는 소비자 반응 분석 등이 있을 것이다.
2) data 소개
-
Paperwithcode에서 소개된 data중 하나를 선정해 해당 data의 구성을 살펴보고자 한다.
-
기본적으로 문장에 담긴 작성자의 감정을 분류한다는 목적을 충족시키기 위해서는 문장별 감정 labeling이 필요할 것이다.
-
위와 같은 전제를 충족시키는 data로 GoEmotions를 선택했다.
-
해당 data는 Reddit이라는 커뮤니티에서 선별된 58K개의 comment를 수집하고 사람이 감정 분류 labeling을 진행한 data이다.
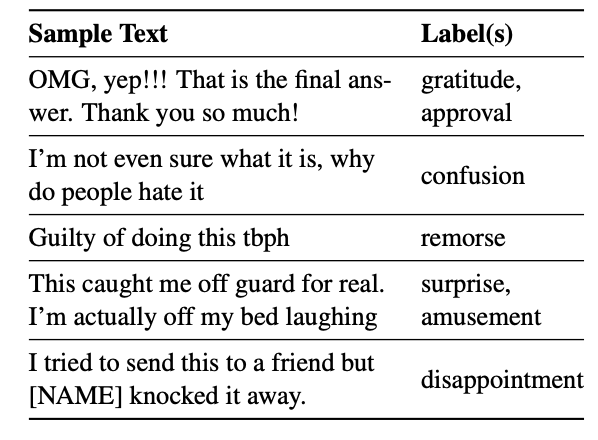
- data의 상세한 구성은 다음과 같다.
- text : comment 문장
- id : comment 별로 부여된 고유 id
- author : comment 작성자의 Reddit username
- subreddit : comment가 속한 subreddit
- link_id : comment의 link id
- parent_id : comment의 부모 id
- created_utc : comment가 생성된 timestamp
- rater_id : labeling한 사람의 고유 id
- example_very_unclear : 문장 감정 분류 난해함 여부(labeling한 사람 기준, Ture/False 로 구분, True일 경우 어떠한 감정 카테고리에도 labeling하지 않음)
- emotion categories : 총 27개의 감정과 neutral 카테고리, binary로 labeling됨
admiration, amusement, anger, annoyance, approval, caring, confusion, curiosity, desire, disappointment, disapproval, disgust, embarrassment, excitement, fear, gratitude, grief, joy, love, nervousness, optimism, pride, realization, relief, remorse, sadness, surprise
3) SOTA model 소개
-
SOTA model을 알아보기 이전에, Emotion Classification의 정의와 data를 살펴보던 중 문득 든 의문이 있었다.
사람의 감정이란 것이 꼭 하나의 카테고리로 정의 가능한 것인가?
-
처음 문제 정의의 예시로 들었던 문장을 다시 가져와보자. '이 영화를 보고 없던 암이 생겼습니다.' 라는 문장 안에만 해도 언급했듯 답답함, 불만, 분노와 같이 유추할 수 있는 감정이 아주 많다. 그리고 때로는 독자의 관점에 따라 충분히 다르게 정의할 수도 있다!
-
이러한 의문을 가지고 다양한 model을 탐색하던 중, 나의 생각을 예상이라도 했다는 듯 하나의 답안을 제시한 model paper를 읽게 되었다.
-
SpanEmo: Casting Multi-label Emotion Classification as Span-prediction
모델명 : SpanEmo
Dataset : SemEval 2018 Task 1E-c
(아쉽게도 배포된 dataset은 아니었다.) -
해당 model이 시도한 실험을 요약하자면 '감정 사이의 상관 관계를 통한 복합 감정 분류'라고 할 수 있다.
-
나의 의문처럼 하나의 문장에는 여러 복합적인 감정이 담길 수 있으나, 문장의 지배적인 감정을 긍정적/부정적이라는 대분류 안에서 구분한다면 둘 중 하나로 통일되는 것이 일반적이다.
well my day started off great the mocha machine wasn’t working
-
paper 내에서 제시된 예시를 보자면, 위의 문장을 지배하는 감정은 분명히 부정적임에도 불구하고 Emotion Classification 결과는 'anger, disgust, joy, sadness'였다. 'great'라는 표현이 문장을 'joy'라고 판단하게 한 것이다.
-
SpanEmo model은 위와 같은 상황에서 복합적인 감정 사이의 상관 관계를 만들어 최종적으로 감정 분류 결과의 오차를 줄일 수 있도록 하였다.
-
즉, 문장 안에 '긍정의 표현'과 '부정의 표현'이 상충되더라도 문장을 지배하는 감정과의 상관 관계를 따져 일관된(긍정적 혹은 부정적) 감정으로 분류할 수 있도록 하는 것이다.
2-2. Question Answering
1) 문제 정의
-
Question Answering(질답)은 일반적으로 주어진 문장에서 답을 찾을 수 없는 경우를 제외하고, 주어진 문장을 통해 질문과 답변을 생성하는 것으로 정의할 수 있다.
-
해당 분야에 속한 하위 분야로는 다음 네 종류가 있다.
1) Open-Domain Question Answering
2) Answer Selection
3) Community Question Answering
4) Knowledge Base Question Answering
-
각각의 분야마다 기반으로 삼는 data가 다르고, 최종 산출물이 달라지지만 이번 시간에는 Question Answering 전반에 대해 다뤄보고자 한다.
-
이런 Question Answering 기술의 활용 방식은 목적이 분명하지만 활용 가능한 산업은 아주 넓을 것으로 예상된다.
2) data 소개
- 인터넷이 보급된 이래로 수없이 많은 정보들이 온라인 상에서 공유되고, 다양한 분야의 질문과 답변이 여러 커뮤니티를 통해 오갔을 것을 생각하면 Question Answering에 활용할 수 있는 data는 정말 무궁무진하게 많을 것이라 생각된다.
- 예상처럼 각종 포럼 및 커뮤니티의 Q&A 게시판의 data들이 제공되는 중에 가장 활용이 많이 되고 있는 data를 소개하고자 한다.
- SQuAD(Stanford Question Answering Dataset)

- 해당 data는 위키피디아 문서에서 파생된 질문-답변 쌍으로 이루어진 dataset이다. 1.1 버전에는 107,785개의 질문-답변 쌍이 존재한다.
3) SOTA model 소개
-
Question Answering 분야의 경우 기존에 주어진 문장을 기준으로 알고리즘 스스로 독해하고, 질답하는 것이라 별도의 의문점이 들지는 않았다.
-
따라서 가장 최근의, 고성능을 보인 model을 선택하게 되었다.
-
현재 제공되어 있는 model 중 선택한 것은 다음 model이다.
-
LUKE: Deep Contextualized Entity Representations with Entity-aware Self-attention
-
해당 paper에는 LUKE model이 자연어 처리 관련 task에서 중요하게 다뤄지는 entity(학습에 사용되는 단위)를 얼마나 효율적으로 학습하는지 설명하고 있다.
마치며,
-
여기까지 원티드 프리온보딩 AI/ML 과정 1주차 과제를 마무리한다.
-
시간이 촉박하여 좀 더 깊은 고민을 하지 못해 아쉽지만 해당 과제를 통해 NLP 분야의 다양한 sub task를 확인해 볼 수 있었다.
-
Emotion Classification에 대해 공부를 하며 가장 즐거운 고민을 해보지 않았나 싶다. 앞으로 진행될 5주간의 여정이 기대된다.




Question Answering 설명 감사합니다 :)