📌 Scalar Functions
스칼라 함수란, 입력값을 기준으로 단일 값을 반환하는 함수이다.
이 중 많이 쓰이는 함수에 대해서 알아보자.
📒 UCASE
영문을 대문자로 반환하는 함수
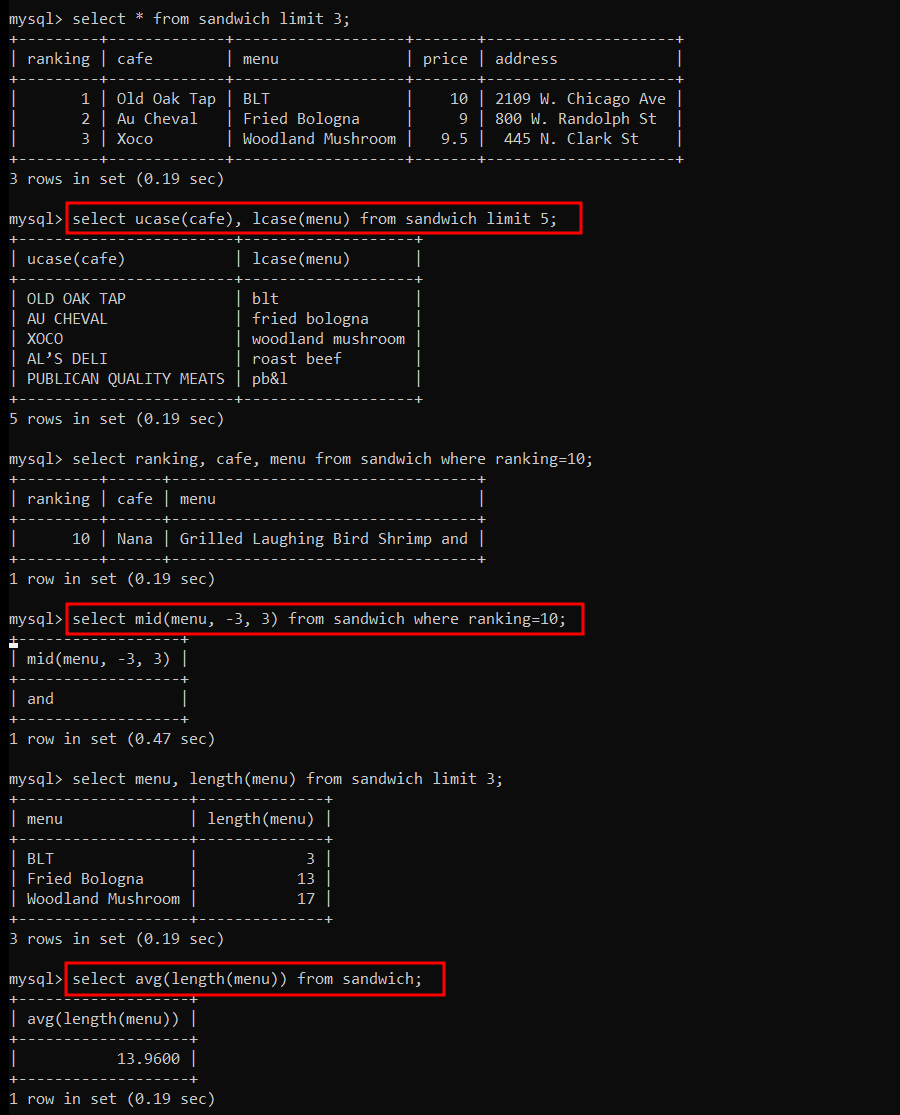
select ucase(string);다음 문장을 모두 대문자로 조회 (This Is ucase Test.)

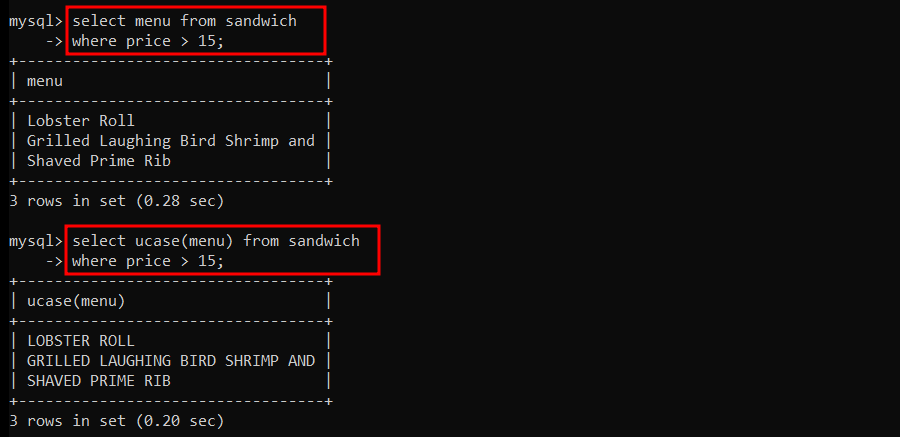
$15 가 넘는 메뉴를 대문자로 조회
📒 LCASE
영문을 소문자로 반환하는 함수
select lcase(string);다음 문장을 모두 소문자로 조회 (This Is LCASE Test.)

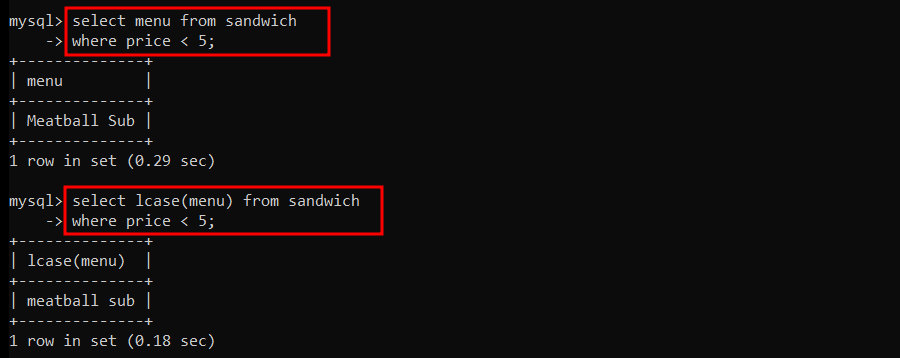
$5 가 안되는 메뉴를 소문자로 조회
📒 MID
문자열 부분을 반환하는 함수
select mid(string, start_position, length);start_position : 문자열 반환 시작 위치 (첫글자는 1, 마지막 글자는 -1)
length : 반환할 문자열 길이
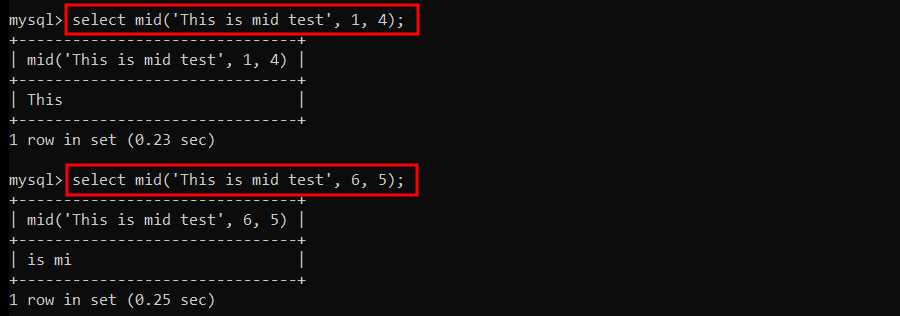
- 1번 위치에서 4글자를 조회 (This is mid test)
- 6번 위치에서 5글자를 조회
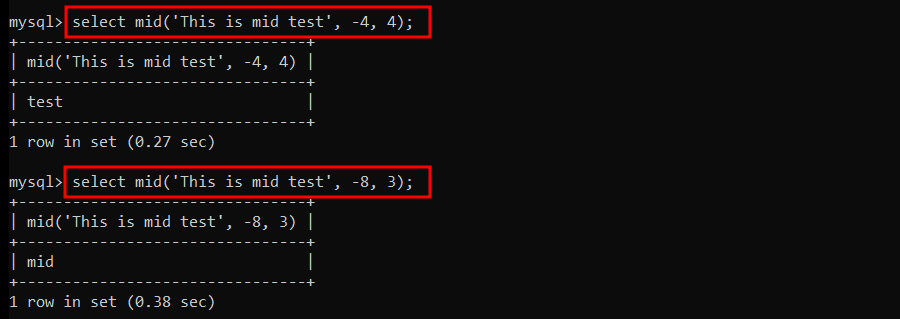
- -4번 위치 (뒤에서 4번째 위치) 에서 4글자를 조회
- -8번 위치 (뒤에서 8번째 위치) 에서 3글자를 조회
11위 카페이름 중 두번째 단어만 조회 (6번 위치에서 4글자)
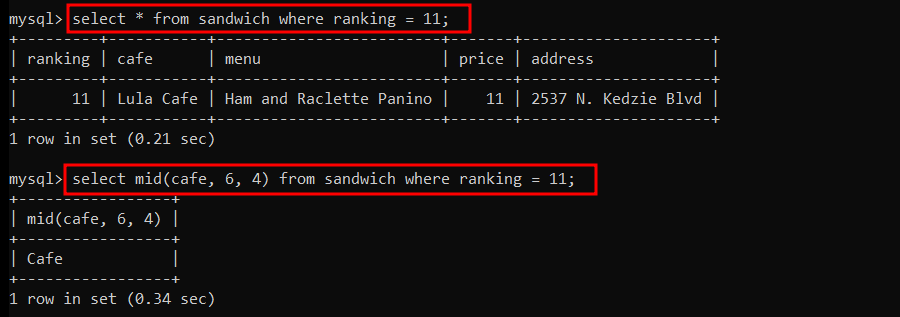
=> mid(cafe, -4, 4) 로 해도 같은 결과가 나온다.
📒 LENGTH
문자열의 길이를 반환하는 함수
select length(string);다음 문장의 길이를 조회 (This is len test)

- 문자가 없는 경우
- 공백인 경우
- NULL인 경우

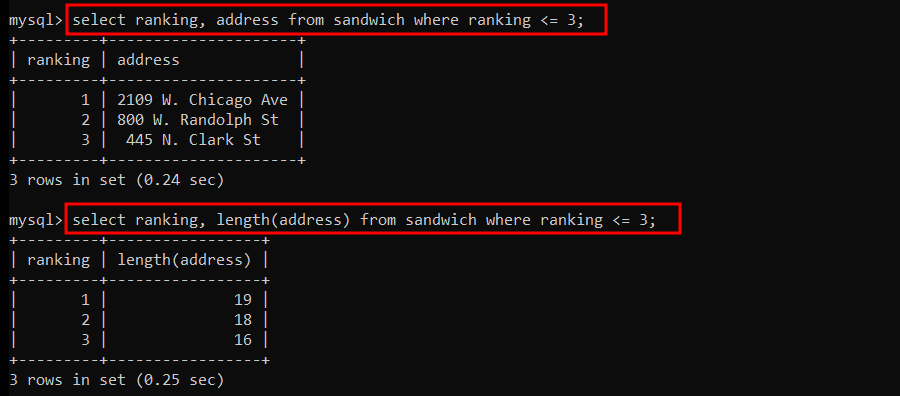
sandwich 테이블에서 TOP 3의 주소 길이를 검색
📒 ROUND
지정한 자리에서 숫자를 반올림하는 함수
select round(number, decimals_place);decimals_place : 반올림할 소수점 위치(자리)
✍
-
소수점 첫 번째 자리 : 0
소수점 두 번째 자리 : 1
소수점 세 번째 자리 : 2 -
일단위 자리는 -1
십단위 자리는 -2
반올림할 위치를 지정하지 않을 경우, 소수점 첫번째 자리 (0) 에서 반올림

- 소수점 두 번째 자리에서 반올림
- 일단위에서 반올림

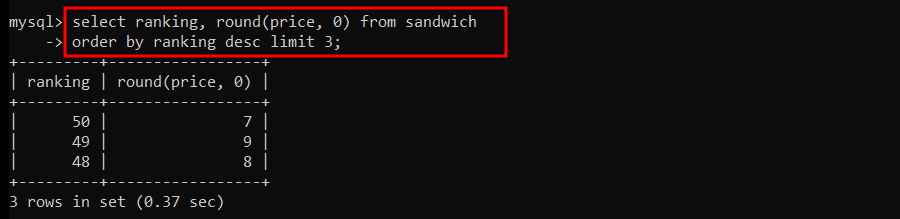
sandwich 테이블에서 소수점 자리는 반올림해서 1달러 단위까지만 표시 (최하위 3개만 표시)
📒 NOW
현재 날짜 및 시간을 반환하는 함수
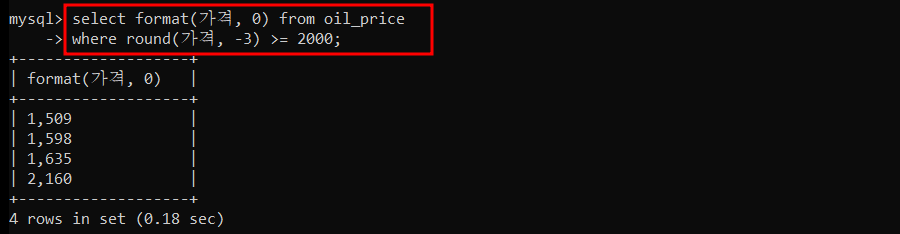
select now();📒 FORMAT
숫자를 천 단위 콤마가 있는 형식으로 반환하는 함수
select format(number, decimal_place);number : 포맷을 적용할 문자 혹은 숫자
decimals_place : 표시할 소수점 위치(자리)
✍
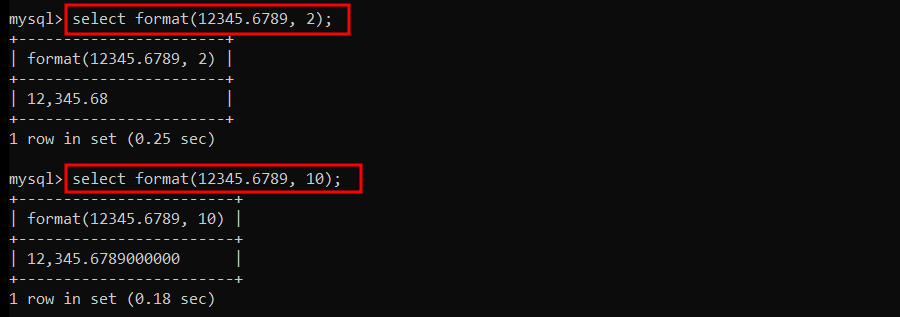
- format(num, 0) : 소수점이 없다. <= 소수 한자리에서 반올림해야 한다.
format(num, 2) : 소수점 두자리까지 표시 <= 소수 세자리에서 반올림해야 한다.
format(num, 10) : 소수점 열자리까지 표시 <= 소수 열한자리에서 반올림해야 한다.
만약, 없으면0으로 남은 자리를 채운다.
✍
ROUND 함수에서는 decimal_place 가 옵션이라 입력하지 않으면, 디폴트값인 0 으로 계산된다.
하지만, FORMAT 함수는 decimal_place 를 항상 입력해줘야 한다.
그리고, FORMAT 함수의 decimal_place 에는 (-) 값이 없다 ! 0부터 시작이다.
- 소수점 두자리까지 표시
- 소수점 열자리까지 표시
oil_price 테이블에서 가격이 백원단위에서 반올림 했을 때 2000원 이상인 경우,
천원단위에 콤마를 넣어서 조회
📒 실습
1) sandwich 테이블에서 가게 이름은 대문자, 메뉴 이름은 소문자로 조회하세요.
2) sandwich 테이블에서 10위 메뉴의 마지막 단어를 조회하세요.
3) sandwich 테이블에서 메뉴 이름의 평균 길이를 조회하세요.
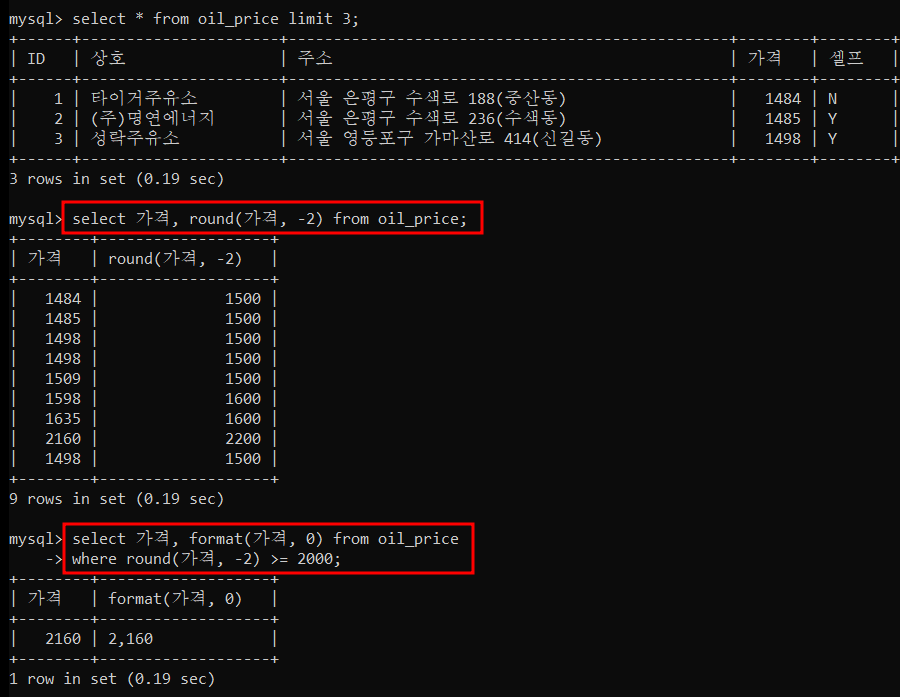
4) oil_price 테이블에서 가격을 십원단위에서 반올림해서 조회하세요.
5) oil_price 테이블에서 가격이 십원단위에서 반올림 했을 때 2000원 이상인 경우,
천단위에 콤마를 넣어서 조회하세요.
📌 SQL Subquery
(1) 하나의 SQL문 (메인쿼리) 안에 포함되어 있는 또 다른 SQL문 (서브쿼리) 을 말한다.
(2) 메인쿼리가 서브쿼리를 포함하는 종속적인 관계이다.
- 서브쿼리는 메인쿼리의 컬럼 사용 할 수 있다.
- 메인쿼리는 서브쿼리의 컬럼을 사용할 수 없다.
💡 서브쿼리 사용시 주의!
- 서브쿼리는 괄호로 묶어서 사용한다.
- 단일 행 OR 복수 행 비교 연산자와 함께 사용 가능하다.
- 서브쿼리에서는 ORDER BY 를 사용할 수 없다.
📒 Scalar Subquery
- SELECT 절에서 사용하는 서브쿼리
- 결과는 하나의 컬럼이어야 한다.
WHY?서브쿼리의 결과를 다른 SQL 연산에 사용하기 위해서는 단일 값을 반환해야 하기 때문이다.
select column1, (select column2 from table2 where condition)
from table1
where condition;=> 서브쿼리가 column1과 함께 출력되는 컬럼으로 인식되는 것 !
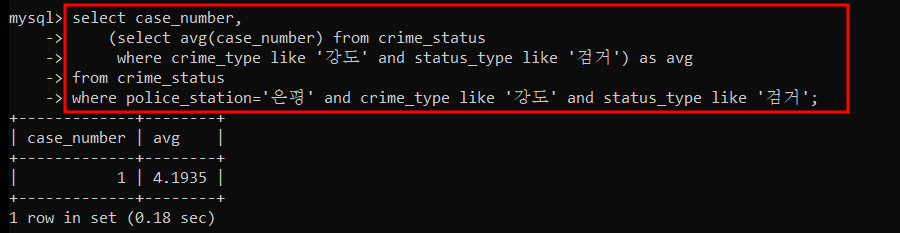
서울은평경찰서의 강도검거 건수와 서울시 경찰서 전체의 평균 강도 검거 건수를 조회
📒 Inline View
- FROM 절에 사용하는 서브쿼리
- 메인쿼리에서는 인라인 뷰에서 조회한 컬럼만 사용가능하다.
select a.column, b.column
from table1 a, (select column1, column2 from table2) b
where condition;FROM절에는 table이 오는 자리이기 때문에, FROM절에 서브쿼리가 오는 경우 서브쿼리가 실행된 결과 데이터셋을 하나의 테이블로 인지한다. 이를 뷰 테이블 이라 한다.
즉, a 테이블과 b 테이블을 조인해서 결과를 가져오게 된다. (SELF JOIN 참고)
경찰서별로 가장 많이 발생한 범죄 건수와 범죄 유형을 조회
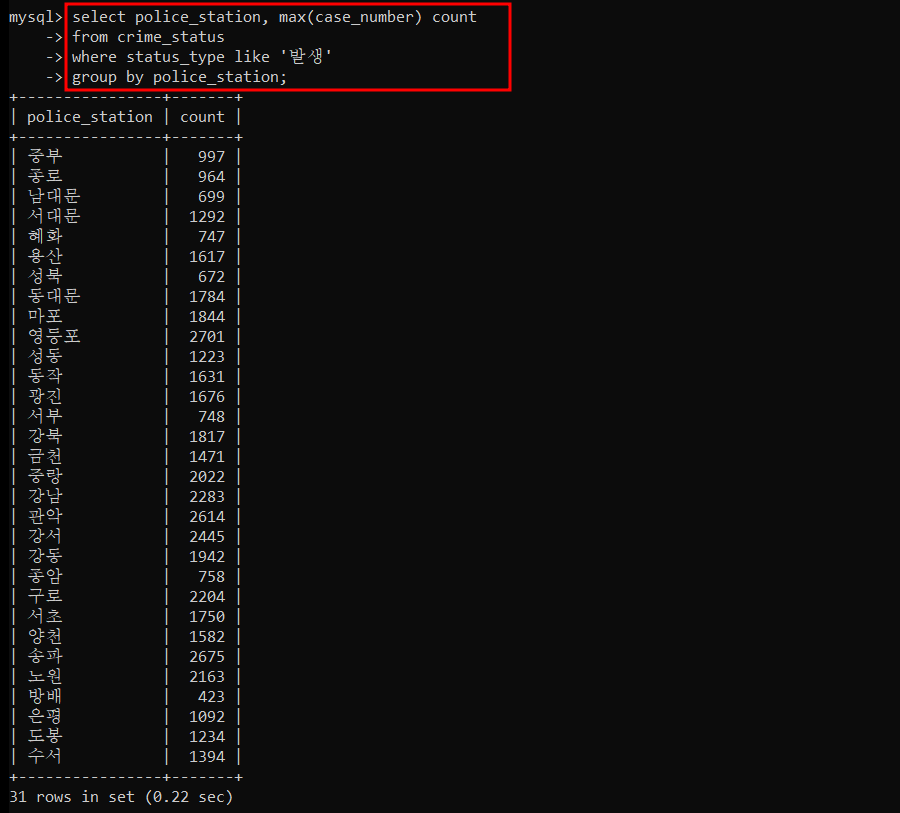
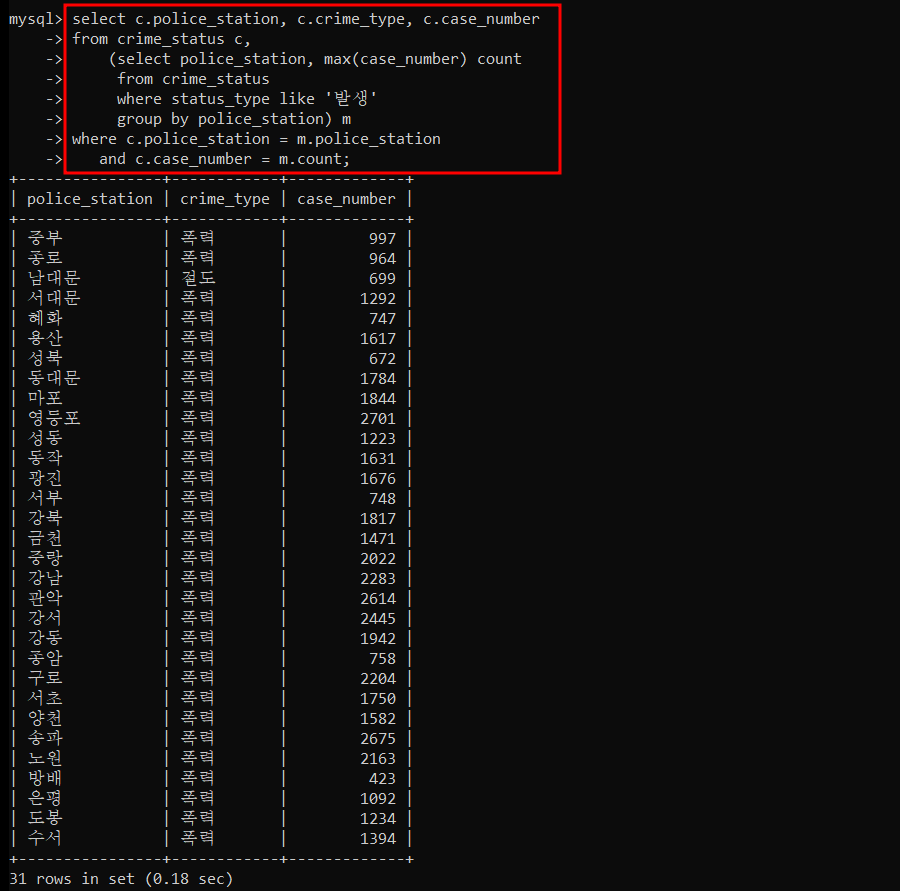
=> 서브쿼리만 따로 실행시켜봤다. 이 결과 데이터셋을 하나의 테이블로 인지해서 두 테이블의 동일한 요소들을 통해 결합한다.
=> JOIN 할 때 WHERE 절에 c.case_number = m.count 만 해줘도 될 것 같아서 한번 해봤더니 위와 같은 결과가 나왔다.
📒 Nested Subquery
WHERE 절에 사용하는 서브쿼리
- Single Row : 하나의 행을 검색하는 서브쿼리
- Multiple Row : 하나 이상의 행을 검색하는 서브쿼리
- Multiple Column : 하나 이상의 열을 검색하는 서브쿼리
(1) Single Row Subquery
서브쿼리가 비교연산자와 사용되는 경우, 서브쿼리의 검색 결과는 한 개의 결과값을 가져야 한다.
select column_names from table_name
where column_name = (select column_name # 비교연산자 '='
from table_name
where condition)
order by column_name; 예를 들어보자.
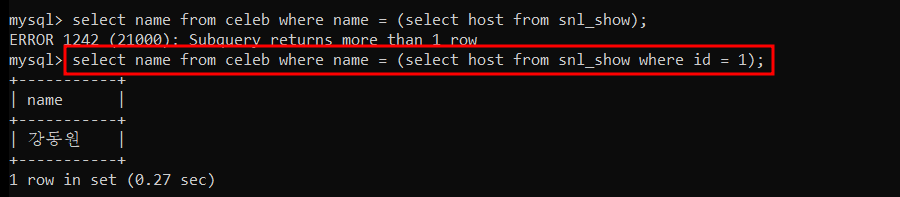
첫 번째 쿼리는 결과 데이터셋이 single row 가 아니기 때문에 오류가 발생한다.
id = 1 조건으로 결과 데이터셋을 single row 로 만들어주면 쿼리가 정상 실행된다.
(2) Multiple Row Subquery
일반적으로 비교연산자, IN, EXISTS, ANY, ALL 등과 같은 연산자를 사용한다.
- IN : 서브쿼리 결과 중에 포함될 때 반환
select column_names from table_name
where column_name in (select column_name
from table_name
where condition)
order by column_names; SNL 에 출연한 영화배우를 조회
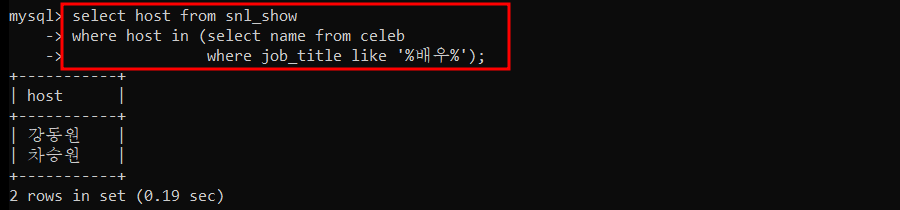
- EXISTS : 서브쿼리 결과에 값이 있으면 반환
select column_names from table_name
where exists (select column_name
from table_name
where condition)
order by column_names; 범죄 검거 혹은 발생 건수가 2000건 보다 큰 경찰서 조회
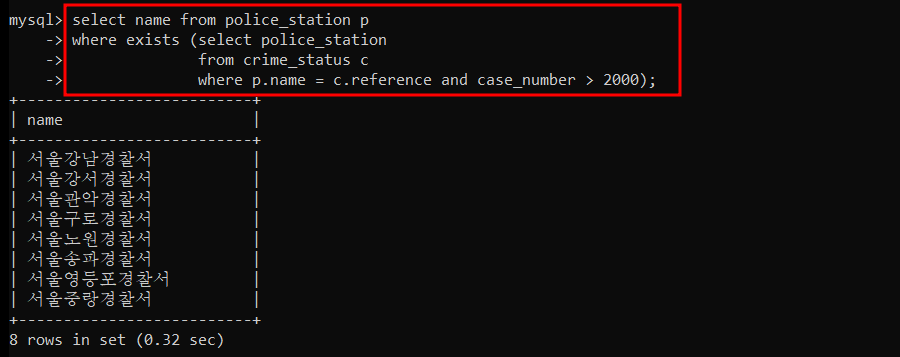
=> p.name 과 c.reference 를 조인한 상태에서 case_number > 2000 이라는 조건을 만족하는 값이 존재한다면(EXISTS) 해당 값을 조회한다.
✍
select distinct reference from crime_status
where case_number > 2000;이렇게 해도 될 것 같아서 해봤더니 같은 결과가 나왔다.
위의 예제는 EXISTS 를 사용하는 방법에 대해서 알기 위한 것이기 때문에 저런 식으로 쓰인다 정도로만 알아두자 !
- ANY : 서브쿼리 결과 중에 최소한 하나라도 만족하면 반환 (비교연산자 사용)
select column_names from table_name
where column_name = any (select column_name
from table_name
where condition)
order by column_names; SNL 에 출연한 적이 있는 연예인 이름 조회
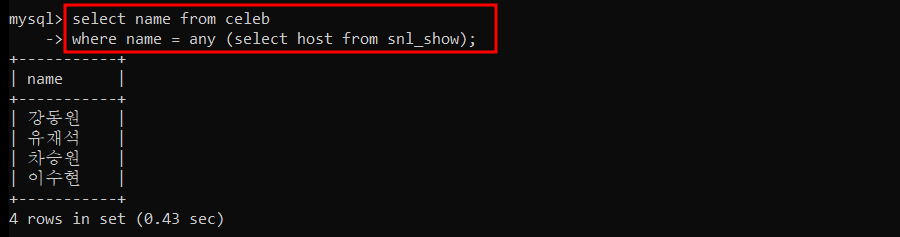
- ALL : 서브쿼리 결과를 모두 만족하면 반환 (비교연산자 사용)
select column_names from table_name
where column_name = all (select column_name
from table_name
where condition)
order by column_names; (3) Multiple Column Subquery (연관 서브쿼리)
서브쿼리 내에 메인쿼리 컬럼이 같이 사용되는 경우
select column_names
from table_name a
where (a.column1, a.column2, ...) in (select b.column1, b.column2, ...
from table_name b
where a.column_name = b.column_name)
order by column_names; => where a.column_name = b.column_name 이렇게 쓸 수 있는 이유는 서브쿼리에서는 메인쿼리의 컬럼을 사용할 수 있기 때문이다.
강동원과 성별, 소속사가 같은 연예인의 이름, 성별, 소속사를 조회

📒 실습
1) oil_price 테이블에서 셀프주유의 평균가격과 SK에너지의 가장 비싼 가격을 Scalar Subquery 를 사용하여 조회하세요.
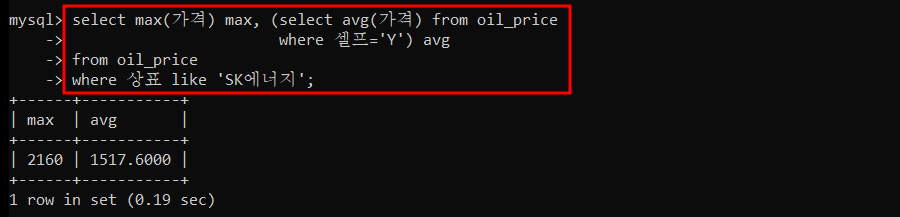
2) oil_price 테이블에서 상표별로 가장 비싼 가격과 상호를 Inline View 를 사용하여 조회하세요.
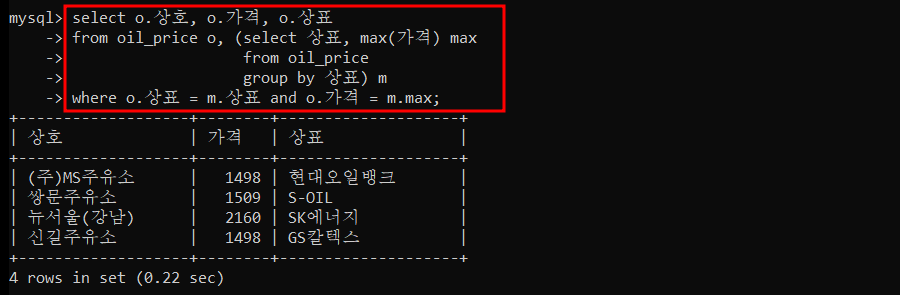
3) 평균가격 보다 높은 주유소 상호와 가격을 Nested Subquery 를 사용하여 조회하세요.
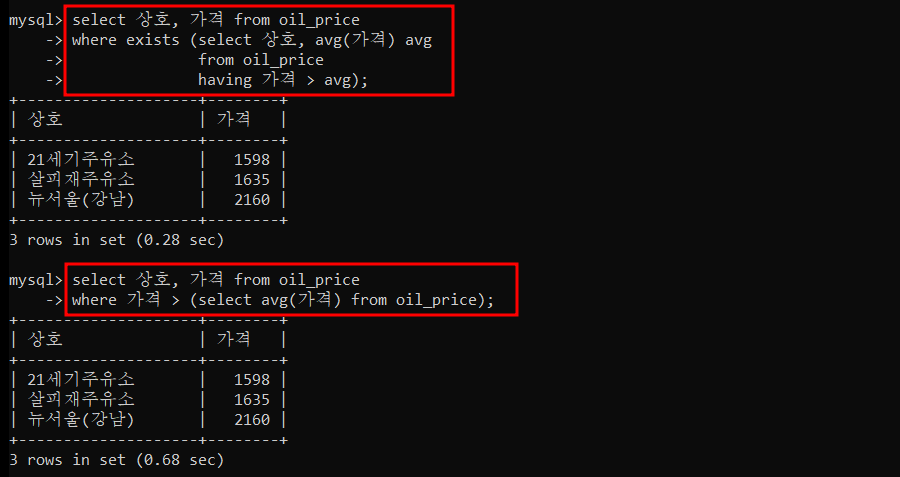
=> 첫 번째 쿼리에서는 서브쿼리에서 where 절을 사용하니 오류가 났고, having 절을 사용하니 정상적으로 출력이 됐다. where 절, having 절의 차이에 대해 이해가 부족해서 오류가 났던 것 같다. having 절은 그룹을 나타내는 결과 집합의 행에만 적용되고, where 절은 개별 행에 적용된다. 첫 번째 쿼리의 서브쿼리는 상호별 평균 가격으로 테이블 자체가 그룹이 되어 group by 가 없어도 단독으로 having 을 사용할 수 있다.
4) 3번에서 조회한 주유소에서 주유한 연예인의 이름과 주유소, 주유일을
Nested Subquery 를 사용하여 조회하세요. (refueling 테이블)
5) refueling 테이블과 oil_price 테이블에서 10만원 이상 주유한 연예인 이름, 상호, 상표, 주유 금액, 가격을 Inline View 를 사용하여 조회하세요.
