Hash table
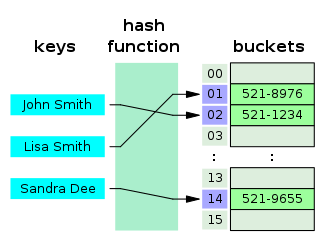
key와 value로 데이터를 저장하는 자료구조로 내부적으로 배열(bucket)을 사용하여 데이터를 저장한다.
시간복잡도는 O(1)로 O(log n)인 BST보다 빠르다.
이렇게 빠른 검색이 가능한 이유는 각각의 key값에 해시함수를 적용해 배열의 고유한 index를 생성하고 이 index를 활용해 값을 저장하거나 검색한다.
이러한 과정을 해싱이라고 한다.
ex
key : "abc"와 value : 123이 주어졌을 때
hashFunction("abc") % <hash_size>
위와 같은 해싱을 거쳐 index 값을 계산한다.
hashFunction("abc")가 100이고 <hash_size>가 4라고 가정할 때,
index == 100 % 4로 0이 되며
bucket [0] = 123로 bucket에 값을 저장한다.
상기한 해싱 구조로 데이터를 저장하면 데이터를 찾을 때 key값으로 해시 함수를 1번만 수행하면 되므로 데이터의 저장/수정/탐색이 매우 빠르다.
해시 충돌
key : "abc"와 key : "cba"의 해싱한 값이 동일하다면 해시충돌이 발생하게 된다.
이때 linked_list의 구조로 "abc"의 뒤에 값을 추가한다.
bucket[0] -> "abc" -> "cba"
unordered_map
#include <unordered_map>
std::unordered_map<[[keyType], [valueType]>map과 비슷하지만 BST구조인 map과 다르게 Hash Table 구조를 가진다.
map과 동일하게 중복을 허용하지 않는다.
map은 자동으로 정렬이 되어 순서가 정해져 있지만
unordered_map은 정렬이 되지 않아 순서가 정해져 있지 않다.
기본 형태는 위에 서술한 바와 같지만 정의를 보게되면
template <class Key,
class Ty,
class Hash = std::hash<Key>,
class Pred = std::equal_to<Key>,
class Alloc = std::allocator<std::pair<const Key, Ty>>>
class unordered_map;
Keykey type
Ty매핑되는 type
Hash해시 함수
Pred비교 함수
Alloc할당자
위와 같이 선언을 할 수 있다.
std::unordered_map<int, string> um0{
{4, "40"},
{1, "10"},
{2, "20"},
{3, "30"},
};
cout << "um0[3] : " << um0[3] << endl;
for (const auto& [key, value] : um0)
cout << key << " : " << value << endl;
cout << endl;실행 결과
um0[3] : 30
4 : 40
1 : 10
2 : 20
3 : 30
bucket_count, bucket_size
um.bucket_count()
bucket의 총 개수를 반환한다.
um.bucket_size(<key>)
key가 가리키는 bucket의 크기를 반환한다.
즉, bucket[hashFunction(key)]의 크기
예제
unordered_map<int, int, std::hash<int>> um1;
for (int i = 0; i < 100000; i++)
um1[i] = i;
cout << um1.bucket_count() << endl;
cout << um1.bucket_size(0) << endl;
cout << um1.bucket_size(1) << endl;실행 결과
16384
1
1
unordered_map에서의 해시 충돌
unordered_map에서는 해시 함수를 임의로 정의하여 선언할 수 있다.
하지만 잘못 정의하게 되면 빈번한 해시 충돌로 인해 시간복잡도가 상당히 높아질 수 있다.
struct HashFunction {
std::size_t operator()(const int& key) const {
return 1;
}
};
unordered_map<int, int, HashFunction> um1;
for (int i = 0; i < 10000; i++)
um1[i] = i;
cout << um1.bucket_count() << endl;
cout << um1.bucket_size(0) << endl;
cout << um1.bucket_size(1) << endl;실행 결과
16384
0
10000
HashFunction의 return값이 무조건 1이기 때문에 um1.bucket_size(1)이 10000인것을 볼 수 있다.
key : 1에 이미 값이 있기 때문에 0 부터 10000까지의 탐색을 전부 하고 마지막으로 정해진 return 값이 1에 value를 저장하기 때문에 시간이 많이 걸린다.
Unordered Associative Containers는 Ordered Associative Containers와 비슷하게 작용하지만
unordered는 순서가 없고,
삽입/삭제/탐색의 시간복잡도가 O(1)만큼 걸리지만 충돌이 발생할 수 있다는 차이가 있다.
