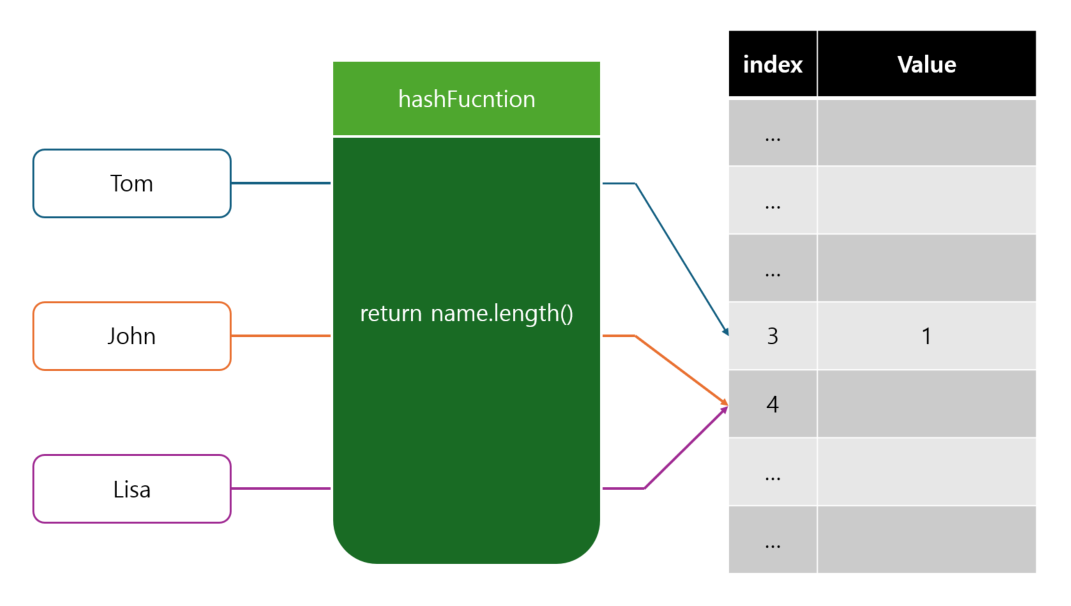
해시 알고리즘은 데이터를 저장하고 검색하는 알고리즘 중 하나이다.
해시 알고리즘은 크게 Key Value Hash Function Hash Table 4가지로 구성되어있다.
데이터를 저장 할 때는 Key를 받아서 해시 함수를 거치게 되고, 해시 함수를 거친 Key는 해시 코드로 저장되며 이 해시 코드를 배열의 인덱스 값으로 저장한 후 배열에 Value를 저장하게 된다.
이렇게 데이터를 저장하게 되면 Key 값으로만 데이터를 탐색할 수 있기 때문에 시간 복잡도는 O(1)이 된다.
간단한 예시를 보자
public class Main {
public static int hashFunction(String key) {
return key.length();
}
public static void main(String[] args) {
int[] names = new int[10];
String name0 = "Tom";
String name1 = "John";
String name2 = "Lisa";
int hashCode0 = hashFunction(name0);
int hashCode1 = hashFunction(name1);
int hashCode2 = hashFunction(name2);
names[hashCode0] = 1;
names[hashCode1] = 2;
names[hashCode2] = 3;
}
}Key인 문자열의 길이를 해시코드로 반환하는 해시함수를 정의하고 이 해시코드를 인덱스로 Value 인 정수를 배열에 저장했다.
하지만 hashCode1과 hashCode2가 같다는 것을 눈치 챌 수 있다.
이렇게 된 경우를 Hash Collision 해시 충돌이라고 한다.
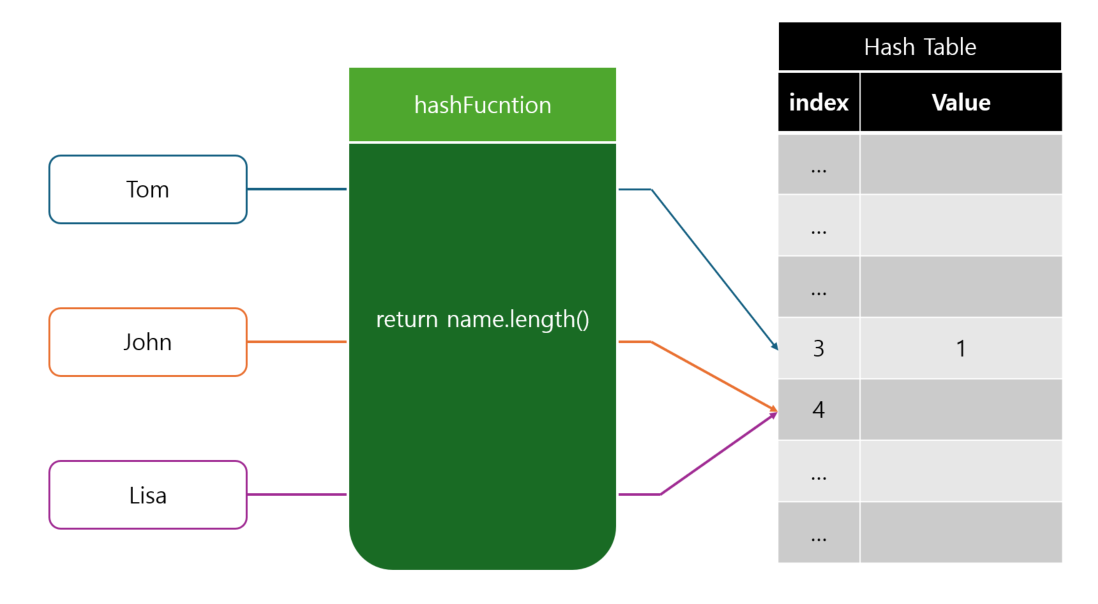
해시 충돌의 해결 방안
Chaning
중복 된 해시 값이 있는 경우 저장하는 배열의 해당 슬롯을 연결 리스트로 저장한다.
하지만 해시 충돌이 빈번하게 일어날 경우, 최악의 경우에는 수행시간이 O(n)이 된다.
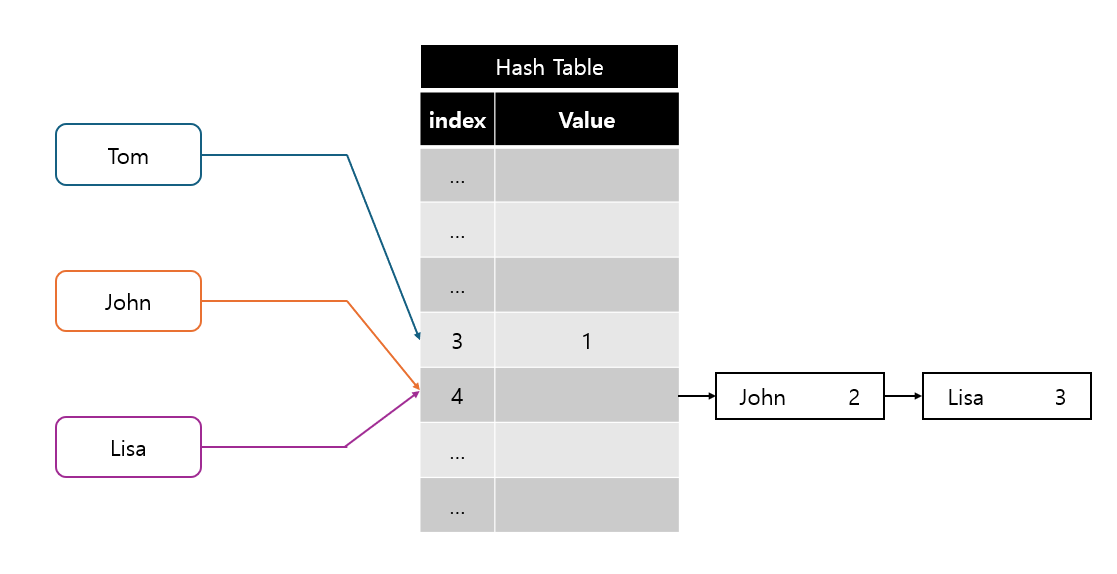
위 그림처럼 4번 인덱스에 연결리스트를 추가하여 John과 Lisa의 데이터를 저장한다.
Open Addressing
해시 충돌이 발생하면 해시 함수로 얻은 주소가 아닌 다른 주소에 데이터를 저장한다.
하지만 한번 해시 충돌이 발생하게 되면 집중적으로 충돌이 발생하는 primary clustering이 발생할 수 있다.
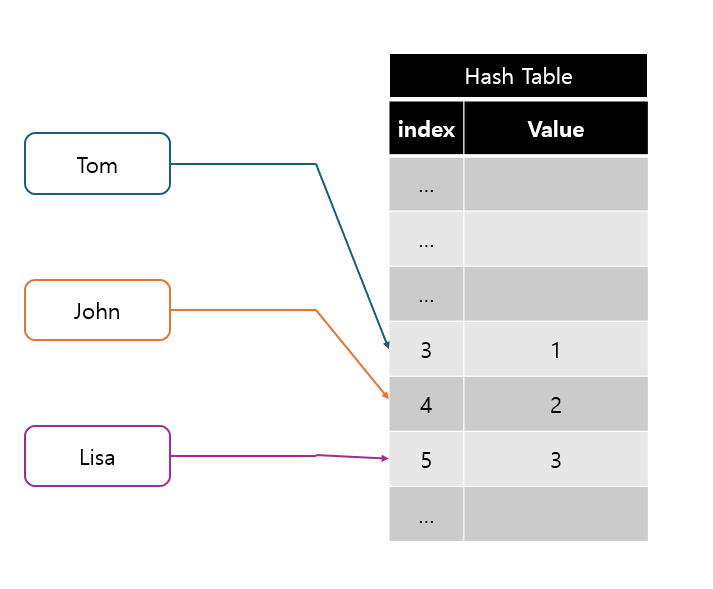
위 그림처럼 기존의 Lisa의 인덱스가 아닌 비어 있던 5번 인덱스에 Lisa의 데이터를 저장한다.

어중이떠중이