Components of a Computer
CPU : Control + Datapath
❓CPU?
컴퓨터의 기억, 해석, 연산, 제어라는 4대 주요기능을 관할하는 장치를 말한다
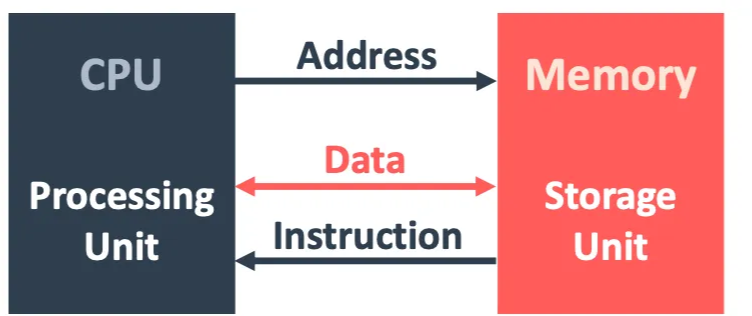
Memory
I/Os - input/output의 약자
- GUPs
- User-Interface Devices
- Storage Devices
Von Neumann Architecture
폰 노이만이 제시한 컴퓨터 구조로 중앙처리 장치, 메모리, 프로그램으로 구성되어 있다.
Microprocessor
Microprocessor의 정의
하나의 은 반도체 칩으로 만들어진 처리장치
컴퓨터 프로그램의 작동을 수행하기 위한 산술 및 제어 로직 회로를 포함
The Moore’s Law
24개월을 주기로 칩의 성능이 두배로 향상된다는 법칙.
Architecture: Exploiting Parallelism
Instruction Level Parallelism
Instruction을 병령적으로 처리하는 방법.
- Pipelining
- Superscalar
- Out-of-order Exscution
Data Level Parallelism
Data를 병렬적으로 처리하는 방법.
- SIMD / Vector Instructions
Task Level Parallelism
Task를 병렬적으로 처리하는 방법.
- Simultaneous Multithreading
- Multicore
Instruction Set Architecture (ISA)
하드웨어와 소프트웨어 사이에 Interface를 정의하는 것. 하드웨어와 프로그램 사이의 매개체 역할을 하는 것 이다.

ISA의 예시
- 하드웨어의 추상을 소프트웨어에서 볼 수 있다.
- CPU가 어떻게 작동하는지 써논 것
Abstraction is Good
- 추상화는 복잡성을 다루는데 도움을 준다.
- 더 좋은, 더 나은 프로그램을 원할 때 도움을 준다.
- 하위 요소들을 이해를 필요로 한다.
How to Define Performance?
Measuring Time
measring cpu performance
To compare 2개의 성능을 비교하는 방법
x와 y가 있다고 가정
- Performace_x/Performace_y 가 1보다 크면 x의 성능이 y의 성능보다 좋다.
- 반대의 경우 y의 성능이 좋다.
❗Performacer는 높을 수록 좋고, 실행시간은 적을 수록 좋다. 성능은 실행시간과 반비례 관계를 가진다.❗️
Clock Cycle Time vs. Clock Rate
Clock Cycle Time

Clock Rate
1초당 처리하는 Clock cycle time을 나타낸다.
- 단위 : HZ
- 예를 들어, 3.5 GHz의 클럭 속도를 가진 CPU는 1초에 35억 번의 클럭 주기를 수행할 수 있다는 뜻.
Excution Time
cpu의 실행시간은 프로그램이 얼마나 오래동안 실행되었는지를 지표로 사용한다.
실행시간 계산 공식
위 식을 바탕으로 아래 식도 유도할 수 있다.
Measuring clock cycles
cpu clock cycles / program 은 직관적이지 않다. → 추정하기 매우 어렵다.
CPI - Cycles Per Instruction
명령어 하나를 실행하는 데 걸리는 평균 클럭 사이클 수
- CPI가 비번하게 지표로 사용된다.
- 즉, CPI가 낮을 수록 성능이 좋음
- ISA간의 성능을 비교할 때 좋은 지표가 됨.
예를 들어, 프로그램을 실행하는 동안 1000개의 명령어가 실행되었고, 총 5000번의 클럭 사이클이 걸렸다면, CPI는 다음과 같이 계산됩니다:
CPI이 평균 값인 이유
각 명령어마다 걸리는 클럭 사이클 수가 다르기 때문에, 실제로 모든 명령어에 대해 동일한 클럭 사이클 수가 사용되지 않습니다. 예를 들어, 산술 연산은 상대적으로 짧은 시간이 걸릴 수 있지만, 메모리 접근이나 입출력 명령어는 더 많은 클럭 사이클이 필요할 수 있습니다. 따라서, CPI는 다양한 명령어들의 클럭 사이클 수를 평균내어 구하게 됩니다.
Using CPI
Therefore
- 모든 명령어 수 X CPI 를 하면 ⇒ 모든 CLock cycle의 수가 나온다. 그 후, 사이클 하나당 시간을 곱하면 전체 실행 시간이 나옴.
→ 아래 식을 유도할 수 있다.
여기서 의문
아래 예시를 보자
Examples
- Machine A - 1ns clock and CPI of 2.0
- Machine B - 2ns clock and CPI of 1.2
( 실행 명령어 개수는 같다고 가정한다.)
CPI만 보면 명령어 하나를 처리하는 클럭의 평균 수이므로, B가 A보다 더 빠르다고 생각할 수 있다. 과연 그럴까?
성능 계산
⇒ 성능은 A가 더 좋다.
계산 결과 A가 성능이 좋다는 결과가 나왔다. → CPI와 다른 결과 도출
CPI Variabillity
같은 프로세스 여도 명령어 타입 마다 clock cycles의 수가 다르다.
: i 타입의 명령어의 개수
: i 타입의 명령어의 clock cycle 수. 즉, i타입의 CPI
Another Popular Performance Metrics
MIPS (Mliiion instrictions per second)
초당 100만 개의 명령을 수행할 수 있는 능력
문제점 : MIPS 는 명령어의 집합을 고려하지 않음. 즉, 그 명령어 하나가 얼마나 많은 일을 수행하는지 반영하지 않는다. → 명령어 집합이 달라지면, 명령어의 개수가 달라지기에 성능을 비교하기 힘들다.
Benchmarks
벤치마크는 작업량의 속성을 추출하는 것이다
사실상의 산업 표준 : SPEC
Amdahl’s Law
프로그램은 병렬처리, 순서처리가 가능한 부분으로 구성되어 있으므로 아무리 병렬화를 시켜도 더 이상 성능이 향상되지 않는 다는 한계가 존재한다는 법칙
Execution speedup is proportional to the size of the
improvement and the amount affected
실행 속도 향상은 개선 규모와 영향을 받는 양에 비례.


굿