Mongodb
nosql의 특징으로 스키마가 없고, 지연성이 적고, 분산아키텍쳐, 객체기반API을 이용해서 빠른처리를 위해 쓰기 좋다.
먼저 사용법은 서버를 통해 Mongodb를 실행하고 연결한다.
> mongod
> mongo이후에 필요한 데이터베이스를 선택한다.(존재하지 않는다면 만든다.)
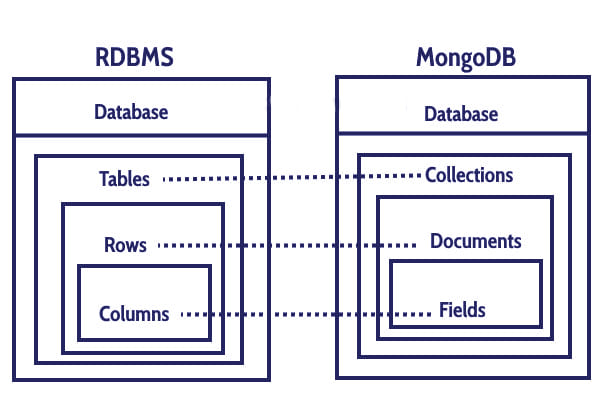
> use mydb이후 컬렉션을 확인하기위해(sql에서 테이블) 아래 명령어를 사용한다.
> show collections물론 위처럼 터미널에서 실행해도 좋지만 더욱 쓰임세를 높이기 위해서
pymongo를 이용한다.
import pandas as pd
from pymongo import MongoClient
import json
def mongoimport(csv_path, db_name, coll_name, db_url='localhost', db_port=27017):
""" Imports a csv file at path csv_name to a mongo colection
returns: count of the documants in the new collection
"""
client = MongoClient(db_url, db_port)
db = client[db_name]
coll = db[coll_name]
data = pd.read_csv(csv_path, index_col = 0)
payload = json.loads(data.to_json(orient='records'))
coll.delete_many({})
coll.insert_many(payload)
for x in coll.find():
print(x)
mongoimport("./csv/colors.csv", "coloravg", "color")
위는 로컬호스트 환경에서 특정 csv파일을 변환해서 mongo에 저장하는 형태이다.

방문해주셔서 감사합니다!