초기 메모리 구조에서는 프로세스를 하나의 연속된 메모리 공간으로 간주함.
하지만 코드, 데이터, 스택 등을 모두 한 덩어리로 관리하는 방식은 비효율적이었고
서로 다른 성격의 데이터는 보호나 공유하는 요구치가 다르고
논리적 의미에 맞게 모듈, 함수, 배열 등을 나눌 수 없었기에 다른 방법이 필요했음.
그래서 등장한 해결책이 Segmentation임.
세그멘테이션은 메모리 관리를 더 "의미 있는 단위"로 하자는 아이디어에서 출발함.
즉, 메모리를 논리적 구조에 따라 나누는 방식임.
논리적으로 독립적인 단위로 메모리를 나눠서 관리하여 (code, data, stack, heap)
위 문제들을 해결할 수 있게 됨.
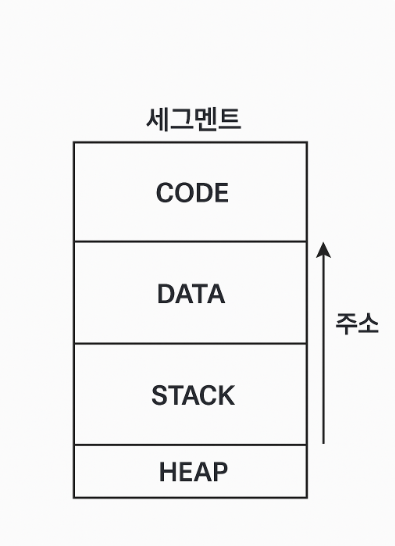
📌 구조 예시 (세그먼트 종류)
Code Segment: 프로그램의 실행 코드
Data Segment: 전역 변수 등 정적인 데이터
Stack Segment: 함수 호출/지역 변수 저장
Heap Segment: 동적 메모리 할당 공간
✅ 세그멘테이션의 동작 방식
각 세그먼트는 독립된 주소 공간을 가짐.
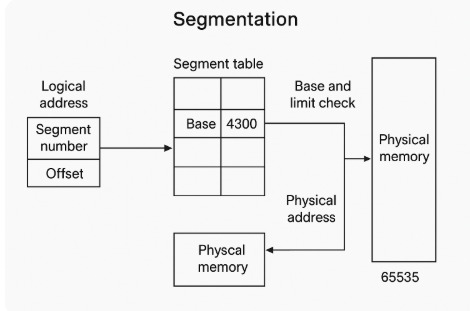
CPU가 접근하는 주소는 (세그먼트 번호, 오프셋) 형태.
OS는 세그먼트 테이블을 통해:
세그먼트의 기본 주소(base) 와 크기(limit) 를 기억하고
오프셋이 limit를 초과하지 않도록 경계 보호(boundary check) 를 수행.
✅ 단점: 외부 단편화 발생
📌 외부 단편화란?
가변 크기의 세그먼트를 할당/해제하면서 빈 공간이 연속되지 않은 채 흩어지는 현상.
📌 세그멘테이션에서 왜 생기나?
세그먼트는 고정된 크기가 아니라 크기가 제각각이기 때문.
예: 100KB, 300KB, 500KB 세그먼트가 메모리에 남았지만, 400KB 세그먼트는 못 들어감.
그래서!
페이징 기법이 나오며 이러한 문제를 개선하기 시작함.
하지만 페이징 기법도 완벽한 것은 아니게 된 것이... 마지막 페이지가 설정했던 페이지 크기보다 작을 경우 내부 단편화가 발생함.
📌 내부 단편화란?
페이지 내부의 사용 공간이 낭비되는 현상.
예: 페이지 크기가 4KB인데, 실제로는 3.3KB만 사용하는 경우 0.7KB 낭비
그래서 혼합 기법을 사용함으로서 이러한 문제를 해결함.
세그먼트는 논리 단위로 관리하고, 각 세그먼트를 다시 페이징하여 내부·외부 단편화를 동시에 해결.
예: 코드 세그먼트, 데이터 세그먼트를 페이지 단위로 나누어 배치.
세그먼테이션 + 페이징
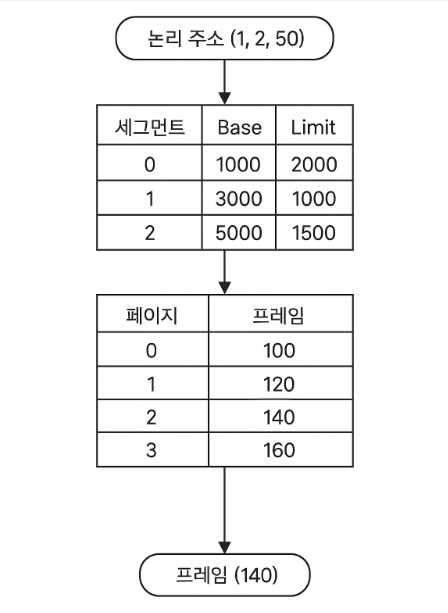
- 논리 주소 구성
[세그먼트 번호] + [페이지 번호] + [페이지 오프셋]
세그먼트 번호: 의미 단위 (예: 코드, 데이터, 스택)
페이지 번호: 해당 세그먼트 내에서의 페이지
오프셋: 해당 페이지 내의 실제 위치
-
세그먼트 테이블 접근
cpu가 논리 주소를 접근할 때, 먼저 세그먼트 번호를 이용하여 세그먼트 테이블을 조회한다.
세그먼트 테이블에는 각 세그먼트의 기준 주소(base)와 크기(limit) 또는 해당 세그먼트의 페이지 테이블의 위치가 저장되어 있다.
해당 과정으로 세그먼트의 페이지 테이블 주소를 얻는다. -
페이지 테이블 접근
세그먼트 내 페이지 번호를 이용하여 해당 페이지 테이블에서 프레임 번호를 얻는다.
페이지 테이블은 해당 세그먼트의 각 페이지가 물리 메모리의 어느 프레임(frame) 에 저장되어 있는지 알려준다.
- 물리 주소 계산
마지막으로 페이지 테이블에서 얻은 프레임 번호와 오프셋을 더하여 물리 주소(Physical Address) 를 구성합니다.
Physical Address = Frame base address + Offset
✅ 장점
세그멘테이션의 논리적 의미 단위 관리 장점 유지
페이징의 외부 단편화 해결 장점 반영
유연한 메모리 관리 가능
✅ 단점
하드웨어 구현이 복잡해짐 (2단계 테이블 접근 필요)
주소 변환 속도 느려질 수 있음 → TLB(Translation Lookaside Buffer) 등의 캐시 기법 필요