교착상태와 텍스트 데이터 분석 방법(feat. python)

네이버 AI부트캠프 2차 시험을 봤었다..
4솔은 했지만 일반전형이어서 합격의 확률은 낮아보인다..ㅋㅋ
결과에 상관없이!!! 프로토콜캠프나 SW마에스트로등 다양한 도전을 바로 해보려고한다
해보자 시도도 안하고 노력도 안하고 운을 바라지 말자!!
교착상태
일어나지 않을 일을 기다리면서 멈춰버리는 것!
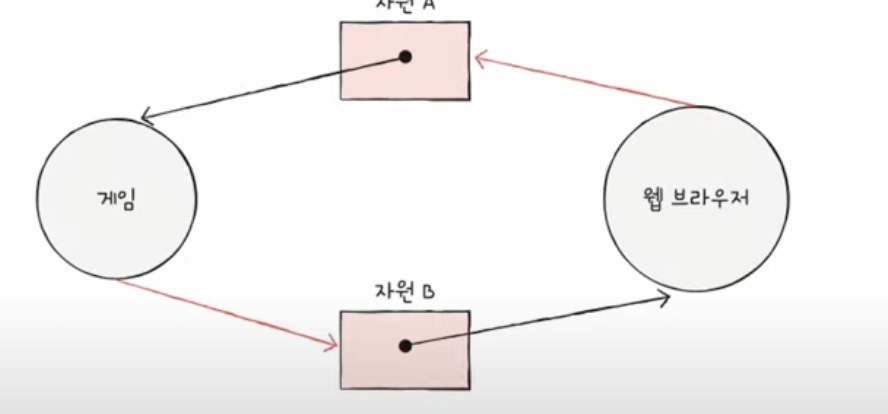
EX) Game과 Web이 각자 자원을 가지고 있고 상대방의 자원을 기다리느라
무한 대기에 빠지는 상황!
교착상태 발생하면 어떻게 해야할까?
- 당연한 말이지만 정확한 상황을 파악하기
이건 어떤 프로세스가 무슨 자원을 할당받았고 기다리는지 자원 할당 그래프 를 그려보자!
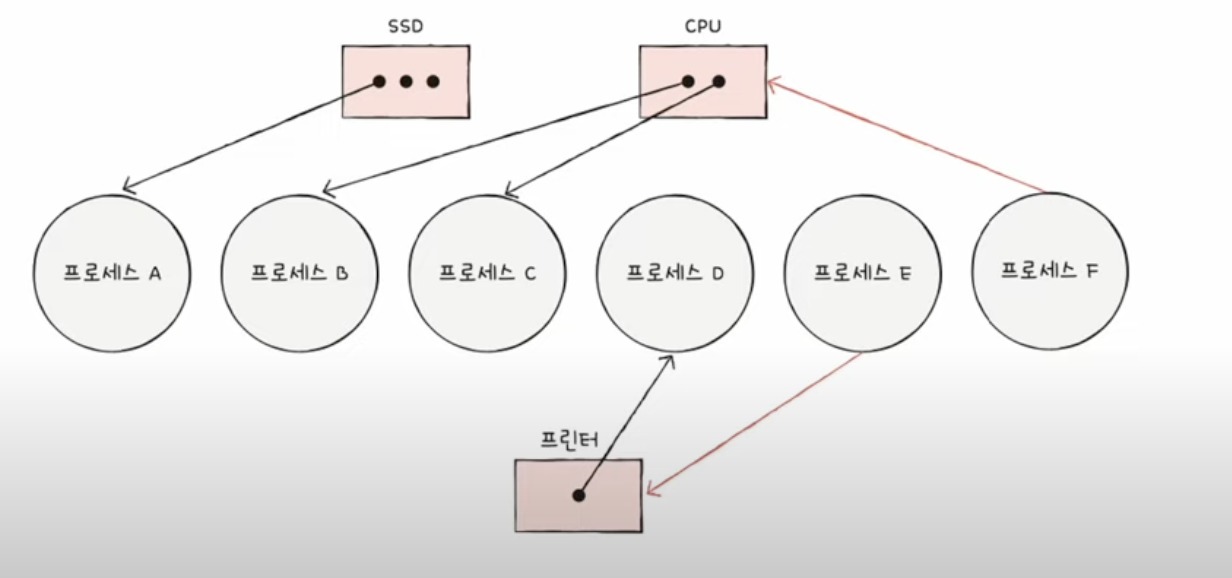
자원안에 .은 사용가능한 자원의 개수를 간단히 표현한 것이다
- 근본적인 이유 이해하기 => 이건 바로 아래 적겠다
교착상태 일어나는 이유
4사지 상태를 전부 만족하면 교착상태가 발생한다
하나라도 조건 만족 안하면 발생 안함!상호배제 - 한 프로세스가 사용하는 자원을 다른 프로세스가 사용 불가능
점유와 대기 - 자원 할당 받은 상태에서 다른 자원 기다리는 중
비선점 - 어떤 프로세스도 다른 프로세스 사용중인 자원 못 뺐는거
원형대기 - 프로세스들이 원형으로 대기
교착상태 해결 방법 - 완벽한 해결은 없다
예방, 회피, 검출 후 회복이 있다
예방 - 4가지 중 하나만 안되도 교착 안되니까 하나라도 조건 없애보기!
-
상호배제 없애면? => 모든 자원을 공유, 이건 이론적임
-
점유와 대기 없애면? => 특정 프로세스에 몰빵하거나 자원 아에 안주는 방식 - 효율 떨어짐
-
비선점 조건을 없애면? => 다른 프로세스 자원 뺏기는 CPU등만 가능, 모든 자원이 선점 가능이 아님
-
원형대기 조건을 없애면? => 모든 자원에 번호를 붙이고 번호의 오름차순대로 할당 -> 번호 붙이는거부터 문제
회피 - 교착상태를 무분별한 자원할당으로 인해 발생했다고 간주
-
안전 순서열을 만들어서 안전 상태인지 불안전 상태인지 체크!
-
안전상태는 교착 안일어남!
-
불안전 상태는 교착 일어남!
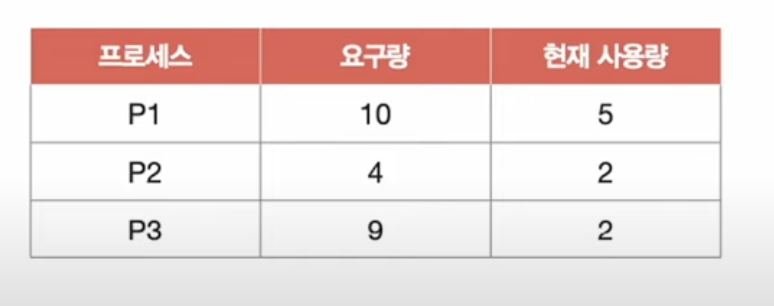
최악의 상황을 가정해서 불안전 상태인지 확인할 수 있다
안전상태에서 안전상태로 움직이는 경우에만 자원을 할당!!
프로세스는 작업이 끝나면 자원을 반납한다!!
회복 -교착 상태 인정 후 사후에 조치
선점을 통한 회복,(교착 상태 해결될때까지 몰빵)
프로세스 강제 종료를 통한 회복 (교착상태 프로세스 모두 종료-작업 다잃음, 하나씩 종료- 오베헤드 발생)
텍스트 데이터 분석 방법
사이트 ->TheBook
더 북이라는 사이트에서 머신러닝과 파이썬에 대해 쉽게 적은 책이 있어서 이 책을 20일안에 3회독 해보려고 한다!

데이터과학이 갑자기 인기가 많아진 이유? - 빅데이터
데이터 과학은 빅데이터라는 용어의 등장으로 큰 이슈가 되었다
빅데이터 - 다양한 형태의 데이터가 빠른 속도로 대량 생산 되는 것 - 분석과 활용 중요!
빅데이터의 특징 - 3V(크기, 다양성, 속도)
-
크기(Volume)
활용 대상이 되는 데이터의 크기를 의미
1024기가 - 1테라(TB)
1024TB - 1페타(PB)
1024PB - 1엑사(EB)
1024EB - 1제타(ZB) -
다양성(variety)
CSV파일이나 관계형 데이터베이스처럼 구조화된 데이터, 행과열로 표현 => 정형 데이터
JSON형태의 반정형 데이터
그냥 비정형 데이터 - 이거 많음!! -
속도(Velocity)
빅데이터는 빠르게 생성됨 -> 실시간으로 수집하고 분석
데이터 마이닝과 그로스 해킹
데이터 과학을 이해하려면 기법과 도구에 대한 이해가 필요하다!
데이터 마이닝: 데이터에서 유의미한 트렌드와 패턴, 규칙을 발견하고자 데이터를 반 자동화 방법으로 탐색!
앞으로의 사건 예측과 알지 못했던 유용한 지식 알 수도 있다!!
Growth Hacking: 데이터를 기반으로 마케팅에 정량적으로 접근하고 의사 결정하는 것을 의미!
무엇보다 창의적인 접근이 중요하다! - 데이터를 다양한 시각에서 바라보기
텍스트 데이터 분석
jupyter 실행시키고 pip install mlxtend 설치
(데이터의 전처리, 분류, 군집등의 모델링 가능한 머신러신 기능 제공, sklearn도 있긴함)전세계 데이터는 대부분 비정형! - 텍스트 데이터의 경우 뉴스나 PDF등 다양한 형태로 있다!
텍스트 마이닝을 해서 정형화 하자!
EX) 뉴스에서 특정 단어들로 정형화 하기 -이런 텍스트 데이터를 문헌용어 행렬(DTM)이라고 함
크기 클수있다!
DTM의 값은 각 단어의 출현빈도를 사용하거나 가중치가 적용된 출현 빈도를 사용!
텍스트 마이닝의 절차
1단계: 텍스트 마이닝 대상이 되는 Corpus를 준비하기!
분석대상인 비정형 텍스트 데이터를 준비
문헌들의 집합을 코퍼스라고 함! 각 문헌들이 분리되어있어야 식별 가능하다!
2단계: 코퍼스에 대해 숫자나 문장 부호등을 제거하기
텍스트 마이닝은 다량의 문헌에서 대략적인 의미를 파악하기 위해 숫자와 부호를 제거!
3단계:불용어 제거하기
the,of, and나 한국어의 조사나 접속사 등을 제거 (stop words)
text의 20-30%를 차지하기 때문에 크기를 줄일 수가 있다
4단계: 어간 추출하기
단어의 어간 추출 및 찾기, users, user,usered는 user라는 의미가 있다!
열의 수 줄이기 가능 - 성능 향상!
5단계: DTM 생성하기
코퍼스에서 나타난 모든 단어를 행렬의 열로 배치 -> 빈도를 TF라고 함
행에는 문장을 적어줌!
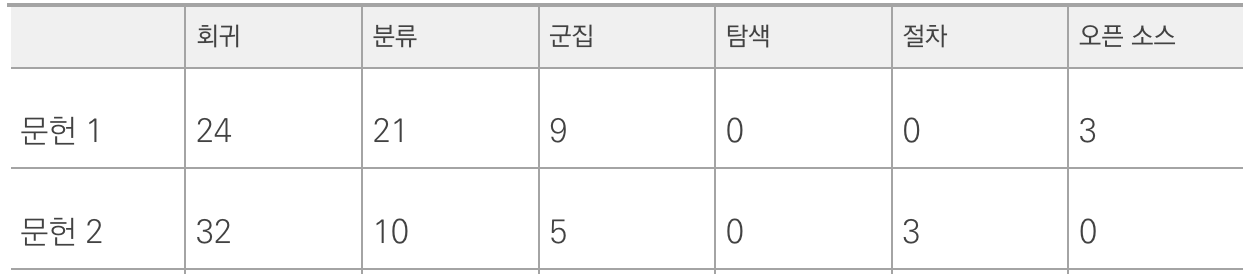
모든 문헌이 빈도가 많다고 무작정 좋은 정보는 아님! -> 정보의 중요도가 떨어짐!
셀프 피드백
확실히 AI부트캠프라는 목적의식이 없어지니 나태해진다
하지만 또 다른 단기 목표들을 만들어서 열정을 올려서!!
장기 목표인
올해 내 힘으로 500벌기
원하는 IT회사 취업하기를 꼭 성공시키자!!