네이버 부스트 코스 AI관련 부분을 제대로 공부 하고 싶어서
어느정도 코드 구현하는 연습을 해보고 들으면 좋겠다고 생각해서 듣게 되었다.
머신러닝 - 기계 학습
프로그램 작성하지 않고 컴퓨터가 스스로 학습하는 걸 의미
훈련 데이터를 통해 학습을 하고 모델을 만든다(함수를 만드는거!)
새로운 데이터를 넣었을때 예측하게 된다!
supervised learning 지도학습
- 문제와 정답 알려줌 -> 이걸 통해 모델을 생성
새로운 데이터 들어왔을때 답 추론하기 쉽다
Unsupervised Learning
- 정답 없다 -> 몇개의 그룹으로 나누게 함
-> 각 이미지들의 패턴을 찾아 볼때까지 하기
Reinforcement learning
- 정답 없지만 행동에 따라 보상이 있다
누적 보상을 최대화 하는 의사 결정
지도학습
회귀 Regression
2시간 - 22점
4시간 - 42점
6시간 - 58점
8시간 78점
10시간 100점
-> 9시간일때는 ?? => 그래프를 그려서 직선을 그린뒤 이 직선에 맞는 수가 예측됨변수들간의 상관관계를 찾는것
-> 연속적인 데이터로 결과를 예측
-> 숫자일때!
ex) 몸구게 , 스마트폰 가격, 근속연숙에 따른 임금
분류 Classification
각각의 영화에 좋아요 나빠요 적혀있다
감독,출연배우, 장르,국가 등에 따라 다양하게 결정됨
=> 여기서 코믹과 폭력석으로만 재미 결정하기!!
이 두가지로 그래프를 만듬
영화 G가 폭력성과 코믹성이 높은 그룹에 속한다면 -> 재미있는 영화!
주어진 데이터를 정해진 카테고리에 따라 분류
예측결과가 숫자가 아닐때 사용!!
ex) 스팸 메일인지 필터링, 시험 합격여부, 재활용 분리수거 품목, 악성종양 여부선형 회귀
공부시간 -> independent variable (원인), x 혹은 feature
시험 점수 - dependent variable(결과), y 혹은. target,label이라고 함
최적의 직선은 어떻게? -> 점에서 선까지의 거리를 구하기!
실제값과 예측값 차이의 제곱의 합을 최소화!
sum(y - y1) ** 2
y = mx + b 형태임 -> m은 기울지 b는 y절편공부시간과 성적에 대한 선형회귀 코드
여기서는 Jupyter Notebook을 사용해서 코드를 썼다.
!pip install scikit-learn --user --upgrade
# sklearn 버전 업데이트!-> 버전 오류 방지 위해
import matplotlib.pyplot as plt # 데이터 시각화
import pandas as pd # 데이터 가공
from sklearn.linear_model import LinearRegression
dataset = pd.read_csv('LinearRegressionData.csv')
dataset.head()
# 5개의 row 데이터를 먼저 읽어봄으로써 정확하게 들어갔는지 확인
X= dataset.iloc[:,:-1].values #전체 row에 column은 맨 처음꺼만
Y = dataset.iloc[:,-1].values
# 전체 row에 대해서 마지막 column만
reg = LinearRegression()
reg.fit(X,Y)
y_pred = reg.predict(x) # x에대한 예측값
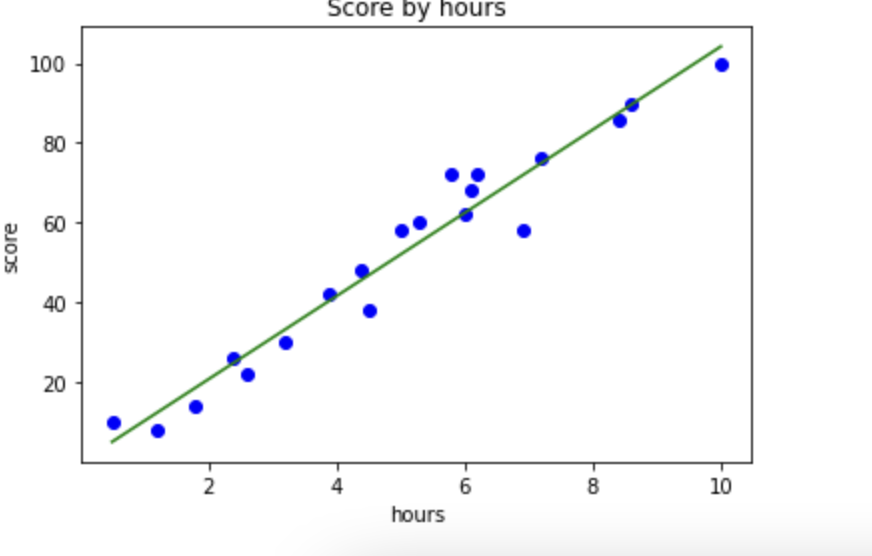
plt.scatter(X,Y,color='blue') # 점으로 표현
plt.plot(X,y_pred, color='green') # 선으로 표현
plt.title('Score by hours')#제목
plt.xlabel('hours')
plt.ylabel('score')
plt.show()
reg.coef_ # 기울기 (m)
reg.intercept_ # y절편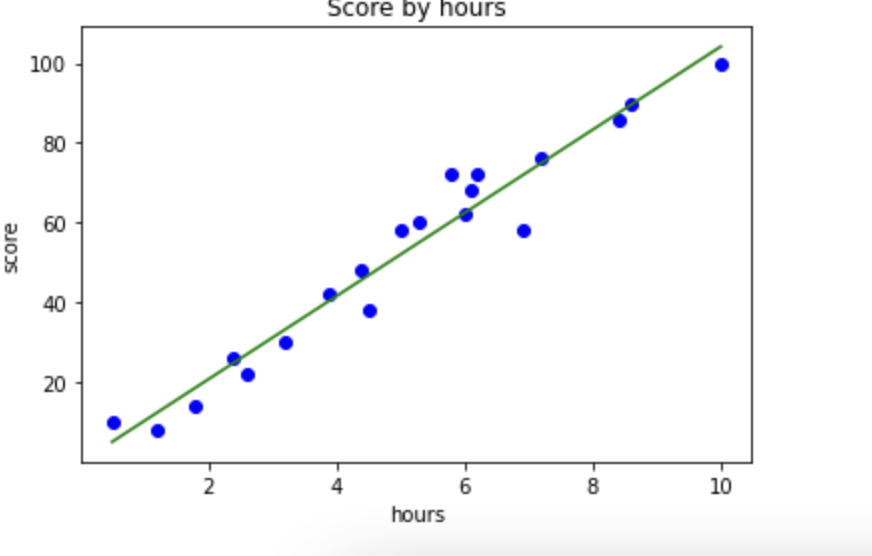
간략한 정보
fit에서
- X는 반드시 2차원 데이터 셋 ex) pandas의 DataFrame, 파이썬의 2차원 list
- y는 반드시 1차원 데이터 셋 ex)pandas의 Series, 파이썬의 1차원 list
iloc => integer location의 약어로, 컴퓨터가 읽을 수 있는 indexing 값으로 데이터에 접근하는 것이다.
sum(실제y값 - 예측값)^2 이 최소가 되게 만드는 것을 학습이라고 한다
SW로 문제를 해결하려는 열정만 있는 대학생