Set Interface
Set 인터페이스는 말 그대로 집합의 개념이다. 기본적으로 순서를 정렬하지 않으며 중복된 값을 저장하지 않는다. 가장 많이 사용하는 HashSet과 TreeSet에 대해 정리해보았다.
HashSet
HashSet 은 Set 인터페이스를 구현한 가장 대표적인 컬렉션으로 Set 인터페이스의 특징대로 중복된 요소를 저장하지 않는다. 이미 저장되어 있는 요소와 동일한 요소를 add 하면 false 를 반환하므로 이미 저장되어 있던 값인지도 확인할 수 있다.
public boolean add(E e)
Adds the specified element to this set if it is not already present. More formally, adds the specified element e to this set if this set contains no element e2 such that Objects.equals(e, e2). If this set already contains the element, the call leaves the set unchanged and returns false.
int 와 같이 기본 값은 제대로 중복 제거가 되지만 새로 추가한 클래스는 모든 인스턴스 변수의 값이 동일해도 중복 제거가 안된다. HashSet 에서 동일한 값이라고 판단하는 기준은 equals 와 hashCode 이기 때문이다.
import java.util.*;
class HashSetEx3 {
public static void main(String[] args) {
HashSet set = new HashSet();
set.add("abc");
set.add("abc");
set.add(new Person("David",10));
set.add(new Person("David",10));
System.out.println(set);
}
}
class Person {
String name;
int age;
Person(String name, int age) {
this.name = name;
this.age = age;
}
public String toString() {
return name +":"+ age;
}
}실행 결과
[abc, David:10, David:10]해당 예시에서 이름과 나이가 같으면 동일인물이라고 알려주기 위해 equals 와 hashCode 를 재정의해줘야 한다.
import java.util.*;
class HashSetEx4 {
public static void main(String[] args) {
HashSet set = new HashSet();
set.add(new String("abc"));
set.add(new String("abc"));
set.add(new Person2("David",10));
set.add(new Person2("David",10));
System.out.println(set);
}
}
class Person2 {
String name;
int age;
Person2(String name, int age) {
this.name = name;
this.age = age;
}
public boolean equals(Object obj) {
if(obj instanceof Person2) {
Person2 tmp = (Person2)obj;
return name.equals(tmp.name) && age==tmp.age;
}
return false;
}
public int hashCode() {
return (name+age).hashCode();
}
public String toString() {
return name +":"+ age;
}
}동일한 객체라고 알려주기 위한 기준대로 재정의해주면 그 기준에 맞춰 중복 요소가 제거된다.
HashSet 은 저장된 순서를 보장하지 않고 자체적인 저장방식에 따라 순서가 결정된다. 저장한 순서대로 값을 저장하고 싶으면 LinkedHashSet 을 사용한다.
TreeSet
TreeSet 은 이진 검색 트리라는 자료구조의 형태로 데이터를 저장하는 컬렉션 클래스이다. Set 인터페이스로 구현했으므로 중복된 데이터의 저장을 허용하지 않으며 정렬된 위치에 저장하므로 저장 순서를 유지하지 않는다.
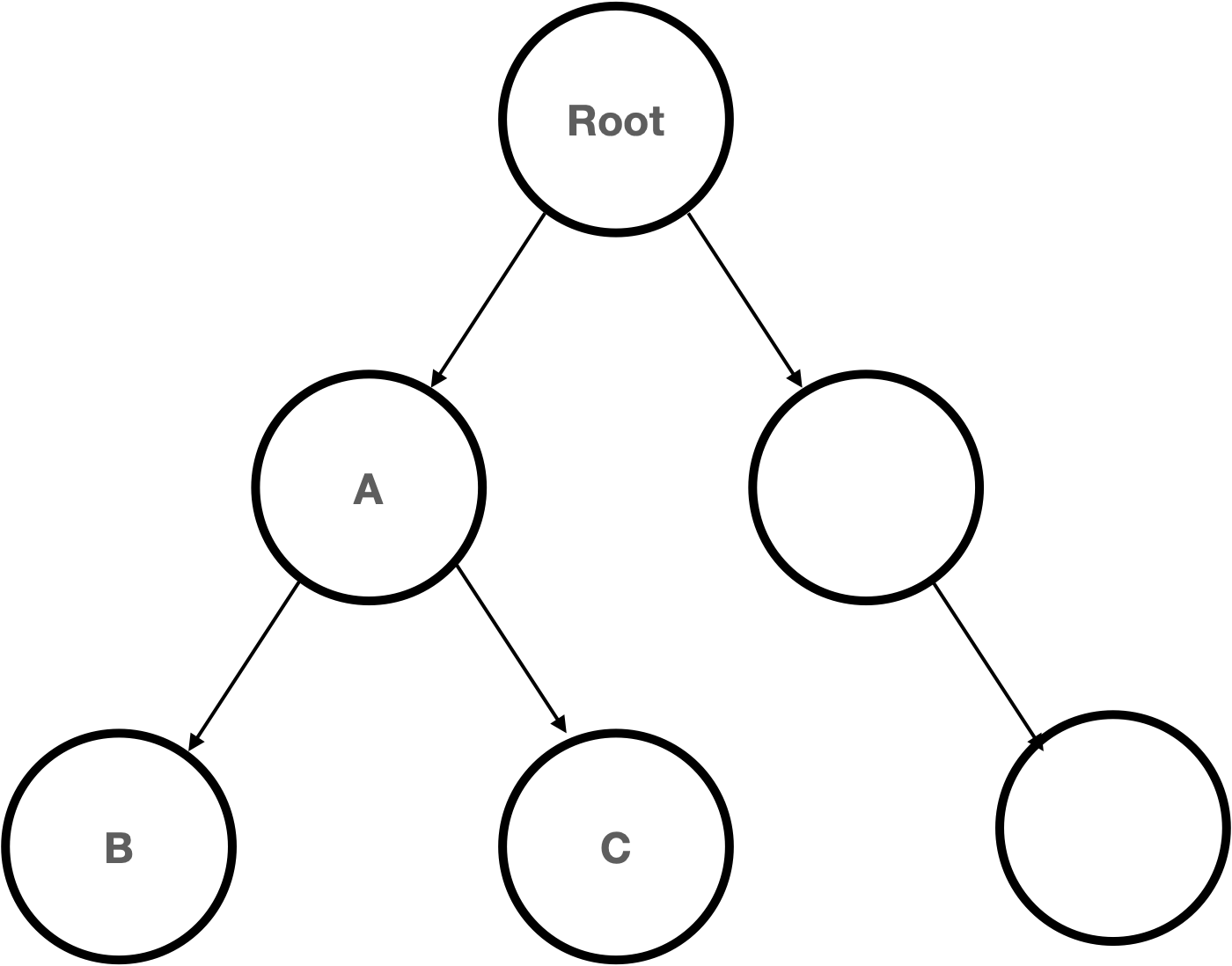
이진 검색 트리란 하나의 노드가 두개의 자식 노드를 가질 수 있는 구조를 말한다. 코드로 표현하면 다음과 같다.
class TreeNode {
TreeNode left; // 왼쪽 자식노드
Object element ; // 객체를 저장하기 위한 참조변수
TreeNode right; // 오른쪽 자식노드
}값이 추가되어 정렬 시 현재 노드를 기준으로 값이 더 작으면 왼쪽 자식노드에, 값이 더 크면 오른쪽 자식노드에 위치시킨다. 값의 크고 작음의 기준을 정하기 위해 Comparable 의 compareTo 는 필수로 오버라이딩 해주어야 한다. 오버라이딩을 하지 않으면 TreeSet 에 객체를 저장할 때 예외가 발생한다.
import java.util.*;
class TreeSetLotto {
public static void main(String[] args) {
Set set = new TreeSet();
for (int i = 0; set.size() < 6 ; i++) {
int num = (int)(Math.random()*45) + 1;
set.add(num); // set.add(new Integer(num));
}
System.out.println(set);
}
}TreeSet 은 compareTo 에 정의된 기준대로 정렬 순서를 보장하므로 값을 add 시킨 것 만으로도 정렬된 순서대로 값이 저장된다.
