Array vs List
둘은 상당히 비슷한 특징을 가지고 있다. 데이터를 순서대로 저장 할 수 있고, 중복해서 저장할 수도있다. Array는 index위치가 중요하다. List는 내부적으론 index를 가지고 있을 순 있지만 그 보다 중요한건 데이터가 저장되어있는 순서가 더 중요하게 여겨지는 데이터 타입이라고 볼 수 있다.
데이터 입력
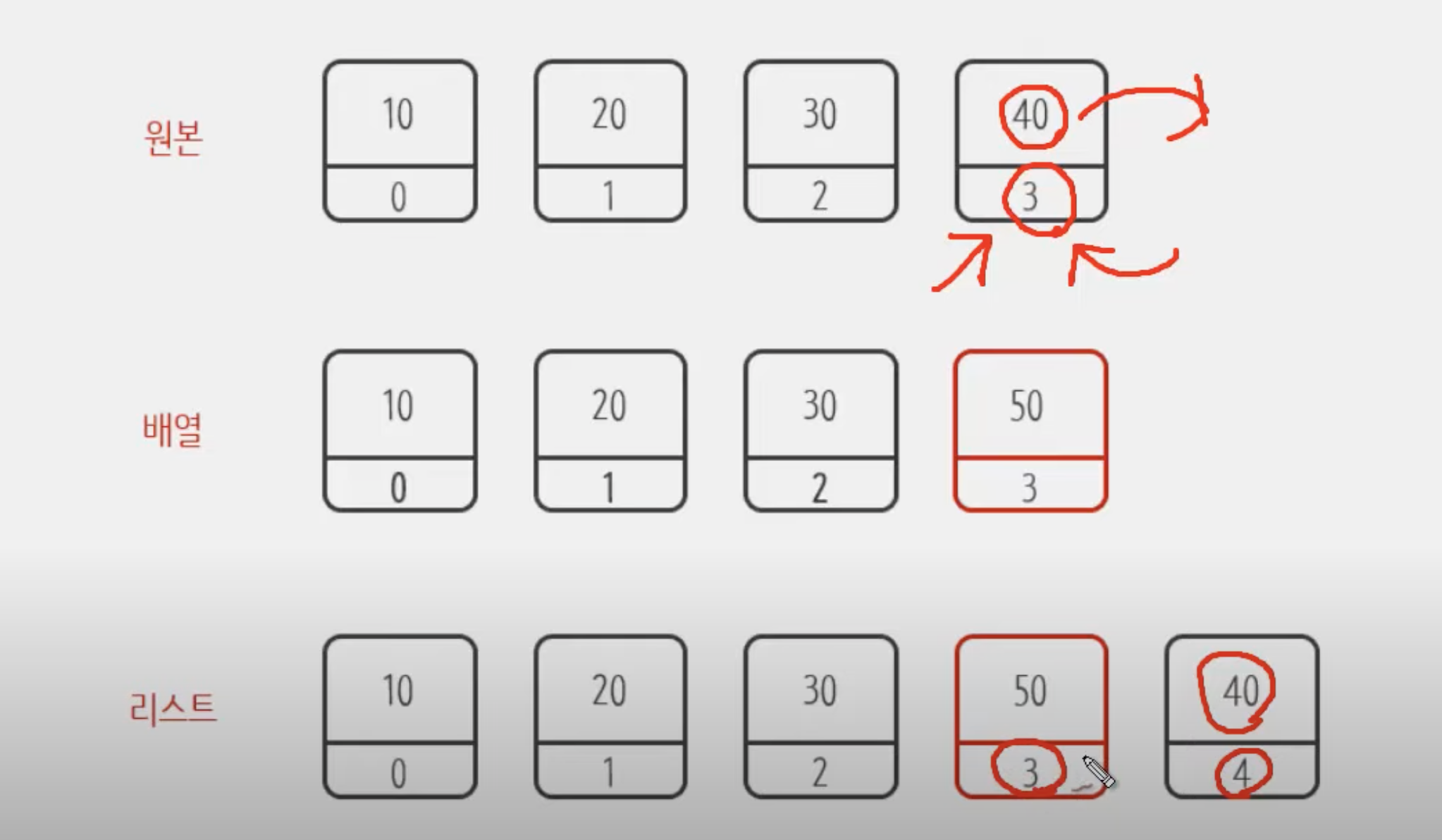
사진 출처 : 생활코딩
그림에서 보는것처럼 Array는 3번 index에 있는 값이 사라지면서 그자리에 50이 들어가는걸 확인할 수 있고 List는 3번 index에 값 40이 4번 index로 밀려나는걸 확인 할 수 있다.
데이터 삭제
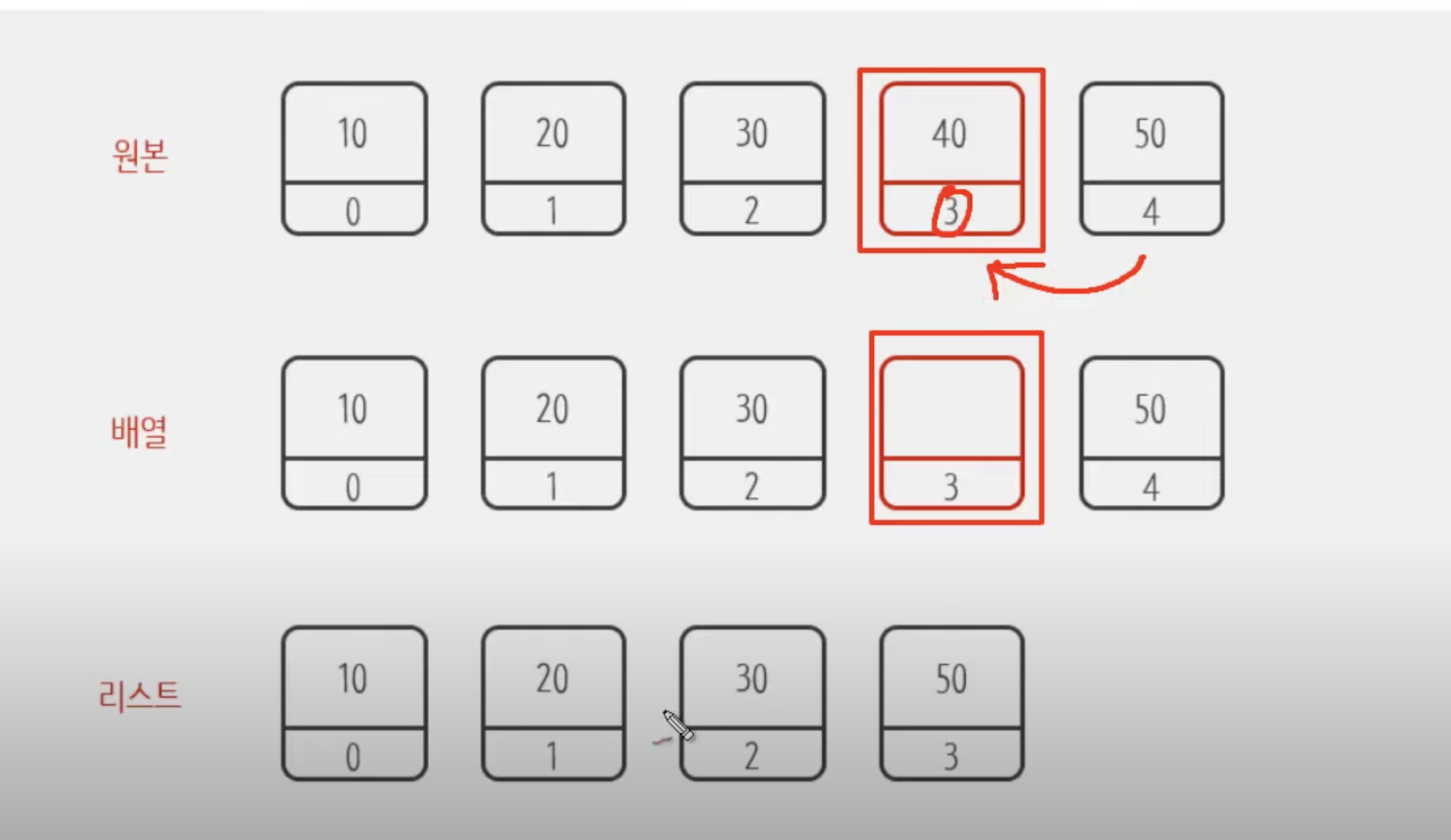
사진 출처 : 생활코딩
Array는 값이 삭제되어 있는 채로 있지만(메모리를 더 차지함) List는 4번 index에 있던 값이 3번 index로 들어오는것을 확인할 수 있다.
List 특징
- 처음, 끝, 중간에 엘리먼트를 추가/삭제하는 기능
- 동작할 때 추가하면 그 이후에 있었던 데이터는 밀리고, 삭제하면 빈공간이 체워진다.
- 리스트에 모든 데이터가 접근할 수 있음
- C언어는 List를 지원하지 않음(직접 만들거나, 다른사람이 만든것을 사용가능해야함)
- JavaScript에서는 배열이 리스트이기도 함
- Python에서는 배열을 지원하지않고 리스트를 지원함 -> 리스트가 배열이기도 함(pop)
- 결론 : 최근에 언어는 리스트를 기본적으로 지원한다.
<자바에서의 배열과 리스트 사용>
int[]numbers = {10,20,30,40,50}
ArrayList numbers = new ArrayList();
numbers.add(10);
numbers.remove(0);
LinkedList vs ArrayList

트레이드오프가 존재함
Array 특징
가장 기본적인 자료구조인 Array 자료구조는, 논리적 저장 순서와 물리적 저장 순서가 일치한다. 따라서 인덱스(index)로 해당 원소(element)에 접근할 수 있다. 그렇기 때문에 찾고자 하는 원소의 인덱스 값을 알고 있으면 Big-O(1)에 해당 원소로 접근할 수 있다. 즉 random access 가 가능하다는 장점이 있는 것이다.
하지만 삭제 또는 삽입의 과정에서는 해당 원소에 접근하여 작업을 완료한 뒤(O(1)), 또 한 가지의 작업을 추가적으로 해줘야 하기 때문에, 시간이 더 걸린다. 만약 배열의 원소 중 어느 원소를 삭제했다고 했을 때, 배열의 연속적인 특징이 깨지게 된다. 즉 빈 공간이 생기는 것이다. 따라서 삭제한 원소보다 큰 인덱스를 갖는 원소들을 shift해줘야 하는 비용(cost)이 발생하고 이 경우의 시간 복잡도는 O(n)가 된다. 그렇기 때문에 Array 자료구조에서 삭제 기능에 대한 time complexity 의 worst case 는 O(n)이 된다.
삽입의 경우도 마찬가지이다. 만약 첫번째 자리에 새로운 원소를 추가하고자 한다면 모든 원소들의 인덱스를 1 씩 shift 해줘야 하므로 이 경우도 O(n)의 시간을 요구하게 된다.
(출처 : https://github.com/JaeYeopHan/Interview_Question_for_Beginner/tree/master/DataStructure)
LinkedList 특징
이 부분에 대한 문제점을 해결하기 위한 자료구조가 linked list 이다. 각각의 원소들은 자기 자신 다음에 어떤 원소인지만을 기억하고 있다. 따라서 이 부분만 다른 값으로 바꿔주면 삭제와 삽입을 O(1) 만에 해결할 수 있는 것이다.
하지만 Linked List 역시 한 가지 문제가 있다. 원하는 위치에 삽입을 하고자 하면 원하는 위치를 Search 과정에 있어서 첫번째 원소부터 다 확인해봐야 한다는 것이다. Array 와는 달리 논리적 저장 순서와 물리적 저장 순서가 일치하지 않기 때문이다. 이것은 일단 삽입하고 정렬하는 것과 마찬가지이다. 이 과정 때문에, 어떠한 원소를 삭제 또는 추가하고자 했을 때, 그 원소를 찾기 위해서 O(n)의 시간이 추가적으로 발생하게 된다.
결국 linked list 자료구조는 search 에도 O(n)의 time complexity 를 갖고, 삽입, 삭제에 대해서도 O(n)의 time complexity 를 갖는다. 그렇다고 해서 아주 쓸모없는 자료구조는 아니기에, 우리가 학습하는 것이다. 이 Linked List 는 Tree 구조의 근간이 되는 자료구조이며, Tree 에서 사용되었을 때 그 유용성이 드러난다.
Personal Recommendation
Array 를 기반으로한 Linked List 구현
ArrayList 를 기반으로한 Linked List 구현
(출처:https://github.com/JaeYeopHan/Interview_Question_for_Beginner/tree/master/DataStructure)
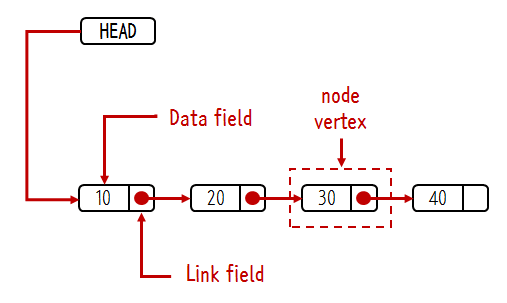
출처 : 생활코딩
Head는 백화점 출입문같은 역할
-
수도코드(처음에 값을 삽입)
Vertex temp = new Vertex(input)
temp.next = head
head = temp -
중간에 삽입
Vertex temp1 = head
while(--k!=0)
temp1 = temp1.next
Vertex temp2 = temp1.next
Vertex newVertex = new Vertex(input)//새로운 노드
temp1.next = newVertex
newVertex.next = temp2 -
삭제
Vertex cur = head
while(--k!=0)
cur = cur.next
Vertex tobedeleted = cur.next
cur.next = cur.next.next // 다음 삭제할 값을 알아야하기때문에 next->next로 연결상태에서 알아냄
delete tobedeleted //그다음 삭제 -
조회
순서대로 연결연결해서 찾아야하기 때문에 느리다.
ArrayList 추가 / 삭제 / 조회
데이터 추가
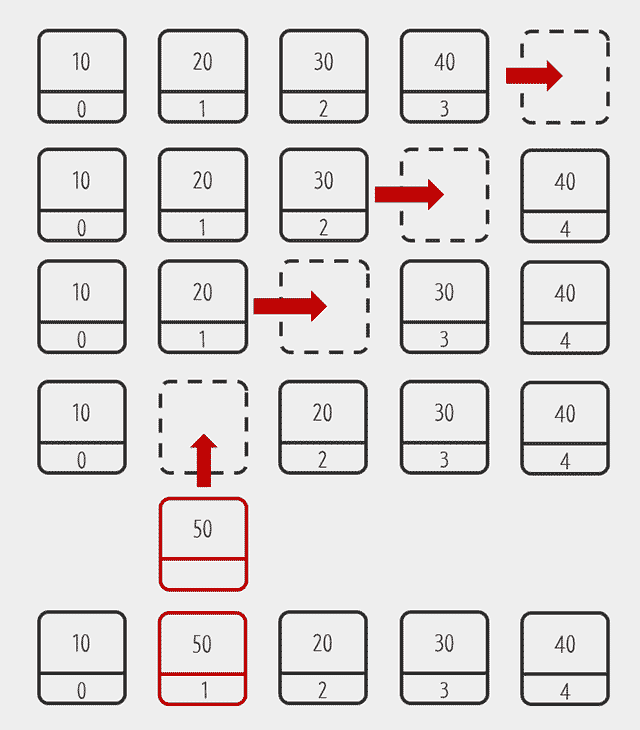
출처 : 생활코딩
Array List는 내부적으로 데이터를 배열에 저장합니다. 배열의 특성상 데이터를 리스트의 처음이나 중간에 저장하면 이후의 데이터들이 한칸씩 뒤로 물러나야 합니다.
ArrayList () numbers = new ArrayList<>();
numbers.add(10);
numbers.add(20);
numbers.add(30);
numbers.add(1,50); // 원하는 인덱스에 추가할 때
데이터 삭제
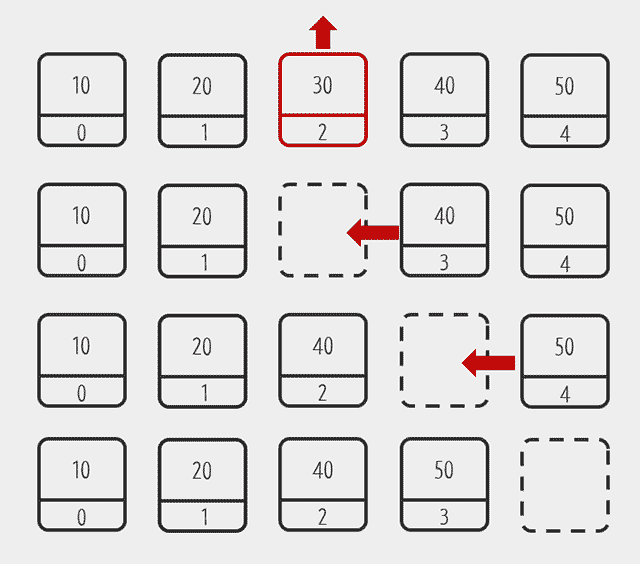
출처 : 생활코딩
삭제도 추가와 비슷합니다. 빈자리가 생기면 빈자리를 채우기 위해서 순차적으로 한칸씩 땡겨야 합니다.
numbers.remove(2);
데이터 조회
인덱스를 이용해서 데이터를 가져오고 싶을 때 Array로 구현한 리스트는 매우 빠릅니다. 메모리 상의 주소를 정확하게 참조해서 가져오기 때문입니다.
numbers.get(2);
데이터 사이즈
numbers.size();
Iterator 반복
Iterator it = numbers.iterator();
while(it.hasNext()){ // it변수에 다음 값이false일때까지 반복
int value = it.next(); // it 변수 0인덱스부터 value 에 넣고 다음 인덱스로 이동
}
for(int value : numbers){
System.out.println(value);
}
