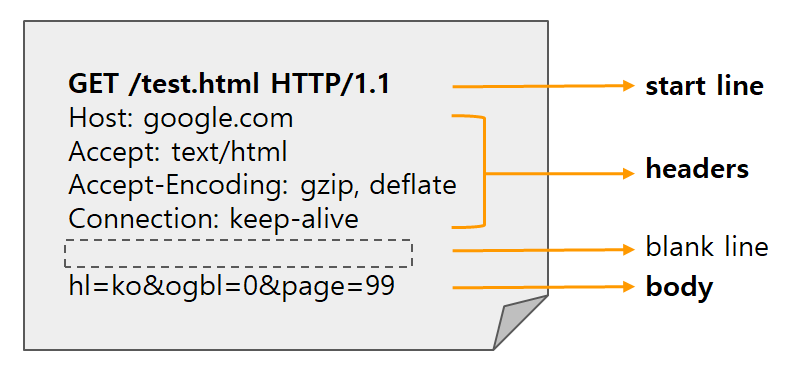
Http 1.1
RFC 2616 for HTTP 1.1에 따르면
HTTP 1.1의 HTTP Message는
generic-message = start-line
*(message-header CRLF)
CRLF
[ message-body ]
start-line = Request-Line | Status-Line이런 구조를 가지고 있다.
CRLF는 CR + LF로 \r\n으로 표현된다.
CR = <US-ASCII CR, carriage return (13)>
LF = <US-ASCII LF, linefeed (10)>따라서 CRLF CRLF 이렇게 연달아서 표시함으로써 request line과 request headers 영역 마침을 표시한다.
"GET /ugaeng/host HTTP/1.1
Host: localhost:8080
"
"GET /ugaeng/host HTTP/1.1\r\nHost: localhost:8080\r\n\r\n"
Java에서 RequestLine / Headers 읽기
이를 Java에서 읽으려면 BufferedReader를 사용하는 것이 편하다. readline 메서드가 \r\n or \n or \r단위로 read하기 때문에 CRLF CRLF를 만나면 read한 String은 empty string, ""가 될 것이다.
Reader (Char 다루기)가 아니라 InputStream (Byte 다루기)으로 읽겠다면
CRLF -> 13,10 임을 이용하면 된다. public void readRequest(Socket client) {
try (var reader = new BufferedReader(new InputStreamReader(client.getInputStream()))) {
// Request Line
final String requestLine = reader.readLine();
// Requset Headers
final Map<String, String> requestHeaders = new HashMap<>();
String line = null;
while (hasText(line = reader.readLine())) { // hasText, check null or empty
// parse line //
// line, "headerName: headerValue\r\n" //
requestHeaders.put(headerName, headerValue);
}
}
}Http Message Body
Http 메시지 구조에 따르면 CRLF CRLF 뒤에는 message body가 입력되게 된다.
그러면
message body는bufferedreader의readline != null인 동안에 --> Request Message의EOF까지 읽으면 되는 것일까??
아쉽게도 아니다.
실제로 Java로 읽는 경우 CRLF CRLF이후 계속 readline을 하게 된다면 마지막에 blocking에 걸리게 된다.
Http Request Message에는 EOF가 존재하지 않는다고 한다.
내 생각에는 http는 `요청-응답` 구조이기 때문에 프로토콜 입장에서 `
요청`, `응답`을 따로 구분해서 진행하기 보다 `요청-응답`을 같은
file(`socket`) 단위로 취급하는 것 같다.
++ 추가로 조사해보니, `client - server` 간 연결의 지속성을 위한 것이라고 한다.
`Connection : keep-alive`그렇다면 bufferedReader를 이용해서 message body를 모두 읽을 수 있는 방법은 무엇이 있을까?
Content-Length
Http의 이러한 연결 지향적인 속성 때문에 Content-Length 헤더를 통해 message body를 어디까지 읽으면 되는지 지정해준다고 한다.
POST http://localhost:8080/ugaeng/host
Content-Length: 29
{
"domainName" : "ugaeng"
}다음과 같이 message body의 "byte 수"를 전달해줌으로써 http request를 읽기를 마칠 수 있다.
Java에서 Http message body 읽기
그러면 Java에서 BufferedReader를 통해 원하는 byte길이 만큼 읽어와보자.
int contentLength = Integer.parseInt(requestHeaders.get("Content-Length"));
char[] bodyChars = new char[contentLength];
reader.read(bodyChars, 0, contentLength);자세히 보면 byte[]가 아니라 char[]로 읽어왔다. java에서는 Reader는 char 단위를 읽는다. (byte 단위는 InputStream)
ASCII vs UNICODE
Java에서는 문자를 byte단위가 아닌 char 단위로 다룬다.
byte- 1 byteschar- 2 bytes
이는 Unicode때문인데, 알파벳의 경우 Ascii code, 1bytes로 충분히 표현이 가능하지만, 알파벳 이외의 여러 문자를 지원하게 됨으로써 더 많은 저장 공간인 Unicode, 2bytes로 표현하게 됨으로써 char타입을 2 bytes로 채택하게 된 것이다.
message body에 기존 ascii code에 존재하는 문자만 있을 경우는 문제가 되지 않지만, 한글처럼 unicode로 표현되는 문자는 byte로 표현하게 되면
UNICODE Bytes
--------------------------
a 0x61
--------------------------
가 0xea 0xb0 0x80 3개의 byte로 표현된다.
UTF-8과 같은 더 자세한 내용은 더 공부해야한다..
어쨋든 char[]로 읽어오게 되는데, Content-Length는 "byte 수"를 표시한다고 했다.
따라서 message body에 한글이 포함되게 되면 read하는 과정에서 Content-Length에 표시된 길이보다 더 많이 읽어오게 된다.
bytes 길이를 chars 길이로 치고 read했기 때문에...
고로
chars에는{'안', '녕', 0, 0, 0, 0}이런식으로 저장될 것이고, 불필요한 데이터를 담고 있게 된다.
따라서 마지막에 String.trim()을 호출해주자~
public String readMessageBody(Socket client) {
try (var reader = new BufferedReader(new InputStreamReader(client.getInputStream()))) {
int contentLength = Integer.parseInt(requestHeaders.get("Content-Length"));
char[] bodyChars = new char[contentLength];
reader.read(bodyChars, 0, contentLength);
return new String(bodyChars).trim(); // {'안', '녕'}
}
}