AWS 환경에서 HLS 변환
진행 중인 프로젝트에서 클라이언트가 업로드 할 영상을 HLS프로토콜로 변환하는 프로세스를 만들었다.
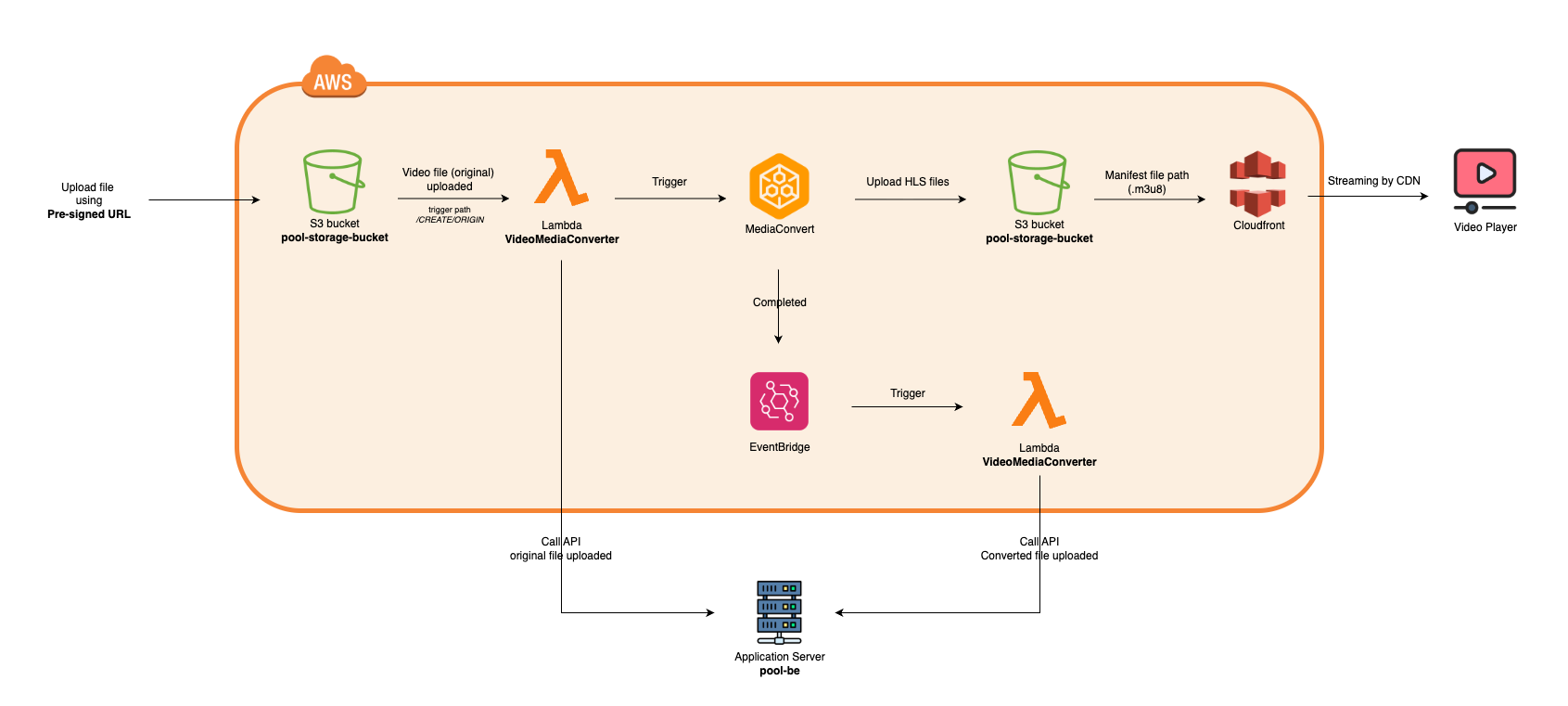
처음 구상했던 프로세스는 다음과 같다.
- Pre-signed URL 발급 (파일 태그에 생성된 file uuid 포함)
- 1의 URL을 통해 업로드 (AWS S3
/video/origin경로에 업로드)VideoMediaConverterLambda 함수 트리거 (/video/origin경로 한정)- 영상 파일 정보가 AWS MediaConvert로 넘어가 HLS 변환 후 S3에 업로드
- AWS EventBridge에서 MediaConvert의
Job Complete이벤트를 수신 후HLSFileManifestSaverLambda 함수 트리거- HLS 변환된 영상들의 메타정보가 백엔드 서버로 전송 (HTTP POST)
- 백엔드 서버에서 원본 파일 - HLS 변환 파일 메타정보 저장
그림으로 보자면
그런데 이 방식에 문제가 있다.
문제 상황
영상을 업로드하는 클라이언트는 HLS 변환 완료 여부를 알 수가 없다. 그 이유는
- Pre-signed URL을 이용해 원본 파일을 업로드하기에, 클라이언트의 동기화는 원본 업로드까지.
- AWS 에코시스템 내부에서 이벤트들이 트리거돼다 보니 외부에서 이를 알 수가 없다.
결국 백엔드 서버로 컨텐츠(영상이 포함된 데이터) 생성 API를 계속 보낼 수 밖에 없다. (위의 7번 과정이 완료될 때까지...) -> Polling 구조
우리 백엔드 서버의 스펙은 AWS free tier이기 때문에 Polling구조는 가장 피해야할 상황으로 팀원들간에 의견이 모아졌다.
Polling 구조 개선
Polling 구조를 개선하기 위해 Message Queue (빠른 개발을 위해 Redis pubsub 사용)를 도입하기로 했다.
기존과 달라진 점은
1 ~ 6 동일
7. 백엔드 서버에서 HLS 변환 파일 저장 완료되면, 람다에서file-id채널에 해당 정보 메시지 발행
8. 클라이언트는 원본 영상 업로드 후file-id채널 구독해 메타정보 메시지를 받음으로써 변환 완료 인지
그림으로 나타내면 아래와 같다.
추가 개선점
이 방식으로 Polling 구조를 개선할 수 있었지만, Message Queue라는 추가적인 리소스가 필요하다. 이는 결국 free tier를 쓰는 이유인 비용에 대한 같은 문제로 귀결된다.
현재는 임시로 외부 호스트에 Redis instance를 실행했지만, 서비스 관리 범위 밖이기 때문에 추가 개선이 필요하다.
조사한 바로는 두 가지 후보가 있고, 간단한 특징은
| Server Sent Event | WebSocket | |
|---|---|---|
| 방향 | 서버 -> 클라이언트 단방향 | 서버 <-> 클라이언트 양방향 |
| 프로토콜 | Http/Https | ws/wss (Http기반이기는 함) |
| 주요 용도 | 비동기 데이터 전송 (알림, 실시간 업데이트 등) | 실시간 양방향 통신 (채팅, 온라인 게임 등) |
| 서버 리소스 | 비교적 가벼움. 기존 HTTP 연결을 재사용하여 오버헤드가 적음 | 상대적으로 무거움. 항상 연결을 유지하고 양방향 통신을 처리해야 하므로 리소스 소모가 큼. |
| 데이터 타입 | 텍스트 데이터 only | 텍스트, 바이너리 데이터 |
이렇게 정리할 수가 있다. 두 방식의 특징과 우리 서비스의 특징을 고려했을 때 Server Sent Event가 적합하다고 생각한다.
좀 더 여유가 생기면 SSE로 다시 개선해봐야겠다...
Gemini 피드백 봇 리뷰
안녕하세요! 10년 차 백엔드 개발자 시니어 멘토입니다. MQ를 활용한 아키텍처 개선에 대한 글 잘 읽어보았습니다.
Polling 문제를 발견하고 이를 해결하기 위해 아키텍처를 개선하는 과정과 다이어그램 설명이 매우 인상적입니다! 특히 단순히 문제를 해결하는 것을 넘어 SSE와 WebSocket을 비교하며 추가 개선점까지 고민하는 모습에서 주니어의 성장이 느껴져 정말 뿌듯하네요. 기존에 작성하셨던 Kafka 포스트와도 자연스럽게 내용이 이어져서, Redis Pub/Sub을 선택한 이유를 간략히 추가하면 기술 선택의 깊이를 더 잘 보여줄 수 있을 것 같습니다. 전체적으로 복잡한 비동기 처리 과정을 체계적으로 설명하는 능력이 돋보이는 훌륭한 글이며, 꾸준히 발전하는 모습이 정말 보기 좋습니다!