
1. 웹 크롤링 & 스크래핑 개요
크롤링이란
크롤링
- 웹에서 데이터를 수집하는 작업
- 크롤러 또는 스파이더라는 프로그램으로 웹 사이트에서 데이터를 추출
웹 API
- 웹 API는 일반적으로 HTTP 통신을 사용하는데 사용
- 지도, 검색, 주가, 환율 등 다양한 정보를 가지고 있는 웹 사이트의 기능을 외부에서 쉽게 사용할 수 있도록 사용 절차와 규약을 정의한 것

웹 스크래핑(Web scraping)
- 웹 페이지 상에서 원하는 콘텐츠 정보를 컴퓨터로 하여금 자동으로 추출하여 수집하도록 하는 기술
- 웹 페이지를 구성하고 있는 HTML 태그의 콘텐츠나 속성의 값을 읽어오는 작업
웹 크롤링(web crawling)
- 자동화 봇(bot)인 웹 크롤러(web crawler)가 정해진 규칙에 따라 복수 개의 웹
페이지를 브라우징하는 작업
Python의 웹 스크래핑 라이브러리
- BeautifulSoup
- Scrapy
- selenium
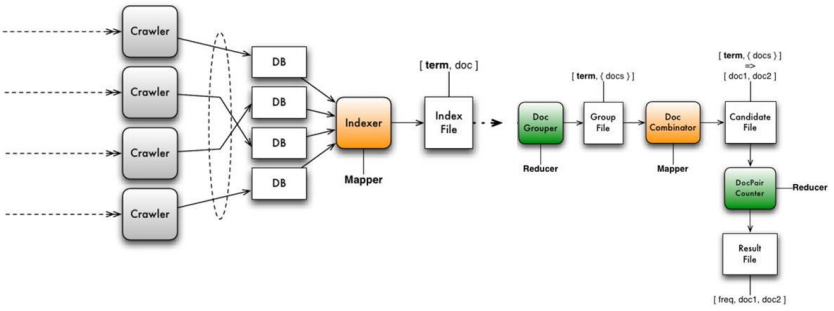
빅데이터의 수집, 분석, 시각화 과정
- Fetching : 인터넷 상에 산재해있는 데이터를 수집하기 위해 크롤러(Crawler) 구성
- Storing : 수집한 정보는 데이터 베이스 또는 HDFS(Hadoop File System)에 저장
- 인덱싱(Indexind) : 저장된 데이터는 검색의 효율성을 높이기 위하여 인덱싱(Indexing) 과정을 거침
- Data Mart : 데이터를 가공하여 축약된 정보 DB(Mart DB)를 생성.
- 시각화(Visualization) : 정보를 사용자에게 효율적으로 보여주기 위해 시각화(Visualizatino) 과정을 거쳐 인포그래픽(Infographic-정보를 포함한 그래픽)으로 최종적으로 생성해 내는 것
Crawling 저작권
- 모든 사용자에게 허용되고 /인 주소만 허용한다는 의미


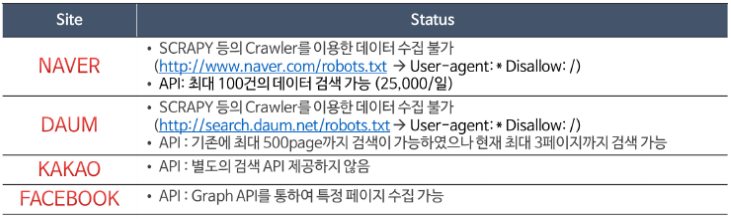
Portal/SNS 별 Crawling 방법 및 한계
- “robots.txt” 파일 : 무분별한 인터넷 데이터의 사용을 금지하기 위하여 웹 규약에서는 해당 사이트의 크롤링 범위를 정의하는 “robots.txt” 파일을 서비스 웹 서비스의 root에 저장하도록 되어 있다.
- 예 : http://www.naver.com/robots.txt 에 웹 브리우저를 이용하여 접근해 보면 네이버의 크롤러 접근 규칙에 대해 확인이 가능
SNS API(Application Programming Interface)
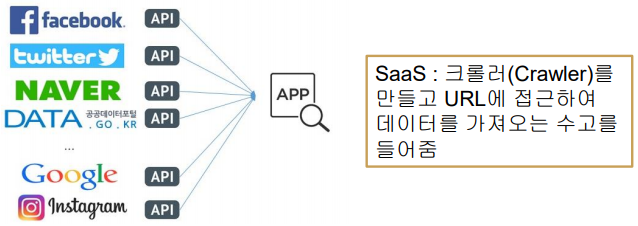
SaaS(Software as a Service)
- 소프트웨어 및 관련 데이터가 중앙에 위치하고 사용자는 웹 브라우저등을 이용하여
접속하여 소프트웨어를 사용하는 서비스 모델- 페이스북이나 트위터는 자신들이 서비스하는 여러 가지 기능을 SaaS의 개념으로 다른 사용자들이 활용할 수 있는 API(Application Programming Interface)를 제공
2. 웹페이지 구성 기술
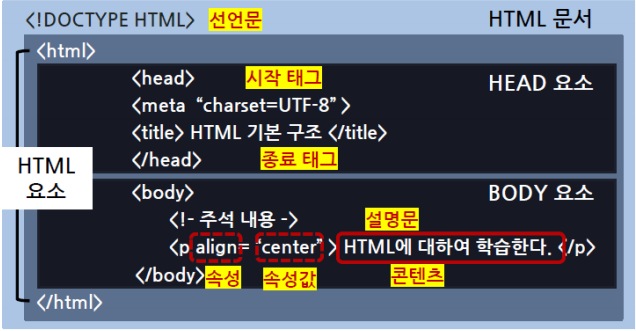
HTML(HyperText Markup Language)
- 웹 페이지를 만들 때 사용하는 마크업 언어 → 태그를 사용해서 내용 작성
- 전체적으로 <html> 태그로 감싸 짐
- 문서의 정보를 제공하는 <head> 태그와 브라우저에 렌더링되는 내용을
작성하는 <body> 태그로 구성HTML 구성 요소
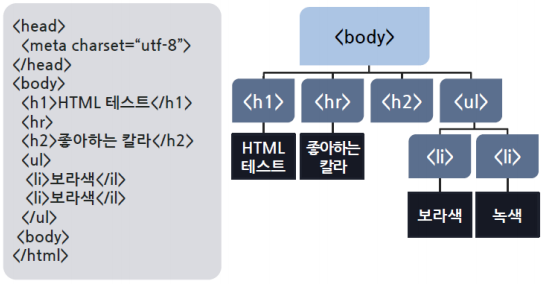
- 브라우저가 HTML 문서를 파싱하여 브라우저의 도큐먼트 영역에 렌더링할 때 HTML 문서를 구성하는 모든 태그와 속성, 콘텐츠들을 DOM(Document Object Model)이라는 규격을 적용하여 JavaScript 객체 생성
- HTML 문서의 내용으로 구성되는 DOM 객체들은 HTML 문서 그대로 계층구조를 이룸

CSS(Cascade Style Sheet)
- HTML과 같은 마크업 언어가 브라우저에 표시되는 방법을 기술하는 언어
- HTML과 XHTML에 주로 사용되는 W3C의 표준
CSS 사용의 이점
- 웹 표준에 기반한 웹 사이트 개발 가능(페이지의 내용과 디자인 분리)
- 클라이언트 기기에 알맞는 반응형 웹 페이지 개발 가능
- 이미지의 사용을 최소화시켜 가벼운 웹 페이지 개발 가능


CSS 선택자
태그 선택자
- 태그명으로 태그를 선택하려는 경우로 태그명을 그대로 사용
클래스선택자
- 태그에정의된class 속성의값으로태그를선택하려는경우로. 과함께작성
id 선택자
- 태그에정의된id 속성의값으로태그를선택하려는경우로#과함께작성
자식 선택자
- 지정된 부모 태그의 자식 태그에만 스타일이 적용
자손 선택자
- 지정된 부모 태그의 자식 태그에만 스타일이 적용
속성선택자







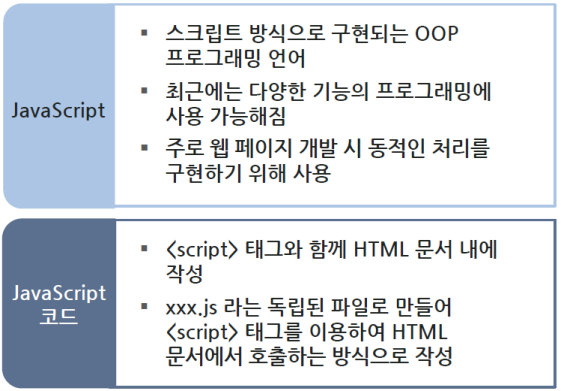
JavaScript
- 웹 크롤링을 할때는 크롤링하려는 콘텐츠 부분이 정적으로 만들어진 것인지
JavaScript에 의해서 동적으로 만들어지는 것인지부터 파악

Ajax
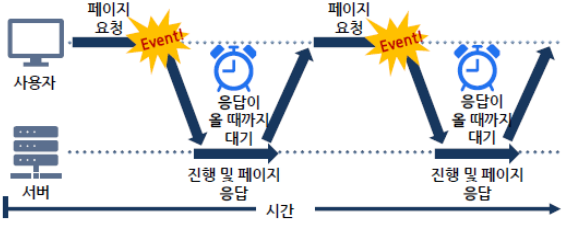
전통적 웹 통신 방법
- 동기 통신으로 서버에 요청할 때마다 응답이 올 때까지 대기
- 서버에 요청을 할때마다 브라우저에 보여지고 있는 끝난 현재 페이지는
지워짐- 페이지의 일부분만 변경하려는 경우에도 전체 페이지 내용을 요청하여
받아와야 함
- Asynchronous JavaScript and XML의약어
- JavaScript 코드로 서버와 통신하는 기술
- 통신방식을 비동기적으로 처리하여 요청하고나서 대기하지 않고 다른작업
을 처리할 수 있음- 전체페이지가 아닌 필요한 일부분만 요청하여 받아올 수 있는 통신
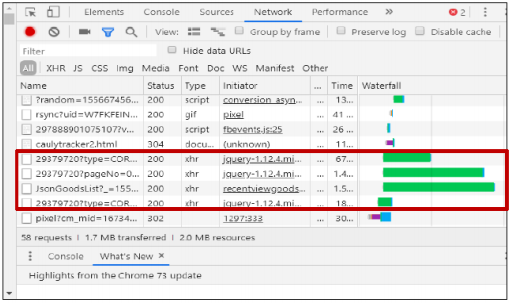
Ajax 기술을 사용한 페이지 확인 방법
- 전체 페이지를 리로드(Refresh)하지 않고 보여지고 있는 현재페이지내
에 서버로부터 받아온 내용을 자연스럽게 추가할 수 있음- 필요한 만큼의 일부 데이터만 요청하여 받아 빠르게 동적 웹페이지 생성
- 데이터 전송량이 중요한 모바일웹과 최근 많이 활용되는 SPA(Single
Page Application)에서 더욱 중요해진 통신 기술
3. 웹 콘텐츠 요청
웹 콘텐츠 요청 방법
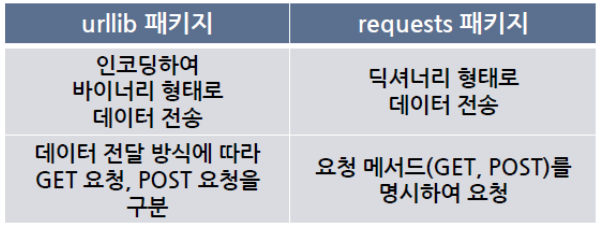
- urllib 패키지를 활용한 웹페이지 요청
- requests 패키지를 활용한 웹페이지 요청
주요 모듈 활용
- urllib.request—URL 문자열을 가지고 요청 기능 제공
- urllib.response—urllib모듈에 의해 사용되는 응답 클래스들 제공
- urllib.parse—URL 문자열을 파싱하여 해석하는 기능 제공
- urllib.error—urllib.request에 의해 발생하는 예외 클래스들 제공
- urllib.robotparser—robots.txt 파일을 구문 분석하는 기능 제공
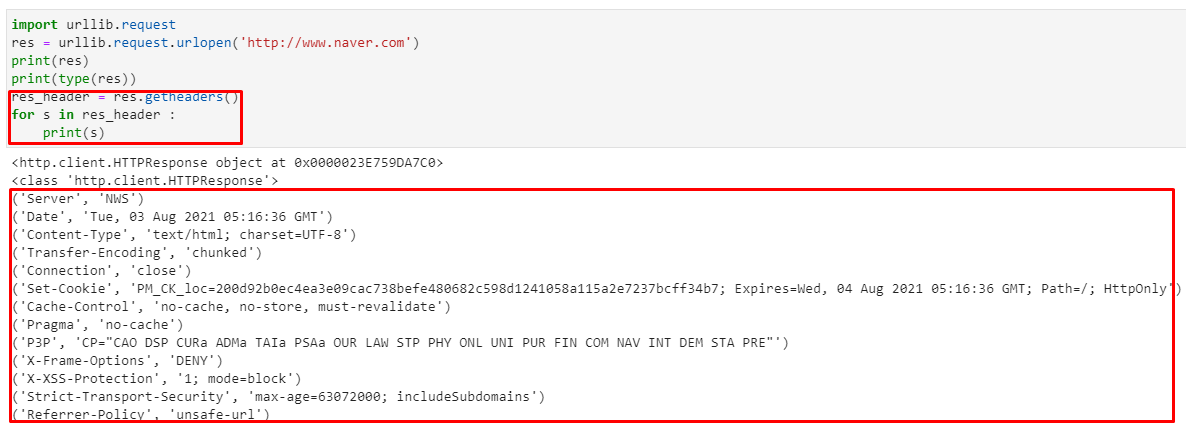
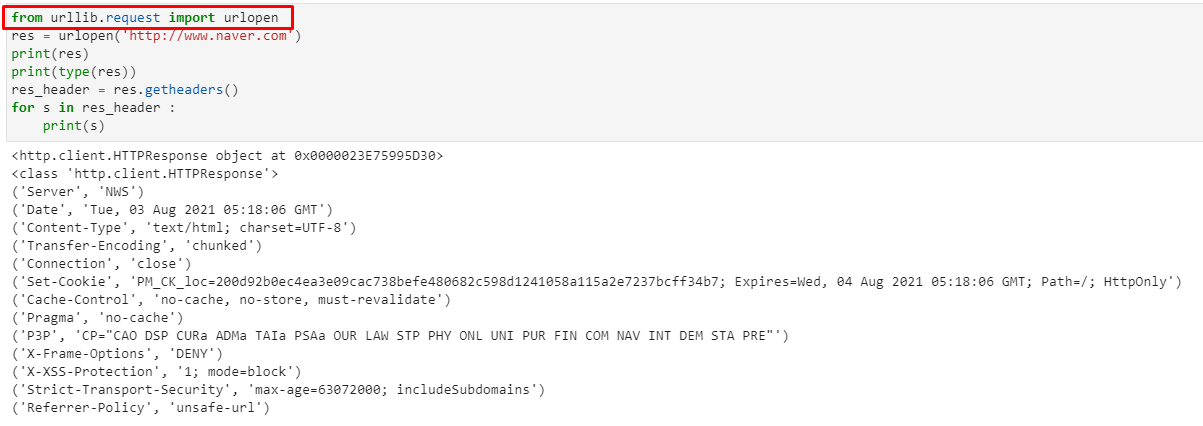
urllib.request모듈
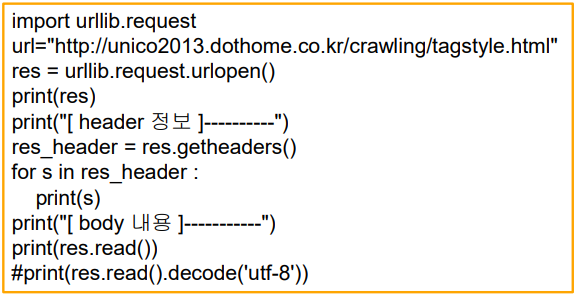
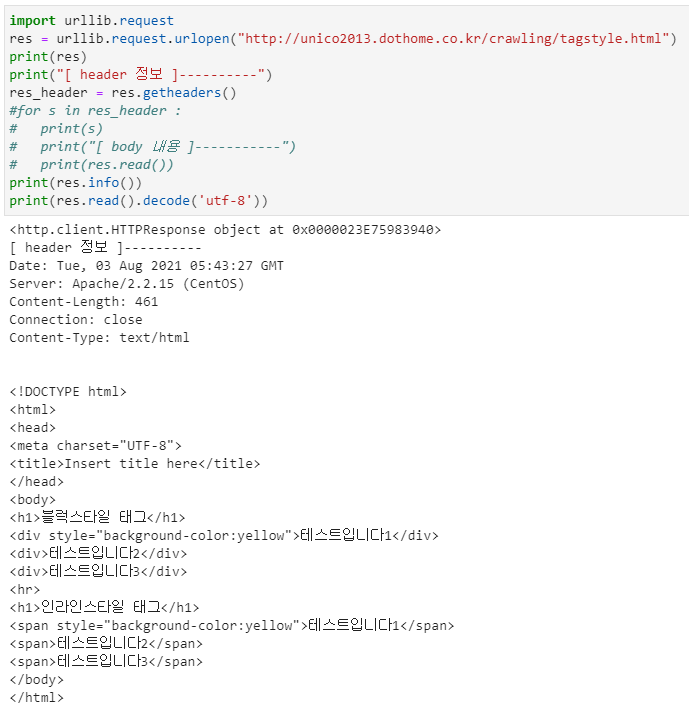
http.client.HTTPResponse 객체의read() 메서드





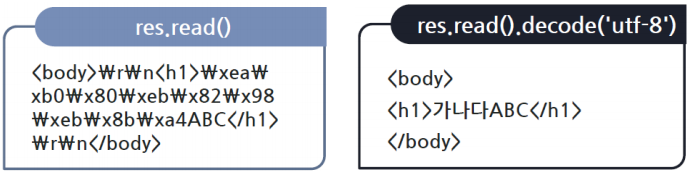
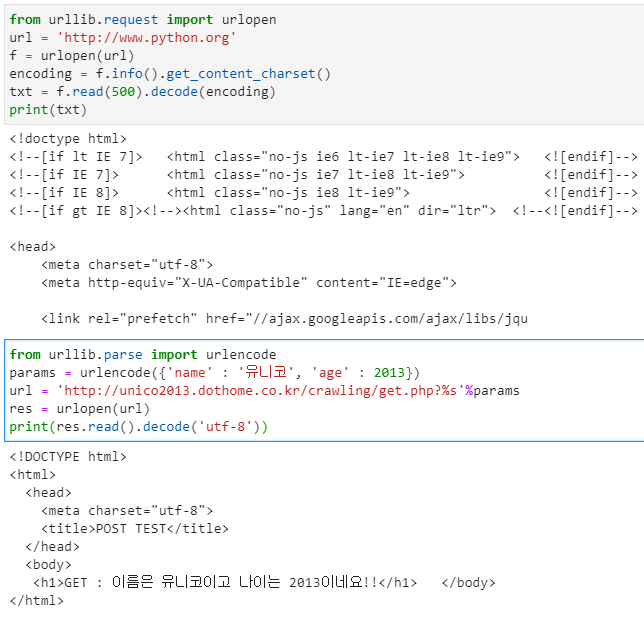
decode() 함수 실습
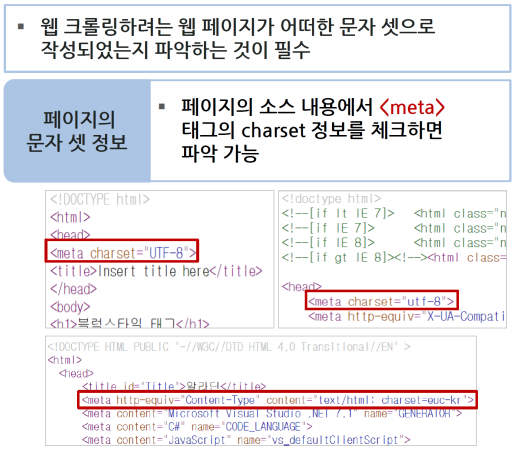
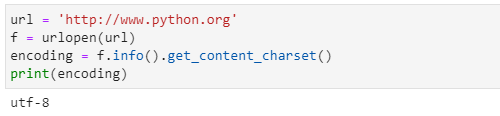
웹페이지 인코딩 체크
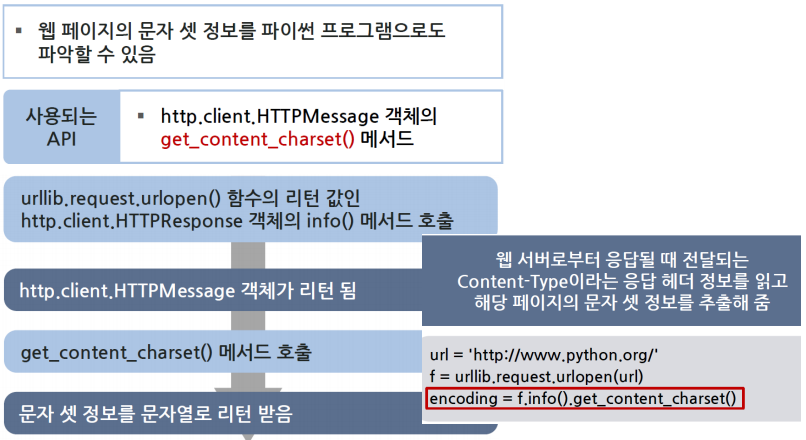
get_content_charset()

urllib.parse 모듈

urllib.parse 모듈-urlparse() 함수
- urllib.parse.urlparse("URL문자열”)
- 아규먼트에 지정된 URL 문자열의 정보를 파싱하고 각각의 정보를 정해진 속성으로 저장하여 urllib.parse.ParseResult 객체를 리턴함
- 각 속성들을 이용하여 필요한 정보만 추출할 수 있음

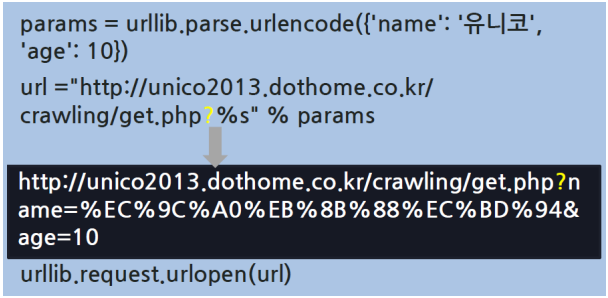
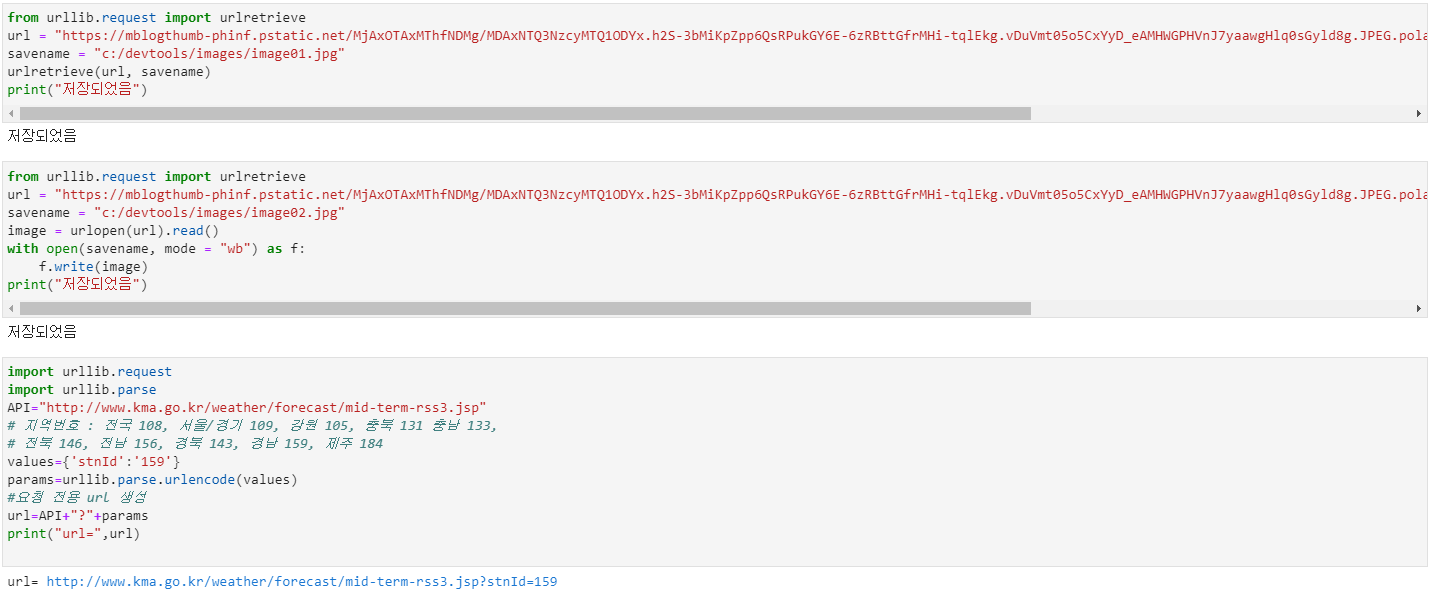
urllib.parse 모듈-urlencode() 함수
- urllib.parse.urlencode()
- 메서드의 아규먼트로 지정된 name과 value로 구성된 딕셔너리정보를 정해진
규격의 Query 문자열 또는 요청 파라미터 문자열로 리턴 함

Query 문자열을 포함하여 요청
- Query 문자열을 포함하여 요청하는 것 → GET 방식 요청
- urllib.parse.urlencode 함수로 name과 value로 구성되는 Query 문자열을
만듦
- URL 문자열의 뒤에‘?’ 기호를 추가하여요청 URL로 사용

requests 패키지란?
- 아나콘다에는 requests 패키지가 site-packages로 설치되어 있음
- pipenv명령으로 설치 가능

requests 패키지소개- requests.request() 함수
- requests 패키지의 대표 함수
- HTTP 요청을 서버에 보내고 응답을 받아오는 기능 지원

HTTP 요청 방식을 지원하는 함수
- requests.request() 함수 외에 각각의 요청방식에 따른 메서드들도 제공
- requests.request() 함수에 요청방식을 지정하여 호출하는 것과 동일
- HTTP 프로토콜에서 정의한 GET, POST, HEAD, PUT, PATCH, DELETE 등의 요청 방식을 처리하는 메서드들을 모두 지원
- GET, HEAD, POST만 학습


GET 방식요청
- GET 방식 요청은 다음 두 가지 함수 중 하나를 호출하여 처리 가능
- Query 문자열을 포함하여 요청: params 매개변수에 딕셔너리, 튜플리스트, 바이트열(bytes) 형식으로 전달
- Query 문자열을 포함하지 않는 요청: params 매개변수의 설정 생략

POST 방식 요청
- POST 방식 요청은 다음 두 가지 함수 중 하나를 호출하여 처리 가능

응답처리

실습
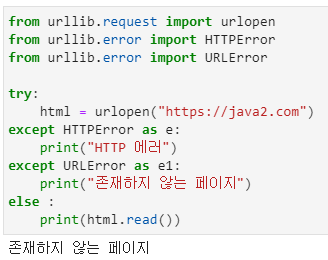
- import가 먼저 와도 되고, from이 먼저 와도 됨
- try-catch문 사용 방법


Nil Desperandum <절대 절망하지 마라>