Intro
💡MLM Models
- 기존 BERT를 비롯한 다양한 MLM(Masked Language Model) 방법론들이 좋은 성과를 내고 있으나 이들은 주로 특정 end tasks에(prediction, generation, etc.) 치중되어 있다는 한계가 있습니다
- BART 또한 MLM 중 하나로 Bidirectional + Auto-Regressive Transformer 아키텍처를 사용하고 있습니다.
💡BART의 차별점
- Seq2Seq model 기반으로 discriminative task 뿐만 아니라 generative task에서도 높은 성능을 보입니다
- BERT의 bi-directional encoder와 GPT의 autoregressive decoder를 합친 형태입니다
- Pre-train step의 차별점
(1) Input text를 arbitrary noising function에 의해 변형시키고(corrupted)
(2) Seq2Seq model로 Input text를 복원 (Autoencoder)
-> (1)의 장점은 input data에 다양한 noise를 추가해줄 수 있다는 것입니다 (noising flexibility)
Model
BART는 denoising autoencoder로서 bi-directional encoder + left-to-right autoregressive decoder를 가진 seq2seq 모델입니다.

출처 : BART paper
💡Architecture
Input: noised textsoutput: original texts- Transformer :
Encoder+Decoder - Activation : GeLU (Gaussian error Linear Unit)
- GeLU function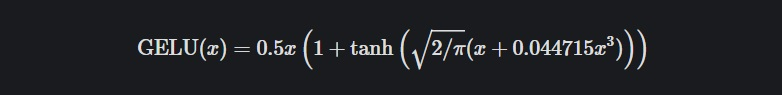
- function graph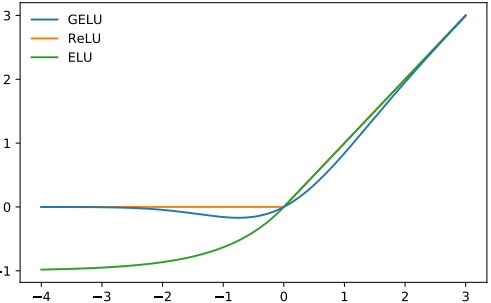
- Initialise parameters from N(0, 0.02)
- layer : Base model 6, large model 12
- BERT와의 차이점 (10% more params than BERT)
(1) encoder의 final hidden layer에 대해 각각의 decoder들은 추가적으로 cross-attention을 수행합니다 (Seq2Seq model)
(2) BERT는 word-prediction 이전에 Feed-forward network가 있지만 BART는 없습니다
Transformer decoder
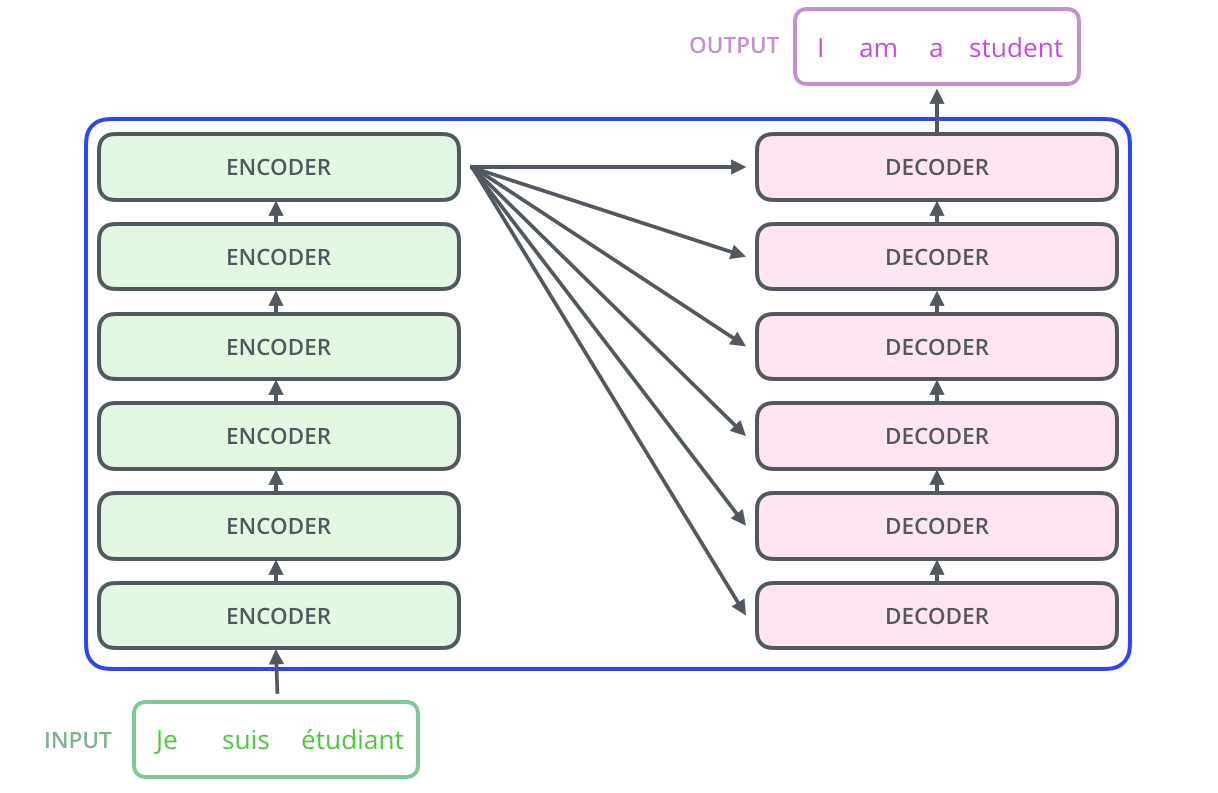 출처 : ilustrated transformer
출처 : ilustrated transformer
BERT Classifier
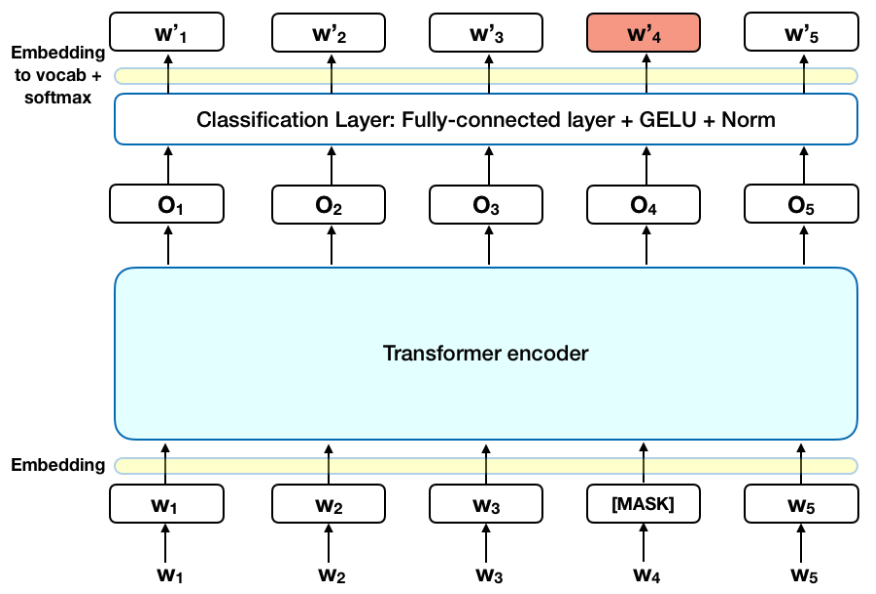 출처 : TowardsDataScience
출처 : TowardsDataScience
💡Pre-training BART
BART는 input sequence의 어떠한 형태의 변형 (corruption)도 가능합니다. BART 논문의 저자들은 다양한 변형을 시도해보고 최종적으로는 아래와 같은 방법론을 사용해 sequence를 변형시켰습니다.
- Token masking : BERT와 마찬가지로, 랜덤하게 선택된 토큰들을
[MASK]토큰으로 대체합니다 - Token deletion : 일부 토큰들은 랜덤하게 삭제됩니다. model은 어떤 위치의 토큰이 삭제되었는지 알아내도록 합니다.
- Text infilling : 텍스트를 메우는 (infilling) 태스크입니다. 정확히는
span(텍스트를 일정 범위로 나눈 것) 안에 누락된 텍스트들을 예측하는 태스크입니다. BART에서는 Poisson (lambda=3) 분포에서 span length를 샘플링해서 pre-train하였습니다. span length=0 일 경우[MASK]토큰을 사용합니다. - Sentence permutation : 문장을 마침표 (full stop) 단위로 permutation 합니다.
- Document rotation : 토큰을 uniformly choose 하고 document를 rotate해서 선택된 토큰이 문장의 시작점에 있도록 합니다. 이 태스크는 통해 모델은 document의 시작점을 알 수 있게 됩니다.
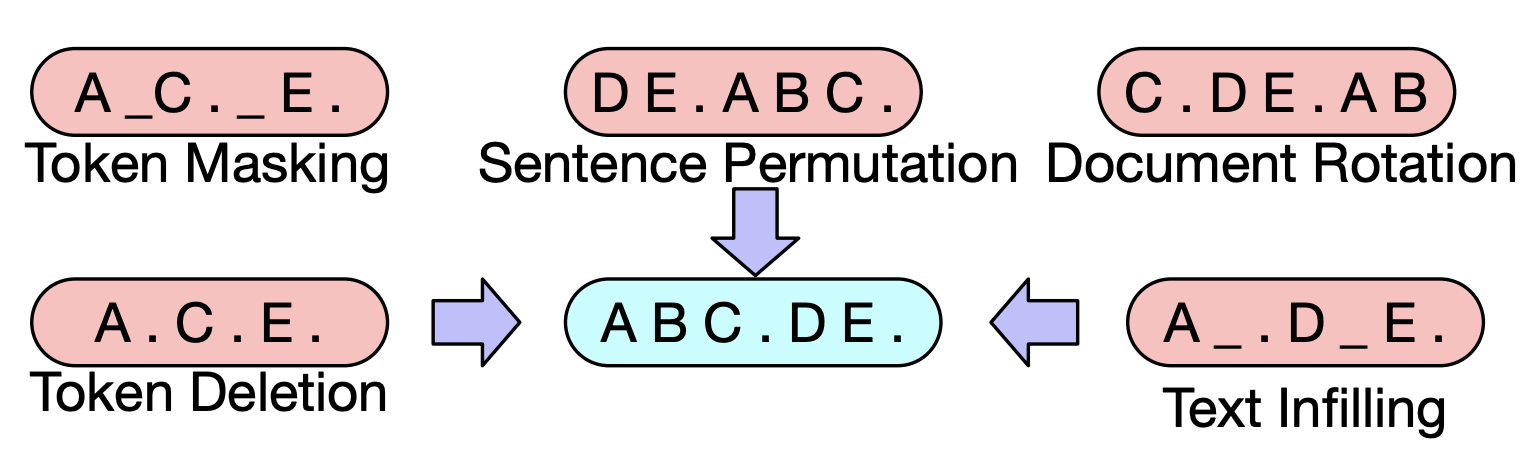
출처 : BART paper
💡Fine-tuning BART
BART는 다양한 downstream task를 위해 활용될 수 있습니다
1. Sequence classification (Discriminative)
- pre-trained BART의 encoder와 decoder에 input sequence를 동일하게 입력합니다. 모델의 마지막 decoder의 마지막 hidden state를 classifier layer에 통과시킵니다. hidden state는 BERT의
[CLS]토큰과 비슷한 역할을 하지만, 모든 sequence의 정보를 담고 있다는 점이 특징입니다.
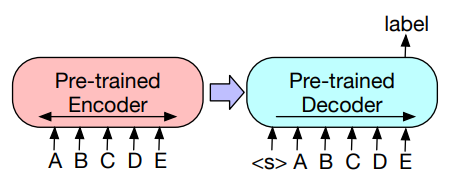
2. Token classification (Discriminative)
- complete document를 BART에 feed하고, decoder의 top hidden state를 각각의 단어에 대한 representation으로 사용합니다. 이 representation은 token classification task에 활용됩니다.
3. Sequence generation (Generative)
- BART는 pre-train 단계에서부터 generation을 학습하였기 때문에 별도의 Fine-tuning없이도 sequence를 만들 수 있습니다. encoder에 input sequence를 넣고 output은 Autoregressive하게 만들면 됩니다(abstractive summarization에 활용 가능).
4. Machine translation (Generative)
- 기존의 Encoder+Decoder 구조의 pre-trained transformer 모델의 decoder는 machine translation task에 곧바로 활용하기 어려웠습니다.
- BART는 encoder에 새로운 parameter set(new encoder)를 추가해 MT task에도 활용이 가능함을 보였습니다.
- 새로운 encoder (source encoder)는
end-to-end로 학습되며 foreign words(번역하려는 문장)를 decoder가 English로 de-noise할 수 있도록 mapping합니다. - source encoder는 두 단계로 학습됩니다. 두 단계 모두 BART의 output으로부터 구해진
cross-entropy loss를 사용합니다. 첫 번째 스텝으로 BART의 parameter를 freeze시키고, (1) source encoder와 (2) positional embedding, BART encoder의 첫번째 layer의 (3) self-attention projection matrix만 업데이트 합니다. 다음 단계에서는 전체 model parameter를 소수의 iteration 동안 학습시킵니다.
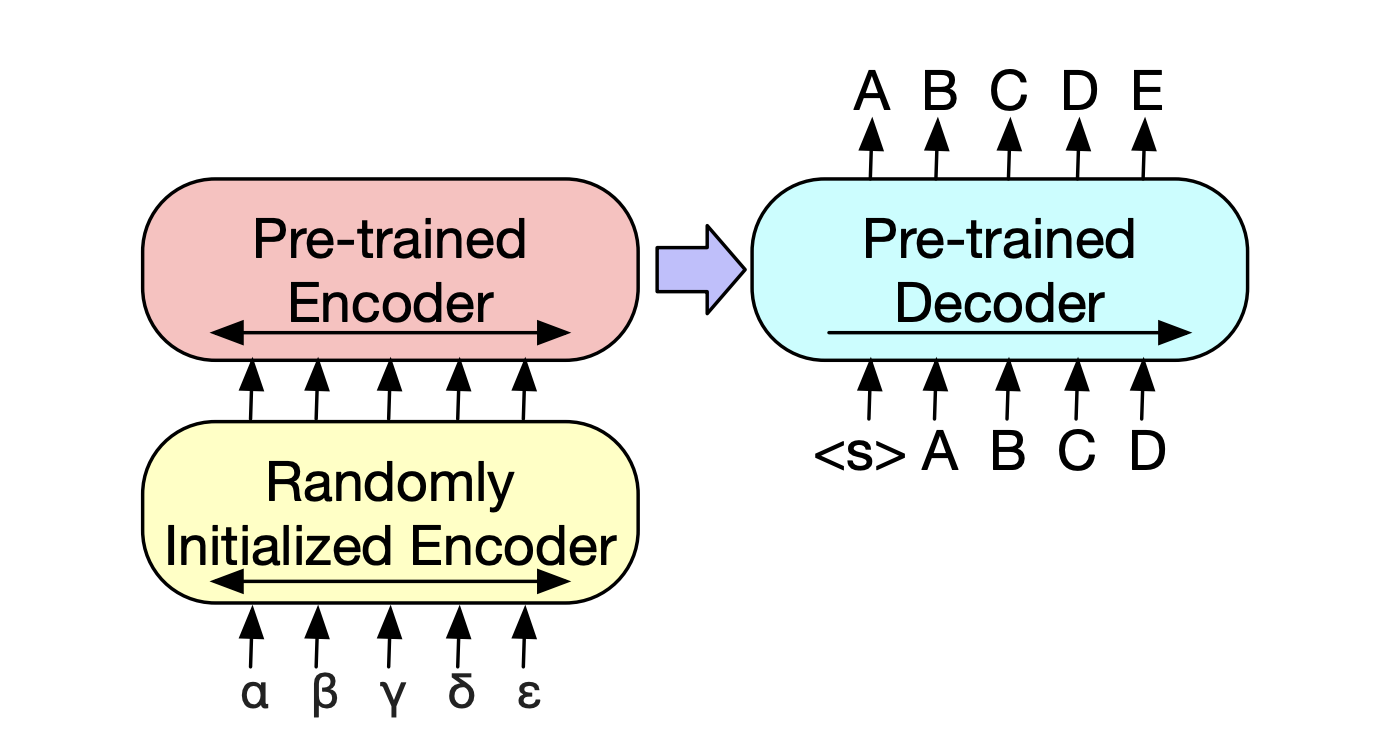
Experiments
다른 model들(주로 BERT)과의 비교 및 pre-training objectives별 성능을 관찰하기 위해 일반적인 수준에서 pre-train을 하고, large scale에서 다시 학습을 해 성능을 비교한 결과는 다음과 같습니다.
💡Comparing Pre-training obejectives
BART의 저자들은 (1) 기존의 LM들과 BART의 성능을 비교하기 위해 pre-training objectives별로 직접 모델을 학습시켰고 (2) corruption 기법의 성능을 검증하기 위해 다양한 조건에서 BART를 학습시켰습니다. BART는 base-size model (6 encoder and 6 decoder layers, with a hidden size of 768)을 사용했습니다. 학습에는 BERT와 비슷한 데이터셋을 사용했습니다.
-
Language Model
GPT와 같은 형태의 left-to-right Transformer LM입니다. cross-attention이 빠진 BART의 decoder를 의미합니다 -
Permuted Language Model
XLNet과 유사하게 1/6 token을 샘플링해서 random order를 autoregressively하게 만들었습니다. 다른 model들과의 일관성을 위해 별도의 positional embedding 기법이나 attention 기법을 사용하지는 않았습니다 -
Masked Language Model
BERT와 같이 15%의 토큰을[MASK]토큰으로 대체했습니다 -
Multitask Masked Language Model
UniLM(Dong et al., 2019)과 비슷하게 여러 self-attention mask를 사용했습니다. self-attention mask는 1/6 확률로 left-to-right, 1/6확률로 right-to-left, 1/3 확률로 unmasked, 1/3 확률로 앞의 절반은 unmasked, 나머지 절반은 left-to-right mask로 선택됩니다 -
Masked Seq-to-Seq
MASS model과 비슷하게 50%의 토큰을 masking 해서 masked 토큰을 예측하도록 합니다
실험 결과에서 주목할 점은 다음과 같습니다 (테이블을 위에서부터 Table 1, 2, 3라고 하겠습니다)
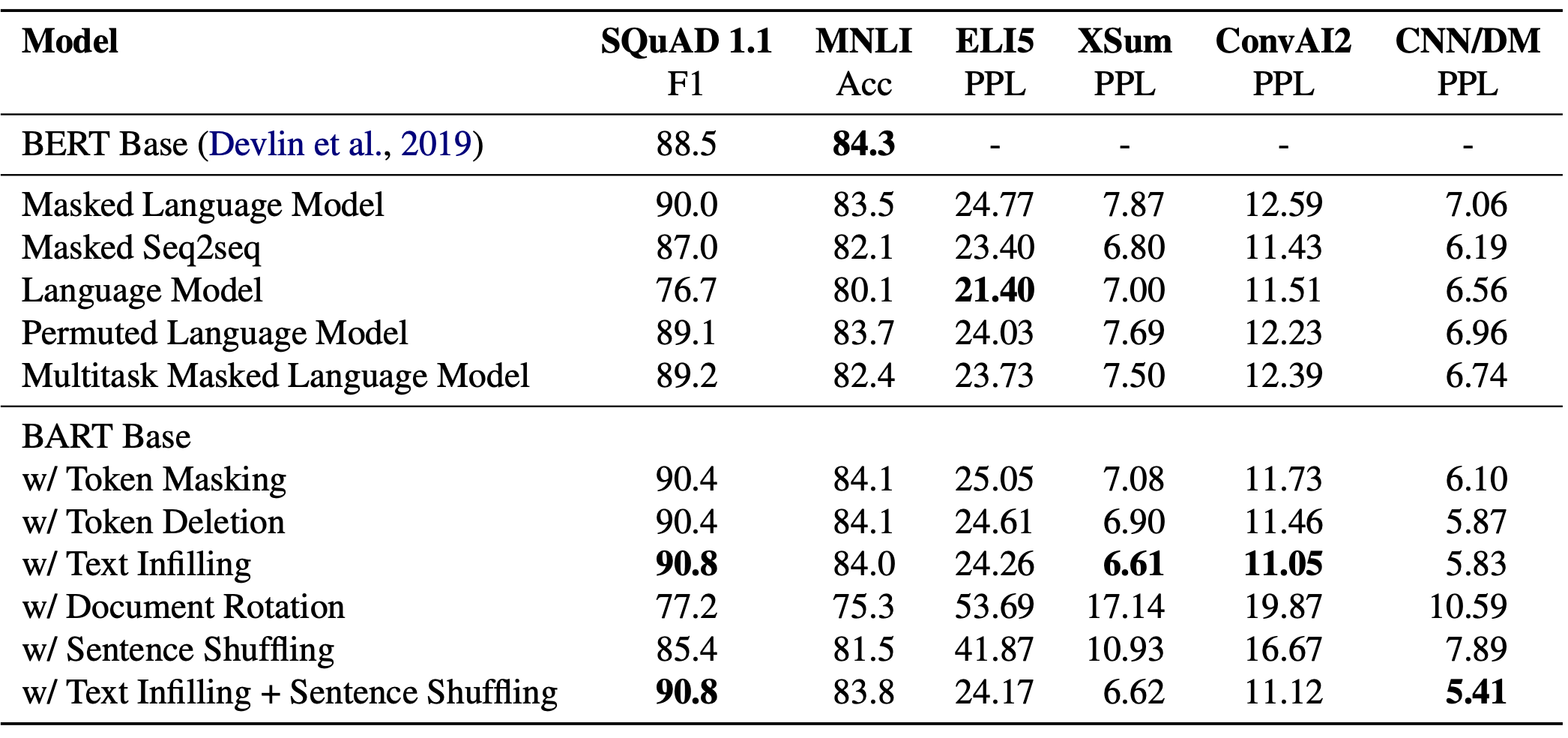
- [Table 2] task별로 성능의 격차가 크다. 즉 일반적인 LM들이 특정 downstream task에 적합하게 학습된 것을 알 수 있다
- [Table 3] 토큰을 masking하는 방법이 성능을 좌우한다
- [Table 2] Left-to-right 방식(Language Model)의 pre-training이 generation task에서 높은 성능을 보인다
- [Table 2] Bi-directional encoder가 SQuAD task에서 중요하다
- [Table 2] ELI5 task에서는 pure Language Model의 성능이 좋게 나왔다. BART의 저자들은 output이 input에 loosely contrained되는 상황에서는 BART의 성능이 좋지 않다고 한다
- [Table 3] BART가 전반적인 task에서 좋은 성능을 보여주고 있다
💡Large-scale Pre-training
1. model size
layer: 12hidden size: 1024batch size: 8000train step: 500,000 steptokenizer: Byte-Pair encoding (same as GPT-2)token corruption: text infilling + sentence permutation + mask 30% tokenscorpus: 160GB
2. 성능비교
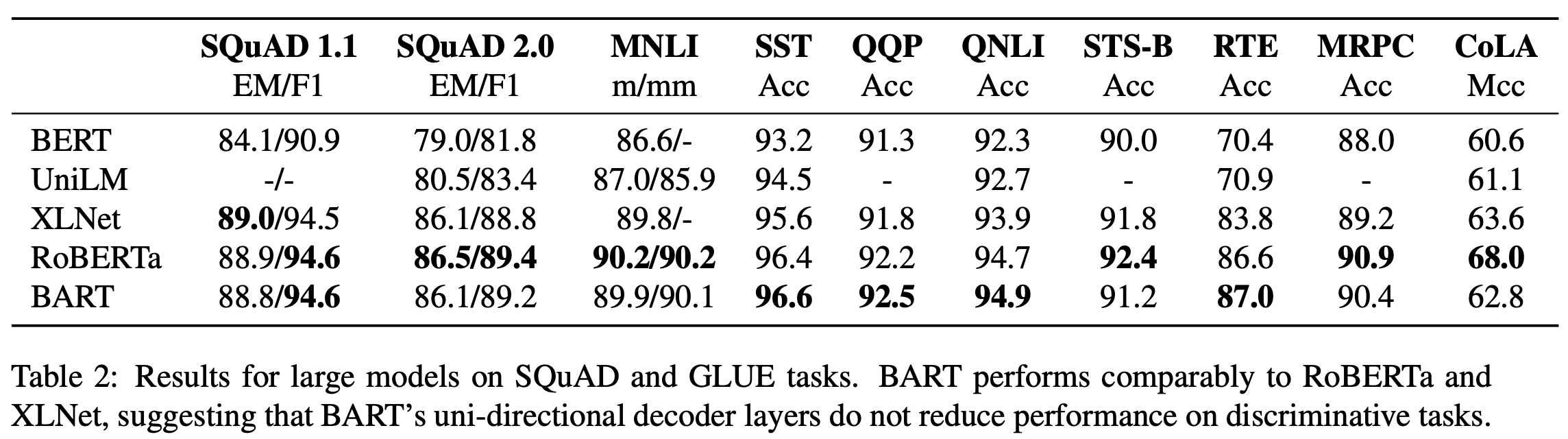
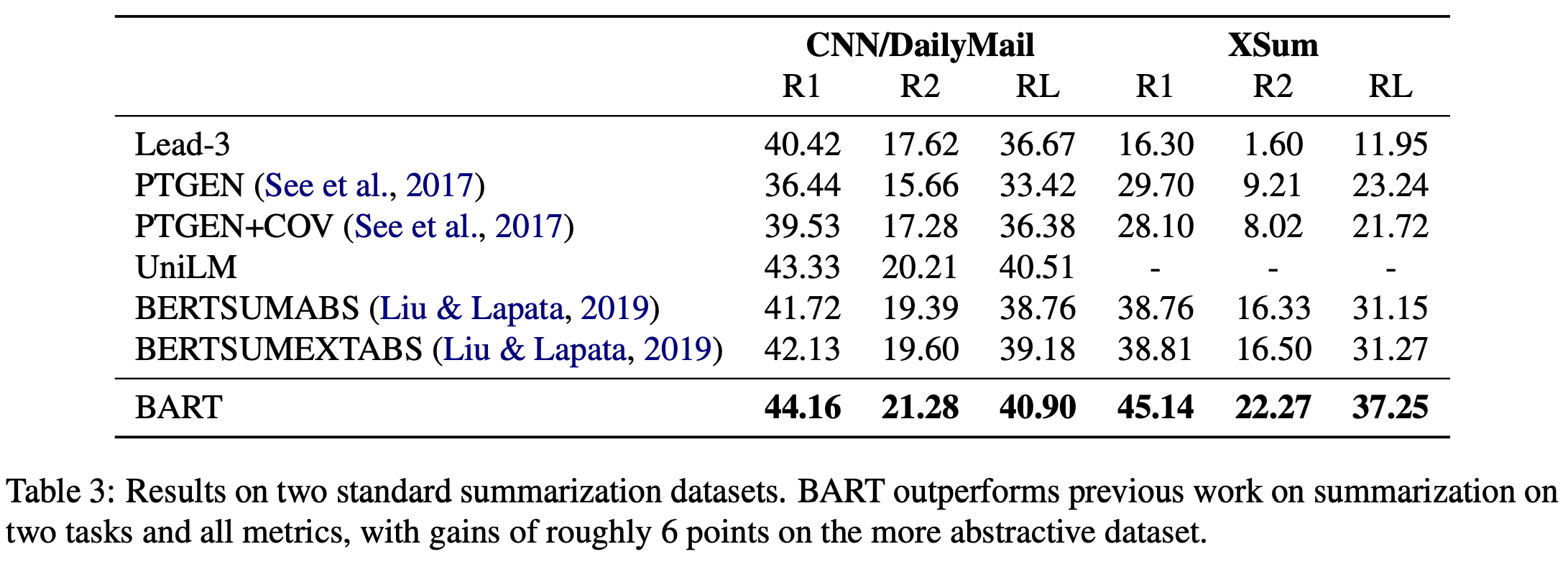
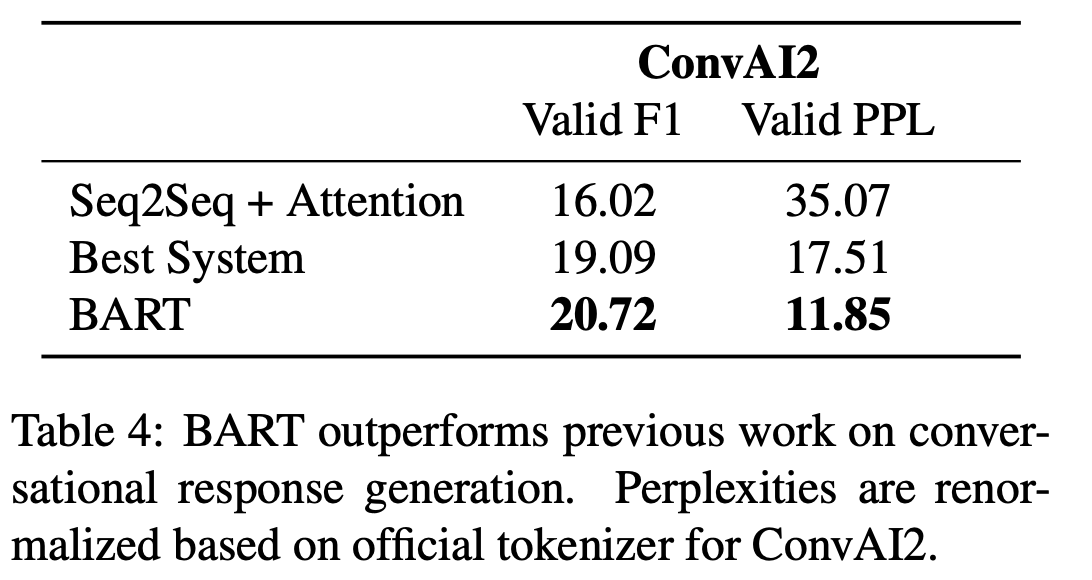
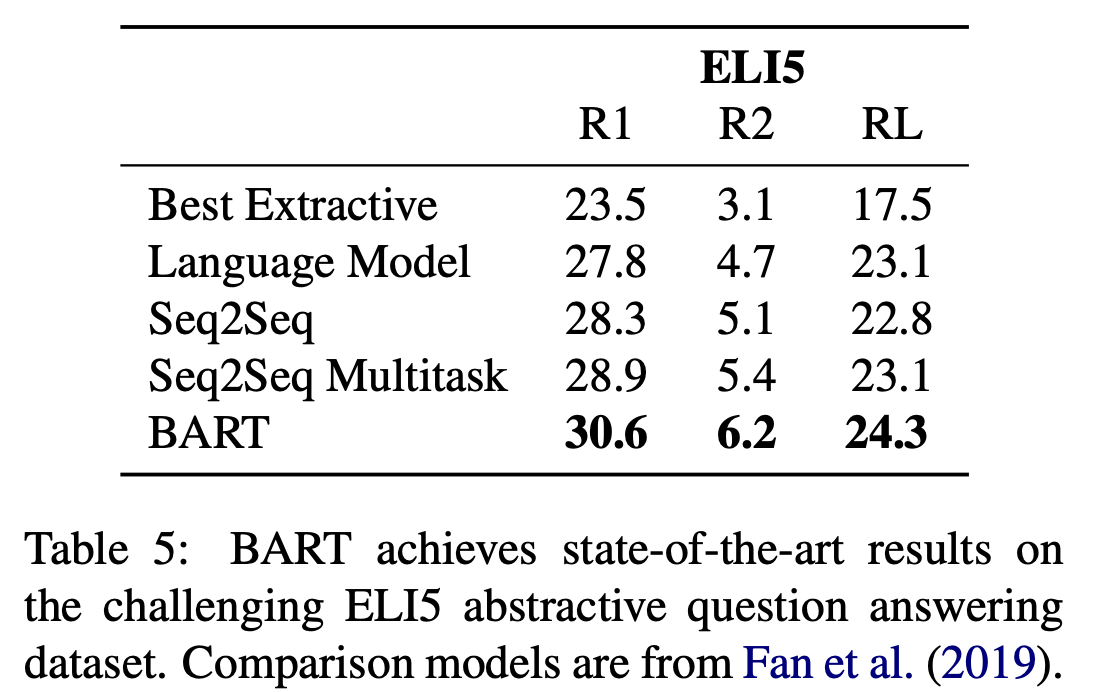

discriminative task에서 일부 SOTA 성능을 보이고 있고, 특히 generation task에 대해 높은 성능을 보이고 있음을 알 수 있습니다.
Result
- BART는 AE 방식과 Seq-to-Seq model을 결합하여 Generation task 뿐만 아니라 Discriminative task에서도 우수한 성능을 보이는 모델임을 알 수 있습니다.
- 이후 Facebook AI 팀에서 multilingual corpus를 학습시켜 machine translation task의 성능을 더욱 향상시킨
mBART(Multilingual Denoising Pre-training for Neural Machine Translation)를 발표했습니다.
