- 선행 조건
gmail 계정 필요
kaggle 가입
머신러닝의 회귀와 분류
해답을 내는 방법을 크게 회귀 또는 분류로 나눈다.
- 회귀 (Regression)
입력값이 연속적인 소수점으로 예측하게 하도록 푸는 방법을 회귀
- 분류 (Classification)
- 다중 분류(Multi-class classification, Multi-label classification)
각각의 케이스에 따라 여러개의 output이 나올 수 있음
- 이진 분류(Binary classification) 0이면 False, 1이면 True
- 회귀와 분류 같이 사용
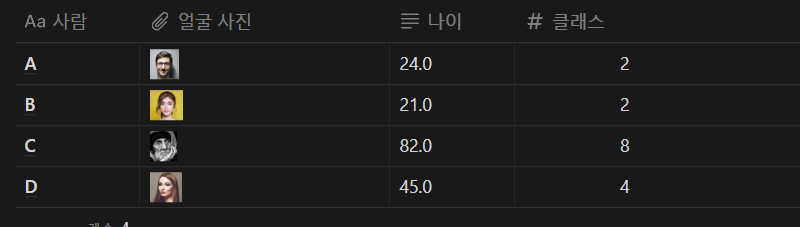
나이 : 연속적인 값, 회귀 방식
클래스 : 데이터에 따른 정해진 결과값의 묶음, 분류 방식
머신 러닝의 학습
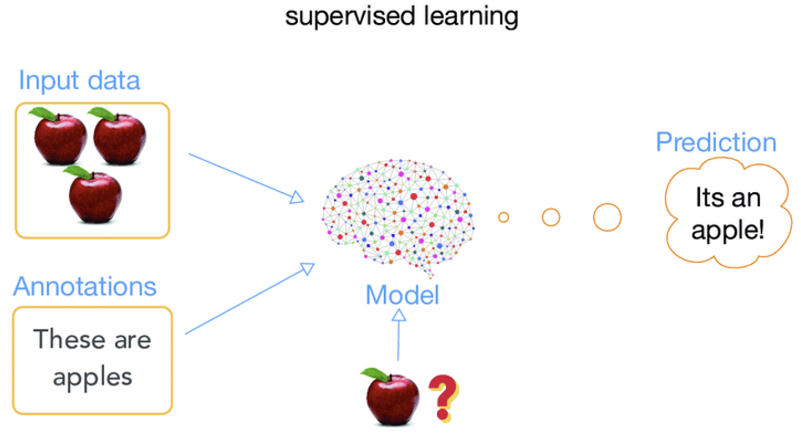
지도 학습 (Supervised learning)
정답을 알려주면서 학습 시키는 방법
기계에게 입력값과 출력값을 전부 보여주면서 학습시킨다.
라벨링(Labeling, 레이블링) 또는 어노테이션(Annotation)
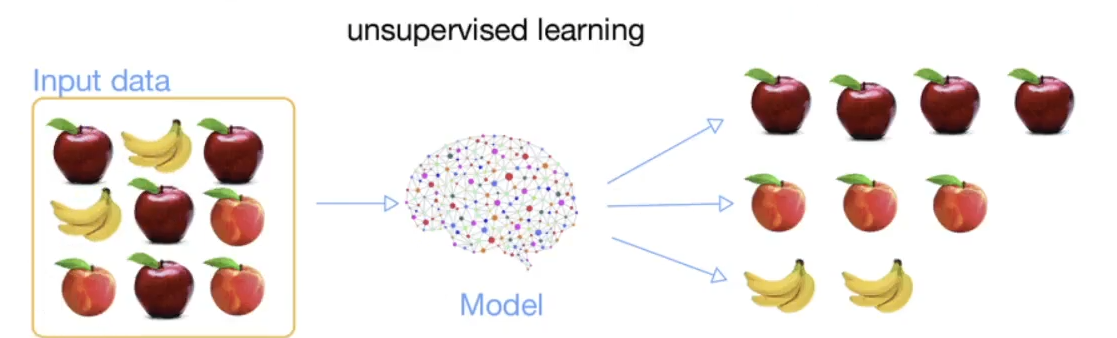
비 지도 학습(unsupervised learning
정답을 알려주지 않고 군집화(Clustering)하는 방법
강화 학습(Reinforcement learning)
주어진 데이터없이 실행과 오류를 반복하면서 학습하는 방법
- 강화 학습의 개념
- 에이전트(Agent)
- 환경(Environment)
- 상태(State)
- 행동(Action)
- 보상(Reward)
게임을 예로 들면 게임의 규칙을 따로 입력하지 않고 자신(Agent)이 게임 환경(Environment)에서 현재 상태(State)에서 높은 점수(Reward)를 얻는 방법을 찾아가며 행동(Action)하는 학습 방법으로 특정 학습 횟수를 초과하면 높은 점수(Reward)를 획득할 수 있는 전략이 형성되게 됩니다. 단, 행동(Action)을 위한 행동 목록(방향키, 버튼)등은 사전에 정의가 되어야 합니다.
선형 회귀
- 선형 회귀와 가설, 손실 함수 Hypothesis & Cost function (Loss function)
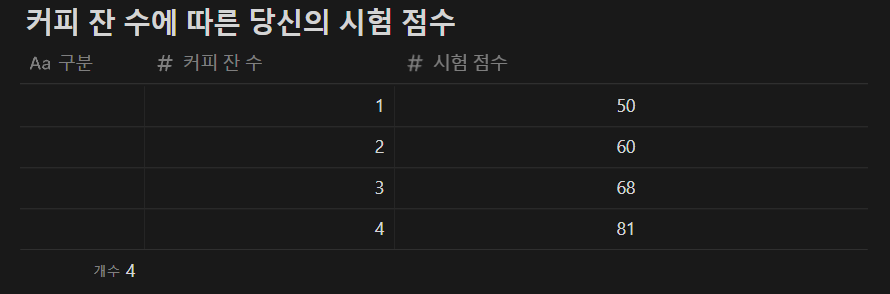
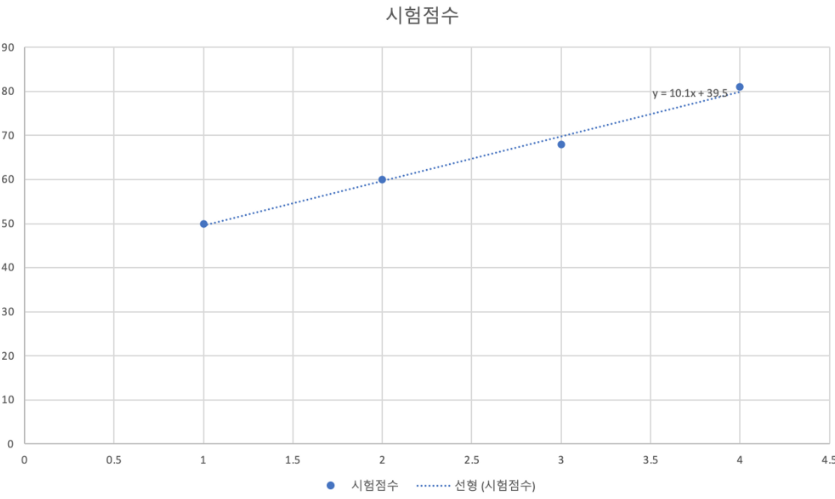
❓ 시험 전 날 마신 커피 잔 수에 따라 시험 점수를 예측할 수 있을까?
그래프를 보고 가설을 세울 수 있는데요.
임의의 직선 1개로 이 그래프를 비슷하게 표현할 수 있다고 가설을 세울 수 있습니다.
(직선 = 1차 함수)
- mean squared error
우리는 정확한 시험 점수를 예측하기 위해 우리가 만든 임의의 직선(가설)과 점(정답)의 거리가 가까워지도록 해야합니다. (=mean squared error)
H(x)는 우리가 가정한 직선이고 y 는 정답 포인트라고 했을 때
H(x)와 y의 거리(또는 차의 절대값)가 최소가 되어야
이 모델이 잘 학습되었다고 말할 수 있을겁니다.
여기서 우리가 임의로 만든 직선 H(x)를 가설(Hypothesis)이라고 하고
Cost를 손실 함수(Cost or Loss function)라고 합니다.
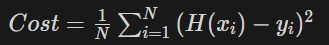
다중 선형 회귀
선형 회귀와 똑같지만 입력 변수가 여러개라고 생각한다.
위에서는 마신 커피 잔 수만 입력값으로 들어갔지만 만약 입력값이 2개 이상이 되는 문제를 선형 회귀로 풀고 싶을 때 다중 선형 회귀를 사용합니다.

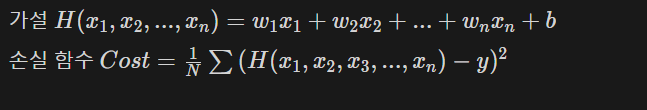
경사 하강법
- 경사 하강법이란?
우리는 위에서 정의한 손실 함수를 대충 상상해 볼겁니다.
손실 함수가 아래와 같은 모양을 가지고 있다고 가정해보죠.
우리의 목표는 손실 함수를 최소화(Optimize)하는 것입니다.
컴퓨터는 사람처럼 수식을 풀 수 없기때문에 경사 하강법이라는 방법을 써서 점진적으로 문제를 풀어갑니다. 처음에 랜덤으로 한 점으로부터 시작합니다. 좌우로 조금씩 그리고 한번씩 움직이면서 이전 값보다 작아지는지를 관찰합니다. 한칸씩 전진하는 단위를 Learning rate라고 부르죠. 그리고 그래프의 최소점에 도달하게 되면 학습을 종료
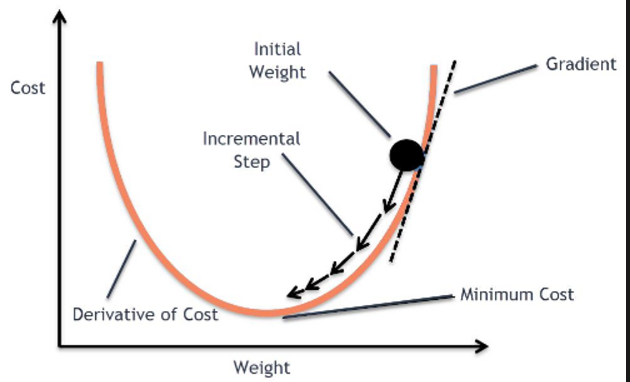
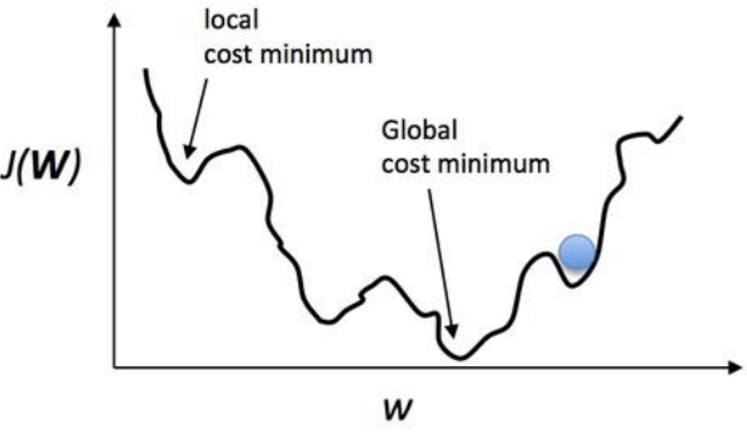
- Local cost minimum , Global cost minimum
Global cost minimum을 찾는 것입니다.
그런데 우리가 한 칸씩 움직이는 스텝(Learning rate)를 잘못 설정할 경우 Local cost minimum에 빠질 가능성이 높습니다.
Cost가 높다는 얘기는 우리가 만든 모델의 정확도가 낮다는 말과 같지요.
따라서 우리는 최대한 Global minimum을 찾기 위해 좋은 가설과 좋은 손실 함수를 만들어서 기계가 잘 학습할 수 있도록 만들어야하고 그것이 바로 머신러닝 엔지니어의 핵심 역할입니다!
데이터셋 분할
- 학습/검증/테스트 데이터
- Training set (학습 데이터셋, 트레이닝셋) = 교과서
머신러닝 모델을 학습시키는 용도로 사용합니다. 전체 데이터셋의 약 80% 정도를 차지합니다.
- Validation set (검증 데이터셋, 밸리데이션셋) = 모의고사
머신러닝 모델의 성능을 검증하고 튜닝하는 지표의 용도로 사용합니다. 이 데이터는 정답 라벨이 있고, 학습 단계에서 사용하기는 하지만, 모델에게 데이터를 직접 보여주지는 않으므로 모델의 성능에 영향을 미치지는 않습니다.
손실 함수, Optimizer 등을 바꾸면서 모델을 검증하는 용도로 사용합니다. (실습에서 자세히 다룰게요!)
전체 데이터셋의 약 20% 정도를 차지합니다.- Test set (평가 데이터셋, 테스트셋) = 수능
정답 라벨이 없는 실제 환경에서의 평가 데이터셋입니다. 검증 데이터셋으로 평가된 모델이 아무리 정확도가 높더라도 사용자가 사용하는 제품에서 제대로 동작하지 않는다면 소용이 없겠죠?

실습 환경 소개 : Colab
Colaboratory
colab 소개 실습
구글에서 만든 개발환경, 구글 드라이브에 파일을 올려 놓고 웹 상에서 직접 코드를
구현할 수 있다.
- 주피터 노트북을 웹브라우저 상으로 구글 서버에서 돌릴 수 있다.
- 파이썬 코드를 블록 단위로 실행할 수 있다.
- 개발환경을 구축하지 않아도 된다.
- GPU를 무료로 제공한다.(15시간 제한)
- 공유가 간편하다.
선형 회귀 실습
Linear Regression 실습(TensorFlow)
현재 TensorFlow 는 아래 방식으로 구현하는 것을 권장하고 있지 않습니다. 강의에서는 선형 회귀의 이해를 돕기위해 아래의 코드를 사용했지만 TensorFlow에서는 keras 사용하도록 권장하고 있고 우리 강의에서도 최신 트렌드에 맞게 keras를 사용할 예정입니다!
TensorFlow : 기본 머신러닝 프레임 워크
Keras : TensorFlow의 상위 API, 조금더 사용하기 쉽기 때문에 v2부터는 Keras를 사용하길 권장하고 있다.
- TensorFlow import , 데이터와 변서 설정
import tensorflow as tf
# Tensorflow의 버전
tf.compat.v1.disable_eager_execution()
# 입력 데이터
x_data = [[1, 1], [2, 2], [3, 3]]
# 출력 데이터
y_data = [[10], [20], [30]]
# placeholder : x와 y가 들어갈 공간 마련
# float 32 : 실수형 32bit
# shape : 입,출력 값의 모양
# None : 배치 사이즈
X = tf.compat.v1.placeholder(tf.float32, shape=[None, 2])
Y = tf.compat.v1.placeholder(tf.float32, shape=[None, 1])
# Weight , bias 의 Variable 를 랜덤값으로 초기화
W = tf.Variable(tf.random.normal(shape=(2, 1)), name='W')
b = tf.Variable(tf.random.normal(shape=(1,)), name='b')- 가설과 비용함수(cost function), optimizer를 정의
# 선형일것이라 가정 (W*x) + b
hypothesis = tf.matmul(X, W) + b
# cost function은 mean squared error를 사용 (뺀값에 제곱)
# 가설에서 정답값을 뺀 다음 제곱(square)을 한 값의 평균(reduce_mean)
cost = tf.reduce_mean(tf.square(hypothesis - Y))
# GradientDescentOptimizer 메서드 사용
# learning_rate=0.01 : step 설정
# minimize(cost) cost를 최소화 한 방향으로 간다.
optimizer = tf.compat.v1.train.GradientDescentOptimizer(learning_rate=0.01).minimize(cost)- 매 스텝 별로 결과를 출력하며 비용함수가 줄어드는 것을 확인합니다.
# 모델 학습을 위해서 Session이라는 개념이 필요
# Seesion = 모든 변수들과 그래프들을 저장하는 저장소
with tf.compat.v1.Session() as sess:
# global_variables_initializer : 모든 변수들을 초기화
sess.run(tf.compat.v1.global_variables_initializer())
# 50회 반복 학습
for step in range(50):
# sess.run([cost, W, b, optimizer] : cost 계산
# feed_dict={X: x_data, Y: y_data}) : 데이터셋을 넣어준다.
c, W_, b_, _ = sess.run([cost, W, b, optimizer], feed_dict={X: x_data, Y: y_data})
print('Step: %2d\t loss: %.2f\t' % (step, c))
print(sess.run(hypothesis, feed_dict={X: [[4, 4]]}))- 출력
loss function이 점점 줄어드는 것을 알 수 있다.
40에 가까운 정답을 맞춘것을 확인할 수 있다.
Step: 0 loss: 395.51
.... 생략
Step: 49 loss: 0.87
[[38.187023]]- Linear Regression 실습 (Keras)
import numpy as np
# Sequential : 모델 정의
from tensorflow.keras.models import Sequential
# Dense 가설 정의
from tensorflow.keras.layers import Dense
from tensorflow.keras.optimizers import Adam, SGD
# 입출력 정의
x_data = np.array([[1], [2], [3]])
y_data = np.array([[10], [20], [30]])
# 모델 정의
model = Sequential([
Dense(1)
])
# 모델 구성
# loss='mean_squared_error' :loss funtion 정의
model.compile(loss='mean_squared_error', optimizer=SGD(lr=0.1))
# 모델 학습
model.fit(x_data, y_data, epochs=100) # epochs 복수형으로 쓰기!Kaggle 캐글 선형 회귀
숙제 : 연차로부터 연봉을 예측
