딥러닝 학습 Week3
학습 전 꿀팁
- 학습 목표
딥러닝 모델 설계를 하기전,
오픈 소스로 공개된 라이브러리를 활용하며
딥러닝 모델을 다루는 법에 좀더 친숙해 진다.

- 머신 러닝의 특징
- 기존의 프로그래밍
규칙 : a + b
데이터 : 10, 20
답 : 30
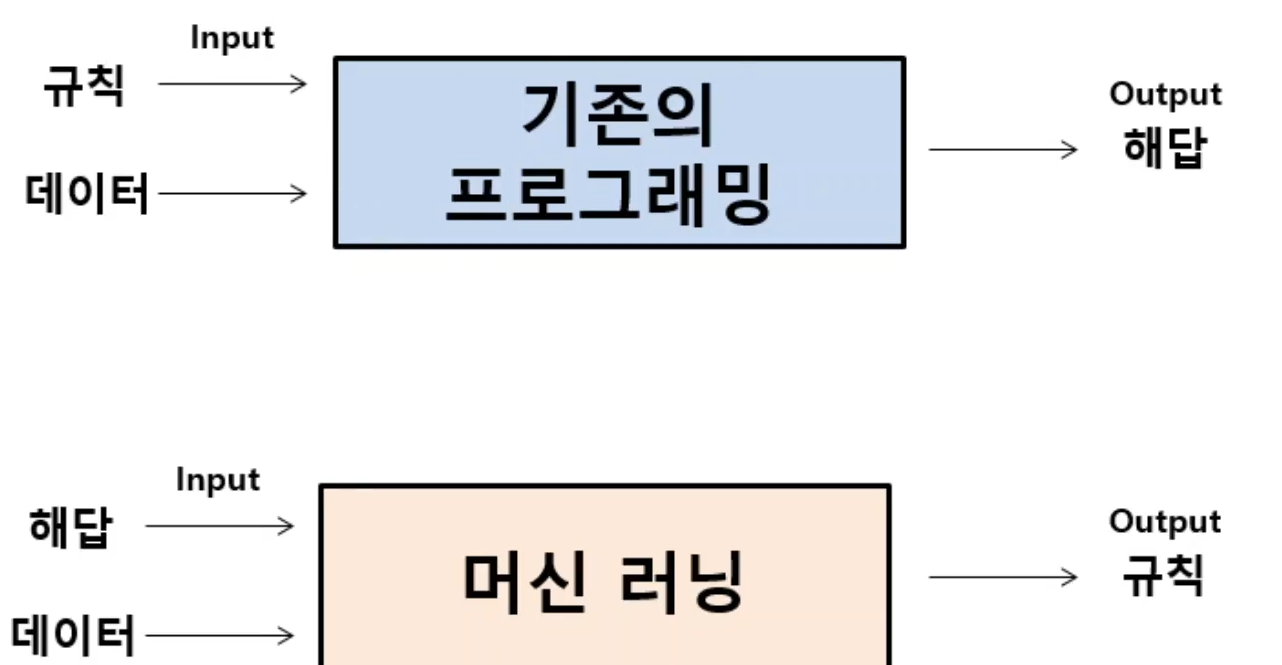

- 머신러닝
supervised learning(지도학습)
데이터와 해답을 가지고 규칙을 찾아가는 일
- unsupervised learning(비 지도학습)


마스크 착용 여부 판단 하기
# res10,deploy : 얼굴을 찾는 모델
# mask_detector 마스크를 착용했는지 판단하는 모델
from tensorflow.keras.applications.mobilenet_v2 import preprocess_input
from tensorflow.keras.models import load_model
import numpy as np
import cv2
facenet = cv2.dnn.readNet('models/deploy.prototxt', 'models/res10_300x300_ssd_iter_140000.caffemodel')
# 얼굴 영역 탐지
model = load_model('models/mask_detector.model')
# load_model :tensorflow 모델
cap = cv2.VideoCapture('videos/04.mp4')
while True:
ret, img = cap.read()
if ret == False:
break
# 이미지 전처리하기
h, w, c = img.shape
# 전처리 결과값 반영
blob = cv2.dnn.blobFromImage(img, size=(300, 300), mean=(104., 177., 123.))
# 얼굴 영역 탐지 모델로 추론하기
facenet.setInput(blob) # 전처리 결과값을 input으로 지정
dets = facenet.forward() # 얼굴 영역 탐지 결과 저장
# 각 얼굴에 대해서 반복문 돌기
for i in range(dets.shape[2]): # dets.shape[2] : 얼굴의 개수
confidence = dets[0, 0, i, 2] # confidence : 탐색해낸것의 확률을 나타낸다.
if confidence < 0.5: # 딥러닝 모델이 찾아낸 결과값의 확률이 50%보다 미만이면 넘어간다.
continue
# 사각형 꼭지점 찾기
# w, h 를 곱하는 이유 : 모델은 좌측 위부터 x에서 n% , y에서 n% 거리가 있는곳에 얼굴이 있다는것을 추론하기 때문
x1 = int(dets[0, 0, i, 3] * w)
y1 = int(dets[0, 0, i, 4] * h)
x2 = int(dets[0, 0, i, 5] * w)
y2 = int(dets[0, 0, i, 6] * h)
# 사각형 그리기
cv2.rectangle(img, pt1=(x1, y1), pt2=(x2, y2), thickness=2, color=(0, 255, 0))
cv2.imshow('result', img)
if cv2.waitKey(1) == ord('q'):
break마스크 착용 여부 판단
face = img[y1:y2, x1:x2]
# 잘라낸 얼굴 이미지 변수에 담기
face_input = cv2.resize(face, dsize=(224, 224)) # 잘라낸 이미지 사진 크기 재 조정
face_input = cv2.cvtColor(face_input, cv2.COLOR_BGR2RGB) # 입력값을 BGR > RGB로 변경
face_input = preprocess_input(face_input) # 마스크 판단 전처리 함수
face_input = np.expand_dims(face_input, axis=0) # expand_dims 차원 변형 함수
mask,nomask = model.predict(face_input).squeeze()
# 출력 값
# predict : 예측 , face_input : 전처리 데이터 , squeeze() : 차원 축소, 재 조정
# 코드 해석 : mask를 쓴 확률, mask를 쓰지 않은 확률을 구한다.
color = (0,255,0) if mask > nomask else (0,0,255)
# color 기반 = BGR
# 마스크를 착용했다면 사각형의 색깔을 초록색, 착용하지 않았다면 빨강색으로 정하고자 한다.성별,나이 분석하기
- 선행 사항 변수 작성
- 모델 불러오기
gender_list = ['Male', 'Female'] # 0 or 1
age_list = ['(0, 2)','(4, 6)','(8, 12)','(15, 20)','(25, 32)','(38, 43)','(48, 53)','(60, 100)']
# list의 index에따라 model의 output(0~len(age_list))에 따라 index의 나이대를 추정
# 모델 로드
gender_net = cv2.dnn.readNetFromCaffe('models/deploy_gender.prototxt', 'models/gender_net.caffemodel')
age_net = cv2.dnn.readNetFromCaffe('models/deploy_age.prototxt', 'models/age_net.caffemodel')- 출력
cv2.putText(img, '%s, %s' % (gender, age), org=(x1, y1), fontFace=cv2.FONT_HERSHEY_SIMPLEX, fontScale=1, color=(0,255,0), thickness=2)
# putText : 텍스트 출력
# org = 출력될 위치값
# FONT_HERSHEY_SIMPLEX : scv의 기본 지원 font
# fontScale : fontSize
# color : RGB기반- 전체 코드
# 추가 모델
# age_net,deploy_age = 나이 판단 모델
# gender_net,deploy_gender = 성별 판단 모델
import numpy as np
import cv2
facenet = cv2.dnn.readNet('models/deploy.prototxt', 'models/res10_300x300_ssd_iter_140000.caffemodel')
gender_list = ['Male', 'Female'] # 0 or 1
age_list = ['(0, 2)','(4, 6)','(8, 12)','(15, 20)','(25, 32)','(38, 43)','(48, 53)','(60, 100)']
# list의 index에따라 model의 output(0~len(age_list))에 따라 index의 나이대를 추정
# 모델 로드
gender_net = cv2.dnn.readNetFromCaffe('models/deploy_gender.prototxt', 'models/gender_net.caffemodel')
age_net = cv2.dnn.readNetFromCaffe('models/deploy_age.prototxt', 'models/age_net.caffemodel')
img = cv2.imread('imgs/02.jpg')
h, w, c = img.shape
# 이미지 전처리하기
blob = cv2.dnn.blobFromImage(img, size=(300, 300), mean=(104., 177., 123.))
# 얼굴 영역 탐지 모델로 추론하기
facenet.setInput(blob)
dets = facenet.forward()
# 각 얼굴에 대해서 반복문 돌기
for i in range(dets.shape[2]):
confidence = dets[0, 0, i, 2]
if confidence < 0.5:
continue
# 사각형 꼭지점 찾기
x1 = int(dets[0, 0, i, 3] * w)
y1 = int(dets[0, 0, i, 4] * h)
x2 = int(dets[0, 0, i, 5] * w)
y2 = int(dets[0, 0, i, 6] * h)
face = img[y1:y2, x1:x2]
blob = cv2.dnn.blobFromImage(face, size=(227, 227), mean=(78.4263377603, 87.7689143744, 114.895847746))
# 전 처리 코드 input = face , size 227 * 227로 재정의
# 후 처리 코드
gender_net.setInput(blob)
# 모델의 입력값을 선처리 데이터로 선정
gender_index = gender_net.forward().squeeze().argmax()
# forward : 추론 , squeeze : 차원 축소 , argmax : 사람이 이해할 수 있게 압축
gender = gender_list[gender_index]
# gender 결정
age_net.setInput(blob)
# 모델의 입력값 지정
age_index = age_net.forward().squeeze().argmax()
# 추론, 차원 축소, 압축
age = age_list[age_index]
# age 결정
# argmax : confidence의 값이 가장 높은 값을 뽑아 낸다.
cv2.putText(img, '%s, %s' % (gender, age), org=(x1, y1), fontFace=cv2.FONT_HERSHEY_SIMPLEX, fontScale=1, color=(0,255,0), thickness=2)
# putText : 텍스트 출력
# org = 출력될 위치값
# FONT_HERSHEY_SIMPLEX : scv의 기본 지원 font
# fontScale : fontSize
# color : RGB기반
cv2.rectangle(img, pt1=(x1, y1), pt2=(x2, y2), color=(255, 0, 0), thickness=2)
cv2.imshow('result', img)
cv2.waitKey(0)숙제
웹캠의 카메라를 입력값으로 받아, 이번 주차에 배운 내용을 적용해 본다.
- 요구사항 : 마스크 판단 confidence 표시해보기
# 추가 모델
# age_net,deploy_age = 나이 판단 모델
# gender_net,deploy_gender = 성별 판단 모델
from tensorflow.keras.applications.mobilenet_v2 import preprocess_input
from tensorflow.keras.models import load_model
import numpy as np
import cv2
facenet = cv2.dnn.readNet('models/deploy.prototxt', 'models/res10_300x300_ssd_iter_140000.caffemodel')
gender_list = ['Male', 'Female'] # 0 or 1
age_list = ['(0, 2)','(4, 6)','(8, 12)','(15, 20)','(25, 32)','(38, 43)','(48, 53)','(60, 100)']
# list의 index에따라 model의 output(0~len(age_list))에 따라 index의 나이대를 추정
# 성별, 나이 판단 모델 로드
gender_net = cv2.dnn.readNetFromCaffe('models/deploy_gender.prototxt', 'models/gender_net.caffemodel')
age_net = cv2.dnn.readNetFromCaffe('models/deploy_age.prototxt', 'models/age_net.caffemodel')
# 마스크 착용 여부 판단 모델 로드
facenet = cv2.dnn.readNet('models/deploy.prototxt', 'models/res10_300x300_ssd_iter_140000.caffemodel')
model = load_model('models/mask_detector.model')
cap = cv2.VideoCapture('videos/04.mp4')
while True:
ret, img = cap.read()
if ret == False:
break
h, w, c = img.shape
# 이미지 전처리하기
blob = cv2.dnn.blobFromImage(img, size=(300, 300), mean=(104., 177., 123.))
# 얼굴 영역 탐지 모델로 추론하기
facenet.setInput(blob)
dets = facenet.forward()
# 각 얼굴에 대해서 반복문 돌기
for i in range(dets.shape[2]):
confidence = dets[0, 0, i, 2]
if confidence < 0.5:
continue
# 사각형 꼭지점 찾기
x1 = int(dets[0, 0, i, 3] * w)
y1 = int(dets[0, 0, i, 4] * h)
x2 = int(dets[0, 0, i, 5] * w)
y2 = int(dets[0, 0, i, 6] * h)
face = img[y1:y2, x1:x2]
blob = cv2.dnn.blobFromImage(face, size=(227, 227), mean=(78.4263377603, 87.7689143744, 114.895847746))
# 전 처리 코드 input = face , size 227 * 227로 재정의
# 후 처리 코드, 마스크 착용 판단 여부
face_input = cv2.resize(face, dsize=(224, 224)) # 잘라낸 이미지 사진 크기 재 조정
face_input = cv2.cvtColor(face_input, cv2.COLOR_BGR2RGB) # 입력값을 BGR > RGB로 변경
face_input = preprocess_input(face_input) # 마스크 판단 전처리 함수
face_input = np.expand_dims(face_input, axis=0) # expand_dims 차원 변형 함수
mask,nomask = model.predict(face_input).squeeze()
rectangle_color = (0,255,0) if mask > nomask else (0,0,255)
# 후 처리 코드
gender_net.setInput(blob)
# 모델의 입력값을 선처리 데이터로 선정
gender_index = gender_net.forward().squeeze().argmax()
# forward : 추론 , squeeze : 차원 축소 , argmax : 사람이 이해할 수 있게 압축
gender = gender_list[gender_index]
# gender 결정
# 성별에 따른 Text color 정의
text_color = (255,0,0) if gender == gender_list[0] else (0,255,255)
age_net.setInput(blob)
# 모델의 입력값 지정
age_index = age_net.forward().squeeze().argmax()
# 추론, 차원 축소, 압축
age = age_list[age_index]
# age 결정
# argmax : confidence의 값이 가장 높은 값을 뽑아 낸다.
cv2.putText(img, '%s, %s,%.2f' % (gender, age,mask), org=(x1, y1), fontFace=cv2.FONT_HERSHEY_SIMPLEX, fontScale=1, color=text_color, thickness=2)
# cv2.putText(img, text='%.2f'%mask, org=(x1, y1), fontFace=cv2.FONT_HERSHEY_SIMPLEX, fontScale=1, color=rectangle_color)
# cv2.putText(img, '%s, %s' % (gender, age), org=(x1, y1), fontFace=cv2.FONT_HERSHEY_SIMPLEX, fontScale=1, color=text_color, thickness=2)
# putText : 텍스트 출력
# org = 출력될 위치값
# FONT_HERSHEY_SIMPLEX : scv의 기본 지원 font
# fontScale : fontSize
# color : RGB기반
cv2.rectangle(img, pt1=(x1, y1), pt2=(x2, y2), color=rectangle_color, thickness=2)
cv2.imshow('result', img)
if cv2.waitKey(1) == ord('q'):
break
더 노력하겠습니다
안녕하세요.글 잘 읽었습니다. 혼자 따라할때 참고하고 싶은데요, 'models/deploy.prototxt', 'models/res10_300x300_ssd_iter_140000.caffemodel')같은 모델들은 어디서 구하셨는지 궁금합니다.감사합니다.