1. 모듈
01 모듈(Module)이란?
복잡한 서비스를 만들때는 코드를 파일단위로 나눠준다. 이 파일단위를 모듈이라고 한다. 예를 들어 게임의 상점 기능으 만든다면, 아이템 모듈, 상점의 거래기능 모듈, npc 모듈... 이렇게!
모듈의 장점
- 한 파일에서 구현하고자 하는게 더 명확해져서 코드를 짜고 관리하기 쉬워짐
- 코드를 여러곳에 재사용하기 쉬워짐
02 다른 파일=모듈 사용하기
-
기본방법
1) 같은 폴더에 있는 모듈
2) import 모듈파일명
이러면 모듈에 있는 모든 변수와 함수를 사용 가능
3) 모듈에 있는 함수 사용하기
print(모듈.함수()) -
모듈이름이 너무 길어서 귀찮을때, 모듈이름을 축약한 간략한 이름으로 정의
import calculator as calc
print(calc.plus(3.5)) -
모듈에서 특정 함수만 가져오기,그 경우 모듈이름을 사용하지 않아도 된다!
from calculator import add, mulitply
print(add(2,5)) -
모듈의 모든 함수를 from으로 가져오기
from calculator import *
print(add(2,5))
- 장점: 함수 앞에 모듈명을 다 쓸 필요가 없음
- 단점: 이 함수가 어떤 모듈에서 가져온 건지 알 수 없어서 비추천!
03 클래스
모듈에는 변수, 함수 뿐만 아니라 클래스도 있다. 클래스란?
클래스는 파이썬에서 객체 지향 프로그래밍을 구현하는 중요한 개념.
클래스는 데이터(속성)와 해당 데이터를 처리하는 함수(메서드)를 하나로 묶은 사용자 정의 데이터 타입
클래스를 사용하면 코드의 재사용성과 유지보수성을 높일 수 있음
예시1)
class Person:
def __init__(self, name, age):
self.name = name
self.age = age
def introduce(self):
print(f"안녕하세요, 저는 {self.name}이고, 나이는 {self.age}살입니다.")
p1 = Person("홍길동", 30)
p1.introduce() # 출력: 안녕하세요, 저는 홍길동이고, 나이는 30살입니다.
예시2)
# 원 클래스
class Circle:
def __init__(self, radius):
self.radius = radius
def area(self):
return 3.14 * self.radius * self.radius
# 정사각형 클래스
class Square:
def __init__(self, length):
self.length = length
def area(self):
return self.length * self.length다른 파일에서 클래스를 가져올때도 import를 사용하며, as를 통해 이름을 바꿔서 임포트할 수도 있다.
from shapes2d import Square as Sq
square = Sq(3)
print(square.area())04 파일에 무슨 요소가 있는가 알아보기
dir 함수 이 파일에 정의된 모든 요소를 알려주는 함수
예) print(dir(파일이름))
예) print(dir()) #현재 파일에 대해 알아보기
변수, 함수, 임포트된 모듈(as로 약자로 쓰면 약자이름이 나온다), 임포트된 함수(from을 써서 특정 함수만 가져오면 모듈이름은 dir 결과값에 포함되지 않는다)가 나옴
이 외에도 doc, filr과 같은 녀석들이 나오는데 이를 특수변수, 던더(더블언더스코어)라고 부른다. 파이썬이 내부적으로 관리하는 변수들임.
네임스페이스 특정한 객체를 이름에 따라 구분할 수 있는 범위
dir로 보는 것이 네임스페이스이다
파이썬에서는 같은 이름의 요소가 정의될 경우 뒤의 정의로 적용된다
예)
from area import square
def square(r) :
return r*4
print(squre(r)) 결과: area 모듈의 square의 답이 아닌 r*4로 정의된 새로운 square의 답이 출력됨
이를 방지하는 방법
1. import된 square를 다른 임으로 정의한다.
from are import square as sq
2. import를 area 모듈 전체로 한다.
이 경우 dir을 하면 square가 아닌 area로 잡히기 때문!
square는 새로 정의된 함수로, area.square는 이와 별개로 정의 및 호출된다.
05 스탠다드 모듈
모듈을 다르게 정의하면, 여러가지 기능을 정리해둔 파이썬 파일!
그리고 많이 쓸법한 기능들은 이미 모듈로 만들어져 파이썬에 내장되어있음 = 스탠다드 모듈

파이썬 표준 라이브러리 : 여기서 모든 스탠다드 모듈 확인 가능
https://docs.python.org/ko/3/library/
대표 모듈들
math
math는 기본적인 수학 모듈입니다. 여러 수학적인 함수를 제공해 줍니다.
예)
math.cos(0)
math.log10(100)
random
랜덤 한 숫자를 생성하기 위한 다양한 함수들을 제공해 줍니다.
random.randint(1, 20) # 랜덤한 정수 1 <= N <= 20
random.uniform(0, 1) # 랜덤한 소수 0 <= x <= 1
datetime
날짜와 시간을 다루기 위한 다양한 '클래스'를 갖추고 있습니다.
today = datetime.datetime.now() # 현재 시간과 날짜
print(today.strftime("%A, %B %dth %Y")) # 출력값을 "요일, 월 일 연도"로 포매팅
pi_day = datetime.datetime(2020, 3, 14, 13, 6, 15) # 특정 시간과 날짜
print(today - pi_day) # 두 datetime의 차이
os
Operating System, 즉 운영체제의 약자입니다. os 모듈을 통해서 파이썬으로 운영체제를 조작하거나 운영체제에 대한 정보를 가져올 수 있습니다.
os.getlogin() # 현재 어떤 계정으로 로그인 돼있는지 확인
os.getcwd() # 현재 파일의 디렉토리 확인
os.getpid() # 현재 프로세스 ID 확인
os.path #### (잘 모르겠음)
파일 경로를 다룰 때 쓰입니다.
os.path.abspath('..') # 주어진 경로를 절대 경로로
os.path.relpath('/Users/codeit/PycharmProjects') # 주어진 경로를 현재 디렉토리를 기준으로 한 상대 경로로
os.path.join('/Users/codeit/PycharmProjects', 'standard_modules') # 주어진 경로들을 병합
re
프로그래밍에서 Regular Expression (RegEx, re, 한국어로는 정규 표현식)은 특정한 규칙/패턴을 가진 문자열을 표현하는 데 사용됩니다.
import re
# 알파벳으로 구성된 단어들만 매칭
pattern = re.compile('^[A-Za-z]+$')
print(pattern.match('I'))
print(pattern.match('love'))
print(pattern.match('python3'))
print()
# 숫자가 포함된 단어들만 매칭
pattern = re.compile('.*\d+')
print(pattern.match('I'))
print(pattern.match('love'))
print(pattern.match('python3'))
답:
<re.Match object; span=(0, 1), match='I'>
<re.Match object; span=(0, 4), match='love'>
None #3이 있어서 none이 나옴
None #숫자가 하나도 없어서 none이 나옴
None #숫자가 하나도 없어서 none이 나옴
<re.Match object; span=(0, 7), match='python3'>
pickle
pickle 을 사용하면 파이썬 오브젝트(객체)를 바이트(byte) 형식(0,1로 된 이진법 형식)으로 바꿔서 파일에 저장할 수 있고 저장된 오브젝트를 읽어올 수도 있습니다.복잡한 데이터 구조를 저장하고 불러올 때 유용합니다.
import pickle
# 딕셔너리 오브젝트
obj = {'my': 'dictionary'}
# obj를 filename.pickle 파일에 저장
with open('filename.pickle', 'wb') as f:
pickle.dump(obj, f)
# filename.pickle에 있는 오브젝트를 읽어옴
with open('filename.pickle', 'rb') as f:
obj = pickle.load(f)
print(obj)값: {'my': 'dictionary'}
json
json 모듈은 pickle과 비슷하지만 오브젝트를 JSON 형식으로 바꿔줍니다. JSON 형식에 맞는 데이터 (기본 데이터 타입들, 리스트, 딕셔너리)만 바꿀 수 있습니다.
JSON 형식이란 JavaScript Object Notation의 약자로, 데이터를 교환하기 위한 경량의 데이터 형식입니다. 주로 웹 애플리케이션에서 서버와 클라이언트 간에 데이터를 주고받을 때 사용됩니다. JSON은 사람이 읽고 쓰기 쉽고, 기계가 해석하고 생성하기도 쉬운 형식입니다.
import json
# 딕셔너리 오브젝트
obj = {'my': 'dictionary'}
# obj를 filename.json 파일에 저장
with open('filename.json', 'w') as f:
json.dump(obj, f)
# filename.json에 있는 오브젝트를 읽어옴
with open('filename.json', 'r') as f:
obj = json.load(f)
print(obj)값 : {'my': 'dictionary'}
copy
파이썬 오브젝트를 복사할 때 쓰입니다.
예를 들어 '=' 연산자는 실제로 리스트를 복사하지 않습니다. 그렇기에 리스트를 복사하려면 슬라이싱을 사용하거나 copy.copy() 함수를 사용해야 합니다.
import copy
a = [1, 2, 3]
b = a
c = a[:]
d = copy.copy(a)
a[0] = 4
print(a, b, c, d)
#값: [4, 2, 3] [4, 2, 3] [1, 2, 3] [1, 2, 3]
# 여기서 b는 =라서 복사가 아니고 d는 복사이다. 값의 차이 주의!
# 하지만 오브젝트 안에 오브젝트가 있는 경우 copy.copy() 함수는 가장 바깥에 있는 오브젝트만 복사함
# 오브젝트를 재귀적으로 복사하려면 copy.deepcopy() 함수를 사용해야 함
a = [[1,2,3], [4,5,6], [7,8,9]]
b = copy.copy(a)
c = copy.deepcopy(a)
a[0][0] = 4
print(a, b, c)
#값:
[[4, 2, 3], [4, 5, 6], [7, 8, 9]]
[[4, 2, 3], [4, 5, 6], [7, 8, 9]]
[[1, 2, 3], [4, 5, 6], [7, 8, 9]]
sqlite3
sqlite3 모듈을 통해 파이썬에서 SQLite 데이터베이스를 사용할 수 있습니다.
import sqlite3
# 데이터베이스 연결
conn = sqlite3.connect('example.db')
# SQL 문 실행
c = conn.cursor()
c.execute('''SELECT ... FROM ... WHERE ... ''')
# 가져온 데이터를 파이썬에서 사용
rows = c.fetchall()
for row in rows:
print(row)
# 연결 종료
conn.close()06 파일 경로
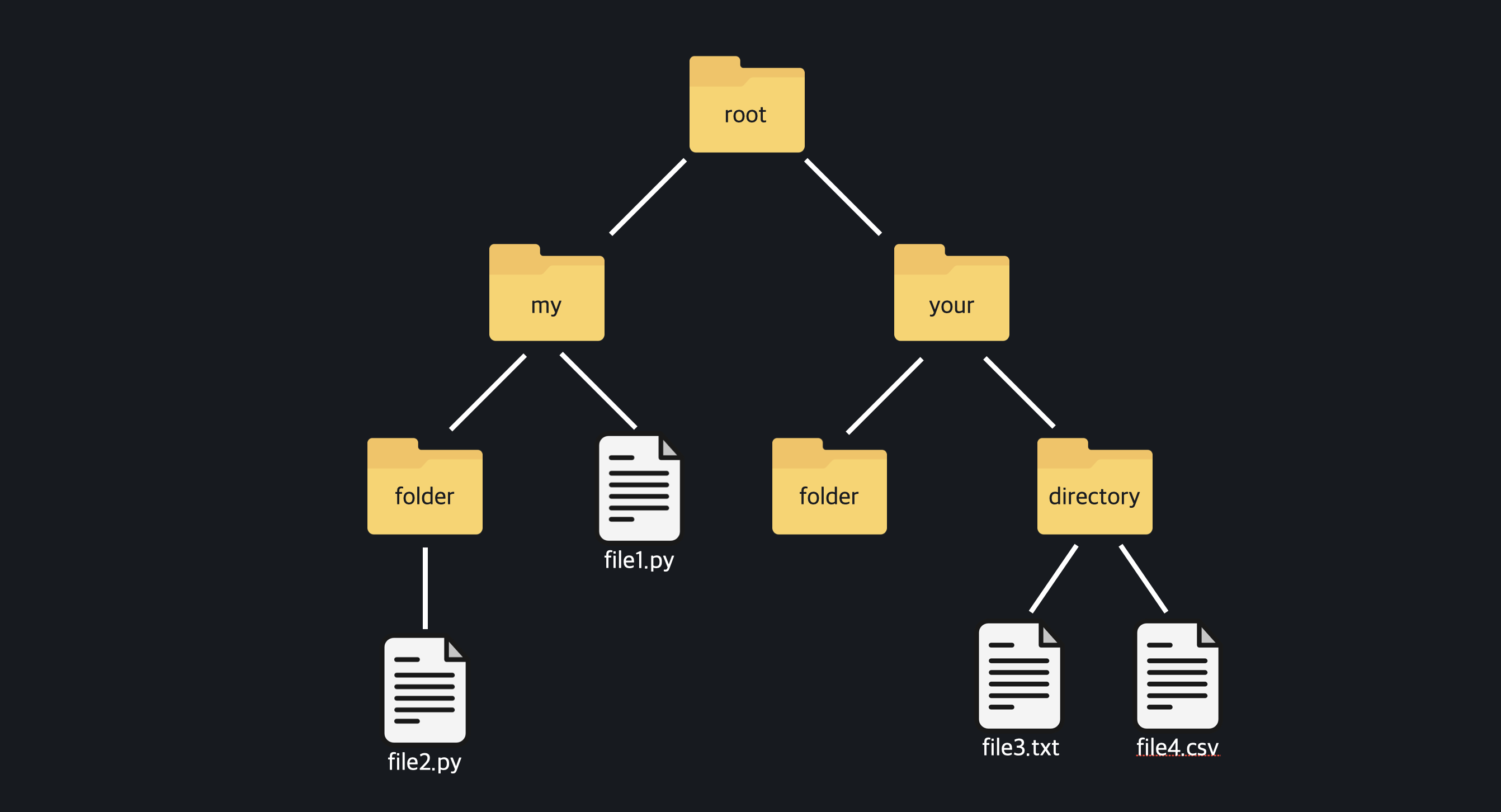
컴퓨터의 파일 시스템은 하나의 뿌리에서 시작해서 여러 개의 가지로 뻗어나가는, 나무 같은 구조를 가지고 있습니다. root라는 폴더 안에 my, your 폴더들이 있고 my 폴더 안에는 folder라는 폴더와 file1.py라는 파일이 있고...
파일 시스템의 뿌리는 항상 '루트(root)' 라고 합니다. 그리고 프로그래밍에서는 폴더를 '디렉토리(directory)'라고도 합니다.
Windows 파일경로 표시방법
- 디렉토리 안을 \ 또는 \로 표기합니다. (\을 사용하는 이유는 \n 처럼 \이 다른용도로도 사용되기 때문)
- 루트 디렉토리 안은 하드 드라이브에 따라서 C:\ 혹은 D:\로 표기합니다
- . 은 현재 디렉토리를 뜻하고 .. 은 상위 디렉토리 (현재 디렉토리를 포함하고 있는 디렉토리)를 뜻합니다
- 절대경로
file1.py의 경로: C:\my\file1.py
file2.py의 경로: C:\my\folder\file2.py
directory의 경로: C:\your\directory - 상대경로 ;
현재위치 my폴더
file1.py의 경로: .\file1.py
file2.py의 경로: .\folder\file2.py
현재위치 file1.py
file2.py의 경로: .\foler\file2.py #현재위치가 my이기 때문
현재위치 file3.py
file4.py의 경로: .\file4.py #현재위치가 directory이기 때문
현재위치 folder
file1.py의 경로: ..\file1.py #my로 거슬러 올라가야함
현재위치 file3.py
your의 folder: ..\folder #현재위치가 directory이기 때문
07 모듈 검색 경로
컴퓨터는 우리가 import해오라고 명령한 모듈을 어떻게 찾아낼까?
sys.path로 확인해보는 방법
import sys #스탠다드 모듈 중 하나로 파이썬 실행환경과 관련된 변수와 함수들이 저장되어있음
print(sys.path) #파이썬이 모듈을 찾아보는 경로가 저장되어 있음 값: 아래의 값들이 리스트 []안에 나옴!
1) 'C:\Users\tonia\PycharmProjects\코드잇\파이썬 모듈과 패키지 - 모듈 사용해보기 실습', 'C:\Users\tonia\PycharmProjects\코드잇\파이썬 모듈과 패키지 - 모듈 사용해보기 실습',
2) 'C:\Program Files\JetBrains\PyCharm 2024.2.1\plugins\python-ce\helpers\pycharm_display',
3) 'C:\Users\tonia\AppData\Local\Programs\Python\Python312\python312.zip',
4) 'C:\Users\tonia\AppData\Local\Programs\Python\Python312\DLLs',
5) 'C:\Users\tonia\AppData\Local\Programs\Python\Python312\Lib',
6) 'C:\Users\tonia\AppData\Local\Programs\Python\Python312',
7)'C:\Users\tonia\PycharmProjects\코드잇\파이썬 모듈과 패키지 - 모듈 사용해보기 실습\.venv',
8) 'C:\Users\tonia\PycharmProjects\코드잇\파이썬 모듈과 패키지 - 모듈 사용해보기 실습\.venv\Lib\site-packages',
9) 'C:\Program Files\JetBrains\PyCharm 2024.2.1\plugins\python-ce\helpers\pycharm_matplotlib_backend',
10) 'C:\Program Files\JetBrains\PyCharm 2024.2.1\plugins\python-ce\helpers\pycharm_plotly_backend']
sys.path의 첫파일은 무조건 지금 파이썬 파일이 있는 폴더. 즉 파이썬은 같은 폴더에 저장되었는지 찾아본다는 뜻. 이외의 경로들은 파이썬이 디폴트 경로로서, 예를들어 5)은 각종 스탠다드 모듈이 저장되어있음. 8) site-packages는 외부패키지들을 다운받아서 사용할 경우, 외부패키지들이 다운받아지는 경로이다. 즉, 다운받은 외부패키지를 모듈로 끌어올 수 있는 것은 이 경로에 있기 때문!
sys.path에 경로 추가하기
1. sys.path는 결국 리스트이기 때문에 .append() 함수를 써서 쉽게 새로운 경로를 추가할 수 있습니다. 예를 들어 sys.path에 바탕 화면의 경로를 추가하고 싶다면 아래와 같은 코드를 추가해 주면 됩니다. 단, append()해 주면 프로그램이 종료되면 그 경로는 sys.path에서 사라집니다. 그 경로에 있는 모듈을 쓰고 싶으면 매번 append()를 해 줘야 합니다.
import sys
sys.path.append('C:\\Users\\codeit\\Desktop') # Windows- 새로운 path를 영구적으로 추가하고 싶을 땐
1) PyCharm - File → Settings - Project - Project Interpreter
2) Python Interpreter 목록들을 드롭다운해서 거기서 show all 클릭
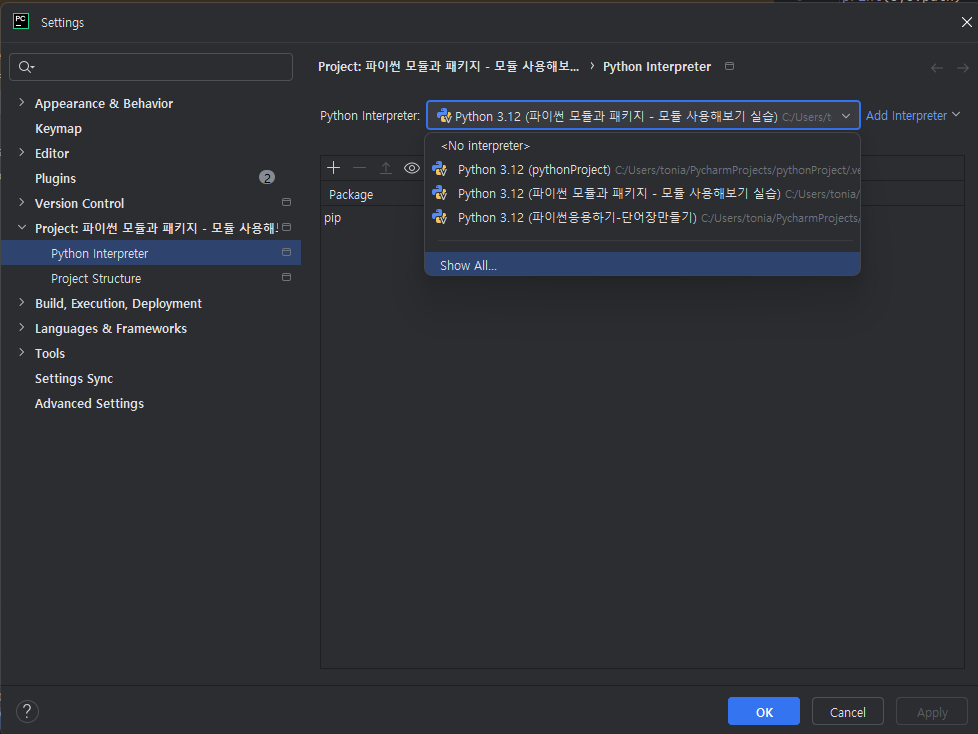
3) 좌측 상단의 파일모양 (show interpreter path) 클릭
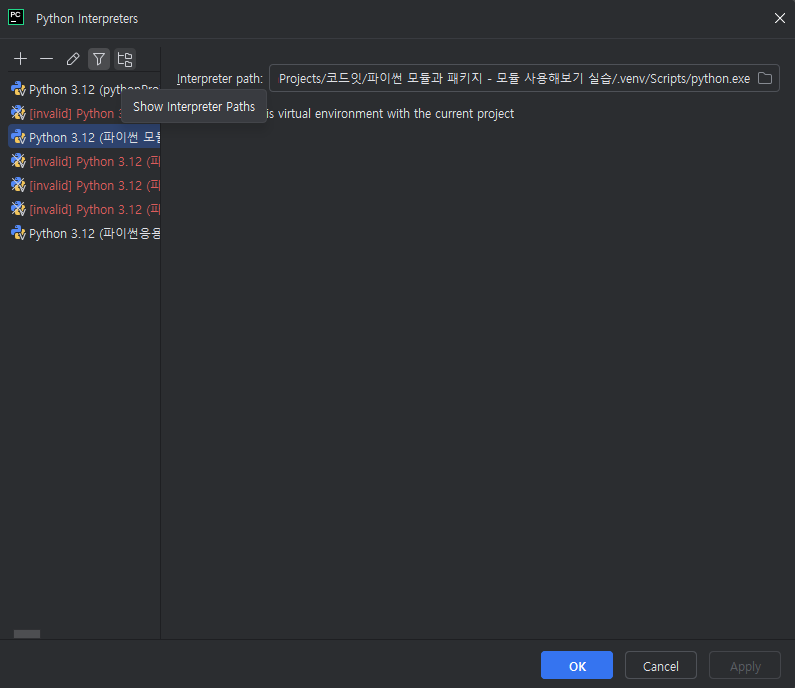
4) interpreter paths가 나열된 페이지 위의 + 눌러서 원하는 경로 선택
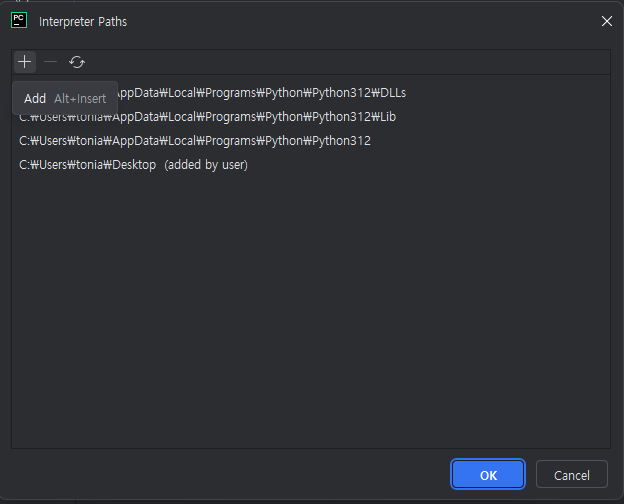
5) ok, ok, ok,
6) 확인해보기: sys.path
08 스크립트와 모듈
스크립트: 프로그램을 작동시키는 코드를 담은 실행 용도의 파일
모듈: 프로그램에 필요한 변수나 함수를 정의해놓은 파일로 여기서는 실행을 하지 않는다.
만약! 모듈에 정의만 있는게 아니라 실행이 있다면?
그 모듈을 import한 스크립트는 import와 동시에 모든 코드를 실행하는 거라 실행 코드까지 실행해버림! 이 현상을 막기 위해서는?
던더네임 사용하기
던더네임은 파이썬이 이름을 자동으로 지정해주는 변수인데, 모듈 내에서 던더네임을 물으면 main가 리턴되고, 스크립트에서 해당 모듈의 던더네임을 물으면 모듈파일명이 리턴된다.
#모듈파일명 area에서
print(f"module is {__name__}") #값: module is __main__#스크립트 파일명 run에서
print(f"script is {__name__}") #값: script is __main__
import area #값: module is are이를 활용해 조건을 걸어 모듈에서는 실행되는 명령을 스크립트에서는 실행되지 않게 만들 수 있다.
#모듈파일명 area에서
if __name__ == __main__ :
~~모듈에서만 실행하고 싶은 코드~~09 main() 함수
파이썬은 파일을 실행하면 포함된 모든 코드가 처음부터 끝까지 실행된다
하지만 Java, C, C++는 main()이라는 함수를 써야지만 그 안의 코드들이 작동된다. main()이 프로그램을 작동시키는 코드인 것이다.
Java에서 "Hello World" 출력하기; 안의 main()함수가 있어서 출력이 되는 것!
class HelloWorld {
public static void main(String[] args) {
System.out.println("Hello World!");
}
}파이썬에서도 이런 패턴을 활용할 수 있다. 던더네임과 함께!
모듈에서만 사용하고 싶은 부분을 def main()으로 정의해 놓고 그 아래 던더네임으로 main()의 출력에 제약을 걸어두는 것이다. 이 방법을 사용할 경우 모듈에서만 가동시키려는 코드가 어디에 있는지 한눈에 보여 코드의 가독성이 올라간다. 그러므로 던더네임과 함께 def main()을 활용하는 방법 적극 권장!!
#모듈명 area 파일 내
PI = 3.14
# 원의 면적을 구해 주는 함수
def circle(radius):
return PI * radius * radius
# 정사각형의 면적을 구해 주는 함수
def square(length):
return length * length
# 함수들을 테스팅 하는 메인 함수
def main():
# circle 함수 테스트
print(circle(2) == 12.56)
print(circle(5) == 78.4)
# square 함수 테스트
print(square(2) == 4)
print(square(5) == 25)
if __name__ == '__main__':
main()2. 패키지
01 패키지란
패키지 : 여러 모듈의 묶음. 예를들어 게임의 상점과 관련된 모듈들인 아이템 모듈, 거래 모듈, npc 모듈을 묶어서 상점 패키지로 만드는 것.
패키지 만드는 방법 폴더(디렉토리)를 만들고 패키지로 묶고 싶은 모듈 파이썬 파일들을 하나의 폴더에 넣고, 또하나의 파이썬 파일을 만들어 파일명을 "init"이라고 짓는다. 파이참에서 오른쪽 클릭 - NEW - Python Package를 하면 자동으로 이 이닛 파일이 생성된다.
패키지 불러오는 방법
1.import <package.module>
단, 모듈 내 함수나 변수만을 불러오기 위해 <package.module.members>을 사용하면 오류남. 이렇게 특정 함수나 변수만 가져오고 싶으면 4번 사용.
2.import
단, 이 경우 package 안에 그냥 있는 모듈들은 임포트가 안되고 "init"을 활용해야한다
3. from import <module(s)>
4. from <package.module> import <member(s)>
- import 뒤에 as를 써서 이름 바꿔주는 것도 가능!
02 init 파일이란?
"이 폴더는 패키지 폴더이다"라고 말해주는 파일
파이썬 3.3 버전 이전에는 init이 필수, 그 이후로는 필수가 아니지만
버전간의 호환과 패키지의 명확성을 위해 항상 패키지에 init 파일 만들어주기!
init = initialize
즉, 패키지를 import하면 init 파일의 코드먼저 실행됨
즉, 패키지를 초기화할때 사용됨.
위의 <package.module.members>를 가능하게 해줌
1) init 파일에 아래를 입력해두면
from package import module
2) 스크립트 파일에서 아래처럼 쓸 수 있음
import package
print(package.module.members)
((중요))특정 모듈만 더 간소화된 코드로 가져오고 싶다면
1) init 파일에 아래를 입력해두면 (여기서 package.module로 써야하는것 유의!!)
from package.module import members
2) 스크립트 파일에서 모듈명을 생략하고 아래처럼 쓸 수 있음
import package
print(package.members)
패키지 속 여러 모듈에서 똑같이 사용되는 변수와 함수들은 "init"에 저장해두면 관리에 용이해진다. 그리고 다른 모듈들에서는 from init import <변수,함수> 해주기.
init이 비어있는데 스크립트에서 import package만 넣는다? package 이름만 가고 안의 내용은 전혀 임포트되지 않는다. 이경우 반드시 init에서 어떤 것을 가져갈지 정해줘야한다. import package.module 또는 from package.module import members라고!
03 all 특수변수
all은 "패키지의 전체를 가져와!"라는 명령에서 '전체'가 무엇인지 정의해주는 특수변수 임
즉, import ''에서 ''의 범위를 결정하는 것
예를들어 그냥 ''를 사용하면 package의 모든 요소가 불려오지 않는다.
from package import #안불러와짐
package의 전체를 가져오기 위해서는
1) init 파일에 all을 정의해준다
all = ['module1', 'module2']
2) 스크립트 파일에서 '*'을 사용해서 불러온다. 그러면 all에 적용한 것들만 불러와진다.
이는 모듈 내 함수나 변수를 불러올때도 적용된다.
04 서브패키지
서브패키지 하나의 패키지에 여러 패키지가 들어가기도 하는데 그 하위 패키지가 서브패키지
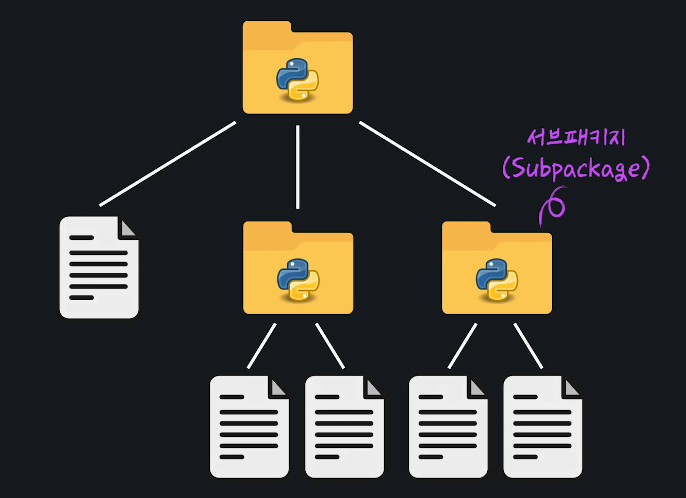
서브패키지를 가져오는 방식은 일반적인 패키지&모듈을 불러오는 방식과 동일하다
package > sub-package > modules > members 라고 했을 때, package의 init이 비어있으면 스크립트에는;
1) import package #아무것도 임포트 되지 않는다
2) from package.sub-package.modules import members
3) from package.sub-package import module
4) import package.sub-package.module #sub-package의 init파일에 module이 적혀있어야한다
-
as를 쓸 수 있다.
((중요)) 메인 package에서 가장 간결하에 members를 부르고 싶으면 package의 init에 가장 자세한 경로를 적은 from~ import~를 적을 것
예를들어 ; from package.subpackage.module import members
05 상대경로 임포트
같은 폴더안에 있는 모듈을 불러올땐
from . import module
상위 폴더 하위의 모듈과 멤버를 불러올땐
from ..module import members
상대경로의 단점은 파일 구조가 모호해진다는 점. 그러므로 좀만 길어져도 상대경로는 지양할 것
3. 외부패키지
01 외부패키지란?
좋은 개발자가 되려면 남의 코드를 잘 써야함!
남이 만들어놓은 패키지를 외부 패키지, 외부 라이브러리라고 함.
외부패키지를 사용하기 위해 알아야하는 것들
1. 패키지에 어떤 함수들이 있는지
2. 패키지의 함수들이 무엇을 하는지
이는 패키지 공식문서에 잘 정리돼있음
스탠다드 라이브러리 vs 외부 라이브러리
스탠다드 라이브러리는 프로그래밍에 필요한 가장 기본적인 기능들을 제공합니다. 스탠다드 라이브러리 안에는 자료형, 내장 함수, 스탠다드 모듈 등이 있습니다. 참고로 스탠다드 라이브러리는 패키지가 아닙니다. 여기서 '라이브러리'는 단순히 어떤 기능들의 모음을 뜻합니다. 스탠다드 라이브러리는 파이썬을 설치하면 기본적으로 딸려오기 때문에 따로 설치하지 않아도 됩니다.
외부 라이브러리 또는 외부 패키지는 파이썬을 사용하는 일반 개발자들이 패키지를 만들어서 PyPI에 업로드해 놓은 것입니다. 외부 라이브러리는 파이썬의 일부가 아니고 우리가 직접 설치해야 합니다.
02 외부 패키지 설치하기
파이썬의 공식패키지 저장소 PYPI Python Package Index
https://pypi.org/
이 기능을 위해 어떤 패키지를 써야하지? / 이 패키지는 어떻게 써야하지? 에 대한 모든 정보!
PIP PyPI에서 패키지를 다운로드해서 설치해주는 관리도구, 설치-업그레이드-삭제 모두 여기서 관리. 파이썬 3.4부터 pip이 파이썬과 같이 자동으로 설치됨
pip 설치 여부 확인 방법 : cmd에서 pip 입력해보기
pip 재설치 방법: 파이썬 제거 후 재설치
파이참으로 패키지 설치하기
1) FILE > SETTINGS
2) PROJECT: (현재 프로젝트이름) > Python Interpreter
3) +버튼누르기
4) 원하는 패키지 검색 > 우측 하단에 버전 선택 또는 선택안하면 가장 최신 버전으로 설치됨
5) 잠시 후 설치완료 메세지
6) 지우고 싶으면 -버튼으로 지울 수 있음
(중요) 외부 패키지는 프로젝트별로 추가/삭제하며 관리해야한다!
cmd에서 커멘드라인으로 패키지 설치하기
1) 설치하기 : pip3 install (패키지명)
2) 삭제하기 : pip3 uninstall (패키지명)
3) 특정 버전 설치하기: pip3 install (패키지명)==1.1.0
03 유용한 패키지
(1) 데이터 분석 & 시각화
numpy
numpy는 행렬(다차원 배열)을 다루는 패키지입니다. 데이터 분석이나 머신 러닝을 할 때는 데이터가 행렬 형식인 경우가 많습니다.
공식 홈페이지: https://numpy.org/
pandas
pandas는 데이터를 우리가 쉽게 다룰 수 있는 테이블 형식으로 만들어 줍니다. 결국 데이터 분석이나 머신 러닝을 하려면 데이터를 다뤄야 하기 때문에 pandas는 데이터 분석의 가장 핵심적인 패키지라고 할 수 있습니다. 거의 모든 데이터 사이언스 패키지들은 pandas 와 연동됩니다.
공식 홈페이지: https://pandas.pydata.org/
matplotlib
matplotlib은 파이썬에서 가장 많이 쓰이는 데이터 시각화 라이브러리입니다. 일반적인 그래프들은 거의 다 matplotlib으로 그릴 수 있습니다.
공식 홈페이지: https://matplotlib.org/
seaborn
seaborn은 matplotlib를 기반으로 한 시각화 라이브러리입니다. matplotlib 보다 간단한 문법을 사용해서 더 예쁜 그래프들을 그릴 수 있습니다.
공식 홈페이지: https://seaborn.pydata.org/
(2) 머신 러닝
sklearn
sklearn은 가장 대중적인 머신 러닝 라이브러리입니다. 기본적인 머신 러닝 알고리즘은 모두 지원합니다. 데이터 가공, 모델 평가 기능도 제공합니다.
공식 홈페이지: https://scikit-learn.org/stable/
tensorflow, pytorch, keras
모두 딥러닝에 최적화된 라이브러리들입니다. 컴퓨터 비전에 많이 사용되는 CNN (Convolutional Neural Network), 자연어 처리에 많이 사용되는 RNN (Recurrent Neural Network) 모델 등을 구현할 수 있습니다.
공식 홈페이지: https://www.tensorflow.org/?hl=ko (한국어), https://pytorch.org/, https://keras.io/
nltk
nltk는 텍스트 데이터 가공, 시각화 등을 지원하는 자연어 처리 라이브러리입니다.
공식 홈페이지: https://www.nltk.org/
(3) 웹개발
django
django는 파이썬에서 많이 쓰이는 웹 프레임워크입니다.
일반적으로 프레임워크는 어떤 소프트웨어의 뼈대 같은 역할을 합니다. 웹 프레임워크는 웹 애플리케이션을 만들기 위한 뼈대입니다. 우리는 뼈대를 제외한 나머지 디테일을 채워 넣기만 하면 됩니다.
공식 웹사이트: https://www.djangoproject.com/
flask
flask는 파이썬에서 많이 쓰이는 또 다른 웹 프레임워크입니다. django 웹 개발에 필요한 모든 기능을 제공하지만 비교적 복잡하고 flask는 기본적인 기능만 제공하지만 비교적 간단합니다.
공식 웹사이트: https://flask.palletsprojects.com/en/1.1.x/
(4) 기타
beautifulsoup4
beautifulsoup4는 html 또는 xml 문서를 파싱(원하는 데이터를 특정 패턴이나 순서로 추출해 가공하는 것)해 주는 라이브러리입니다. 보통 웹에서 원하는 데이터를 긁어 오는 작업인 웹 스크레이핑 (web scraping)에 많이 사용됩니다.
공식 웹사이트: https://www.crummy.com/software/BeautifulSoup/bs4/doc/
selenium
selenium은 웹 브라우저 동작을 자동화해 주는 패키지입니다. selenium을 사용하면 클릭, 로그인, 검색, 스크롤링 등을 자동화할 수 있습니다. 웹 애플리케이션 테스팅 자동화와 웹 스크레이핑에 많이 사용됩니다.
공식 웹사이트: https://github.com/SeleniumHQ/selenium/
가이드: https://selenium-python.readthedocs.io/
requests
requests는 파이썬의 간편한 http 라이브러리입니다. requests 라이브러리를 통해 쉽게 http 요청을 보낼 수 있습니다.
공식 웹사이트: https://requests.readthedocs.io/en/master/
opencv
(설치: opencv-python 임포트: import cv2)
opencv는 컴퓨터 비전에 많이 사용되는 라이브러리입니다. 이미지 프로세싱, 얼굴 인식, 문자 인식 등 많은 기능을 제공합니다.
공식 웹사이트: https://opencv.org
04 외부 패키지 실습 - yt_dlp
- 유튜브 영상 다운로드 : yt_dlp 파이썬에서 설치
- 파일에서 해당 패키지 import 하고 실행하기
import yt_dlp
with yt_dlp.YoutubeDL() as ydl:
ydl.download([다운받고 싶은 영상 주소])- PyPI를 보며 필요한 옵션 적용하기
05 외부 패키지 실습 - selenium
import time
import requests
from selenium import webdriver
from selenium.webdriver.common.by import By
#웹드라이버 생성
driver = webdriver.Chrome()
driver.implicitly_wait(3)
#페이지 최대화
driver.maximize_window()
# https://workey.codeit.kr/costagram 접속
time.sleep(1)
driver.get('https://workey.codeit.kr/costagram')
#로그인버튼 클릭
time.sleep(1)
driver.find_element(By.CSS_SELECTOR,".top-nav__login-link").click()
#css형식으로, ""안의 요소를 찾아서, 클릭해라!
#find_element( ).click()은 짝꿍처럼 기억하기
#ID입력
time.sleep(1.5)
driver.find_element(By.CSS_SELECTOR, ".login-container__login-input").send_keys('codeit')
# css형식으로, ""안의 요소를 찾아서, ''안의 값을 입력해라!
#find_element( ).send_keys()은 짝꿍처럼 기억하기
#비밀번호 입력
time.sleep(1.5)
driver.find_element(By.CSS_SELECTOR, ".login-container__password-input").send_keys('datascience')
#로그인
time.sleep(1.5)
driver.find_element(By.CSS_SELECTOR,".login-container__login-button").click()
# 웹 페이지 가장 밑으로 스크롤
# scrollHeight 가져오기
last_height = driver.execute_script("return document.body.scrollHeight")
#""안의 코드가 스크롤 높이 불러오는 코드
#driver.execute_script는 Selenium의 한계를 극복해 자바스크립트 코드를 실행시키는 도구
while True:
driver.execute_script("window.scrollTo(0, document.body.scrollHeight);")
#window.scrollTo가 스크롤을 아큐먼트까지 내리라는 코드
time.sleep(1)
new_height = driver.execute_script("return document.body.scrollHeight")
#끝까지 내린 후 추가 로딩되어 바뀐 스크롤 높이 규정
if new_height == last_height:
break
last_height = new_height
# 모든 썸네일 요소 가져오기
posts = driver.find_elements(by=By.CSS_SELECTOR, value='.post-list__post')
#by=By.CSS_SELECTOR: 요소를 찾는 방식을 CSS 선택자로 지정합니다
#value='.post-list__post: 찾고자 하는 요소의 CSS 클래스 이름을 '.post-list__post'로 지정합니다. 즉, HTML 코드에서 class="post-list__post" 속성을 가진 모든 요소들을 찾는다는 의미입니다.
image_urls = []
#posts 리스트에서 이미지 url에 해당하는 정보만 뽑아서 다시 리스트 만들거임
for post in posts:
# 썸네일 클릭
post.click() #**post.click()**은 Selenium WebDriver를 이용하여 웹 페이지에서 특정 요소를 클릭하는 명령입니다. 여기서 post는 .post-list__post 클래스를 가진 HTML 요소를 나타내는 WebElement 객체입니다. 즉, 이 코드는 해당 요소를 마치 사람이 마우스로 클릭하듯이 시뮬레이션하여, 그 요소가 연결된 페이지나 기능을 실행하는 효과를 냅니다.
time.sleep(1)
# 이미지 주소 가져오기
style_attr = driver.find_element(by=By.CSS_SELECTOR, value='.post-container__image').get_attribute('style') # 특정 HTML 요소의 속성 값을 가져오는 데 사용. 여기서는 style을 가져옴
image_path = style_attr.split('"')[1] #split은 특정 문자열(style_attr)에서 "을 기준으로 나눈 후 []번째 숫자를 불러오는 함수
image_url = 'https://workey.codeit.kr' + image_path
image_urls.append(image_url)
# 닫기 버튼 클릭
driver.find_element(by=By.CSS_SELECTOR, value='.close-btn').click()
time.sleep(1)
driver.quit() #이제 브라우저에서 드라이버를 사용하는 것은 끝!
# 이미지 다운받기
for i in range(len(image_urls)):
image_url = image_urls[i]
response = requests.get(image_url) #request.get은 해당 url에 접속해서 그 페이지 내용을 가져오는 기능
filename = 'image{}.jpg'.format(i) #파일 이름 동적으로 자동화~
with open(filename, 'wb+') as f: #filename의 이름을 가진 빈 바이너리 파일을 새로 만들어서 f라 지정한다.
f.write(response.content) #wite는 파일객체에 문자열을 쓰는, 즉 데이터 값을 기록하는 매서드로 f에 response의 값을 넣는 다는 뜻
#특히 response.content는 response.get으로 얻은 정보의 바이트 형태```