
1. 오토 인코더(Autoencoder)
Autoencoder는 다음과 같은 구조로 이루어져 있다.
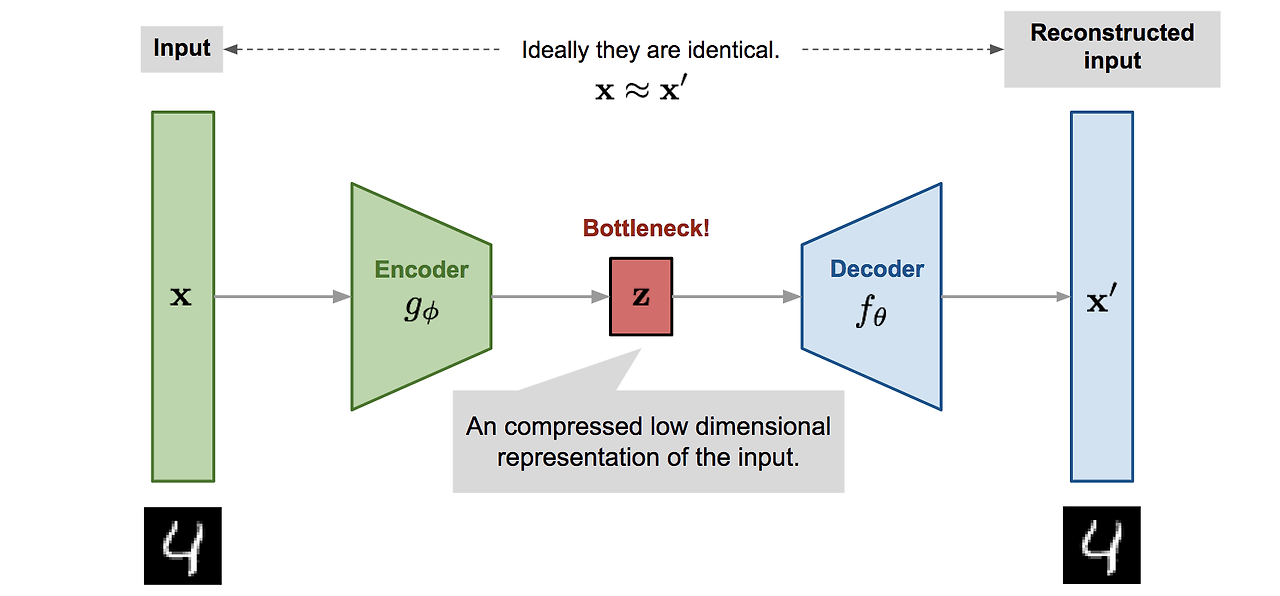
단순하게 입력에 대한 인코딩과 디코딩 작업을 수행하도록 훈련된 신경망이다.
오토 인코더에서 중요한 개념은 딱 세 가지이다.
1. 인코더(encoder)
2. 잠재 공간(latent space)
3. 디코더(decoder)
먼저 인코더는 이미지 같은 고차원 입력 데이터를 저차원 임베딩 벡터로 압축하는 역할을 한다.
쉽게 말해서 픽셀값으로 이루어져 있는 입력 데이터를 어떠한 이미지적 특징(ex. 사람의 눈, 고양이의 귀, 질감 등등)을 가지도록 차원을 축소시키는 것을 의미한다. 28 * 28 크기의 이미지의 픽셀은 총 784개이다. 픽셀값 기준으로 784차원으로 표현된 이 이미지를 어떠한 특징의 저차원으로 축소시키겠다는 의미로 받아들일 수 있다.
인코더를 통해 나온 저차원 임베딩 벡터는 잠재 공간 안에 존재한다.
임베딩은 원본 이미지를 저차원 잠재 공간으로 압축한 것이기 때문이다.
이 잠재 공간에서 임의의 포인트를 선택하여 디코더에 통과시키면 새로운 이미지가 생성되는 것이다.
원래의 이미지를 재구성하는 데 이미 가지고 있는 이미지와 동일하지 않으면서 재구성하는 데 필요하다.
디코더는 잠재 공간의 한 포인트를 유효한 이미지로 변환하는 방법을 학습하여, 새로운 이미지를 생성하는 역할을 한다.
이러한 구조를 통해 새로운 이미지를 만들어 낼 수 있는 것이다.
하지만 이에 문제가 있다.
잠재 공간의 한 포인트에 직접 매핑되기 때문에 빈 공간에 대한 이미지 생성 품질이 극히 안 좋아질 것이다.
오토인코더가 이미지를 인코딩할 때 비슷한 이미지끼리 그룹이 생길 것이고 그룹간의 사이에서 생성한 이미지가 좋을 것이라고 기대하기 어려워진다.
이를 해결하고자 나타난 것이 변이형 오토인코더(Variational AutoEncoder: VAE)이다.
2. 변이형 오토인코더(VAE)
오토인코더가 이미지를 잠재 공간의 한 포인트에 직접 매핑하는 것 대신, 변이형 오토인코더는 이미지를 잠재 공간에 있는 포인트 주변의 다변량 정규분포에 매핑한다.
즉, 변이형 오토인코더는 잠재 공간의 '확률적 분포'를 학습하여 이산적으로 매핑되어 이미지 생성 성능이 낮아지는 문제를 해결한다는 것이다.
평균이 µ이고 표준 편차가 𝞼인 정규 분포에서 포인트 Z를 샘플링하는 데 다음과 같은 공식이 사용된다.
Z = µ + 𝞼𝟄
이를 위해 인코더는 각 입력을 평균 벡터(µ역할)와 분산 벡터(𝞼역할)에 매핑하면 된다.
이때 잠재 공간에서 차원 간 상관관계가 없다고 가정하기 때문에 차원 간 공분산을 신경 쓸 필요가 없다고 한다.
또한 분산의 값은 항상 양수여야 하기 때문에 분산의 로그에 매핑하도록 하는 것에 주의해야 한다.
즉, 인코더는 입력 이미지를 받아 잠재 공간의 다변량 정규 분포를 정의하는 2개의 벡터로 인코딩하는 역할을 한다.
2개의 벡터는 다음과 같다.
- z_mean = 분포의 평균 벡터
- z_log_var = 차원별 분산의 로그 값
위의 샘플링 공식에 의하여
Z = z_mean + exp(z_log_var 0.5) epsilon
과 같이 대입할 수 있다.
이 때 epsilon은 표준 정규 분포에서 샘플링된다. epsilon ~ N(0,I)
디코더 부분은 오토인코더와 동일하다.
지금까지의 내용으로 변이형 오토인코더의 구조를 보면 다음과 같다.
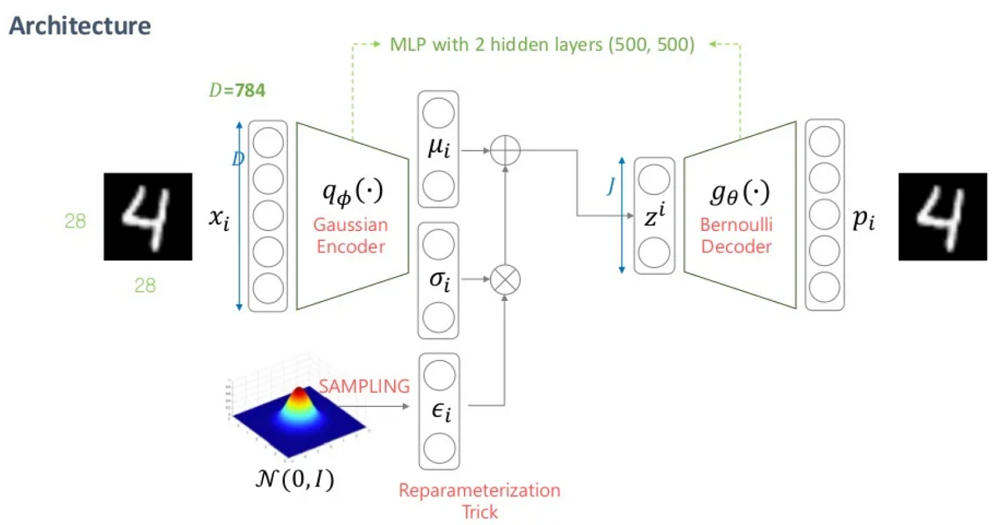
변이형 오토인코더와 오토인코더가 가지는 차이는 손실함수에서도 차이가 있다.
오토인코더는 인코더와 디코더를 통과한 출력과 원본 이미지의 차이인 Reconstuction loss만 계산했다.
하지만 변이형 오토인코더는 인코더가 가지는 정규 분포와 표준 정규 분포와 얼마나 다른지 측정해야 하므로 Kullback - leibler divergence(KL divergence)를 더하여 사용한다.
쿨백 라이블러를 사용하는 이유에 대해 개괄적으로 설명하면, KL divergence는 샘플을 표준 정규 분포에서 크게 벗어나는 z_mean, z_log_var 변수로 인코딩하는 네트워크에 벌칙을 가하는 역할을 하기 때문이다.
이는 reconstuction이미지가 원본과 잘 맞는지도 판단하면서 인코딩 과정에서 z_mean, z_log_var가 표준 정규 분포를 따르게 함으로써 정규 분포에 매핑되도록 하는 역할을 하는 것이다.
References
[1] 논문: Variational Autoencoder(VAE) (Kingma et al. 2014), https://arxiv.org/abs/1312.6114
[2] VAE 영상 자료: https://youtu.be/rNh2CrTFpm4
