혹시 사피어-워프 가설에 대해서 아시나요? 사피어-워프 가설은 한 사람이 세상을 이해하는 방법과 행동이 그 사람이 쓰는 언어의 문법적 체계와 관련이 있다는 언어학적 가설입니다. 증명하기 어려운 성질을 가진 가설이기 때문에 현대에서 과학적으로 인정받지는 못했지만, 저는 여전히 어떤 사람을 이해하기 위해서는 그 사람이 쓰는 언어를 먼저 이해해야 한다고 생각합니다.
컴퓨터공학에 관련된 글을 쓰면서 왜 뜬금없이 언어학 이야기를 하는지 궁금하신 분도 계실 것 같습니다. 간략히 설명드리자면 저는 좋은 코드를 짜기 위해서 컴퓨터를 이해할 필요성을 느꼈고, (컴퓨터가 사람은 아니지만) 컴퓨터를 이해하기 위해서는 컴퓨터가 어떤 언어를 사용하는지 공부할 필요가 있다고 판단했습니다.
이번 포스팅에서는 컴퓨터가 정보를 어떻게 이해하는지, 그 중에서 특히 문자를 어떻게 이해하는지를 중점적으로 다루겠습니다. 한빛미디어의 혼자 공부하는 컴퓨터 구조+운영체제를 참고했고, 저와 같은 컴퓨터공학 초심자가 읽기에 아주 좋은 책이니 관심이 있으시면 링크를 클릭해서 한번 살펴보셔도 좋을 것 같습니다. (광고같지만 내돈내산)
그래서 컴퓨터는 어떤 언어를 쓰나요
때는 워드프로세서를 공부하던 초등학교 저학년 시절. 컴퓨터는 0과 1로 이루어져... 어쩌고저쩌고 하는 말을 얼핏 들었던 기억이 있습니다. 제가 최근 공부해보니 이는 사실로 밝혀졌습니다. 컴퓨터는 0과 1로 정보를 표현하고, 0과 1로 표현된 정보만 이해할 수 있었습니다.
이러한 컴퓨터의 특징 때문에 인간과 컴퓨터가 소통하기 위해서는 0과 1을 십진법의 숫자로, 혹은 인간이 이해할 수 있는 문자로 변환하는 과정이 필요합니다. 컴퓨터는 0과 1밖에 모른다면서 어떻게 2나 3 혹은 더 큰 숫자를 인식해서 연산까지 척척 수행해내는 것일까요? 0과 1로 한글 이나 english 같은 문자는 어떻게 표현하는 것일까요?
컴퓨터는 숫자를 어떻게 이해하나요
컴퓨터가 이해하는 가장 작은 정보 단위
컴퓨터가 숫자를 어떻게 이해하는지 살펴보기 위해 우선 컴퓨터가 이해하는 가장 작은 정보 단위부터 알아보겠습니다. 0과 1을 나타내는 가장 작은 정보 단위를 비트(bit) 라고 합니다. 혼자 공부하는 컴퓨터 구조+운영체제(이하 혼공컴운)에서는 비트를 전구에 빗대어 설명하고 있는데요, 전구 한 개로 꺼짐 혹은 켜짐 두 가지 상태를 표현할 수 있듯 비트는 0 또는 1의 두 가지 정보를 표현할 수 있다는 것입니다.

따라서 1비트는 두 가지 상태를 표현할 수 있고, 2비트는 네 가지 상태, 3비트는 8가지, 4비트는 16가지... 비트가 커질수록 표현할 수 있는 상태의 가짓수가 많아집니다. 즉 n비트는 2의 n승만큼 정보를 표현할 수 있습니다.
VS Code, Slack 등의 프로그램은 다양한 기능을 포함하고 있기 때문에 프로그램의 크기도 상당히 큰 편입니다. 한 프로그램이 수십만, 수백만 비트로 이루어져 있다는 뜻이죠. 이런 상황에서 크기의 단위가 비트만 존재한다면 표현하기 좀 곤란하겠죠? 오늘날 우리가 흔히 사용하는 킬로바이트, 메가바이트, 기가바이트, 테라바이트 등의 단위는 이러한 맥락에서 등장한 것입니다.
0과 1만으로 숫자를 표현하는 방법
컴퓨터가 이해하는 가장 작은 정보 단위에 대해서 살펴보았으니, 컴퓨터가 숫자를 표현하는 방법에 대해 얘기해 보겠습니다.
수학에서 0과 1만으로 모든 숫자를 표현하는 방법을 이진법이라고 합니다. 우리가 흔히 사용하는 0~9까지의 숫자를 가지고 9보다 숫자가 커질 때 자리올림을 하는 방법을 십진법이라고 하는데요, 이진법은 숫자가 1보다 커질 때 자리올림을 한다고 생각하면 쉽습니다. 십진법 숫자를 이진법으로 바꾸면 2는 10, 3은 11이 됩니다.
그렇다면 십진법 숫자와 이진법 숫자는 어떻게 구분할까요? 보통 표현하고자 하는 숫자가 십진법으로 쓰이지 않았을 경우 101(2), 1D(16)처럼 숫자 뒤에 괄호를 붙여 표현합니다. 101(2)는 이진법,1D(16)는 십육진법으로 표현한 것이지요.
이진법은 표현해야 할 숫자의 크기가 커질수록 자릿수가 기하급수적으로 늘어나는 단점이 있기 때문에 십육진법과 함께 사용하기도 합니다. 아니 도대체 왜 (저를 비롯한 인간들이 이해하기 쉬운) 십진법을 쓰지 않는지 의문이 들었지만 이진법 <-> 십육진법 사이의 변환은 아주 쉬운 반면 이진법 <-> 십진법 변환은 어렵기 때문이라고 하네요.
마지막으로 다소 충격적인 사실을 알려드리자면 컴퓨터는 -(마이너스) 부호를 이해하지 못하기 때문에 음수도 이진법으로 표현해야 합니다.(진짜로 0과 1밖에 모름) 그 방법으로는 2의 보수를 구해 음수로 간주하는 방법이 있는데, 쉽게 표현하면 '모든 0과 1을 뒤집고, 거기에 1을 더한 값'이라고 정리할 수 있습니다.
컴퓨터는 문자를 어떻게 이해하나요
개인적으로 컴퓨터가 숫자를 이해하는 방식은 공부하기 전에 살짝 예측이 가능했었는데, 문자를 이해하는 방법은 도저히 떠오르지 않았습니다. 과거에 이 문제에 직면한 개발자들이 어떤 방식으로 해결했는지 알아보겠습니다.
문자 집합, 인코딩, 그리고 디코딩
컴퓨터가 인식하고 표현할 수 있는 문자의 모음을 문자 집합이라고 합니다. 문자 집합 안에 있는 문자라고 바로 이해할 수 있는 건 아니고 0과 1로 변환하는 과정이 필요한데 이것이 인코딩입니다. 인코딩 후에는 문자가 0과 1로 이루어져 있기 때문에 인간이 이해할 수 없습니다. 인코딩된 문자를 다시 사람이 이해할 수 있는 문자로 변환하는 과정을 디코딩이라고 합니다.
문자 집합, 인코딩, 디코딩. 이렇게 세 가지가 컴퓨터가 문자를 이해하는 데 핵심적인 역할을 하는 요소입니다. 개발자들은 컴퓨터가 문자를 이해할 수 있도록 문자 집합을 정의하고, 인코딩 방법을 개발했습니다. 그럼 한국을 중심으로 문자 집합과 인코딩 방법이 어떻게 발전했는지 살펴보겠습니다.
아스키 코드
아스키(ASCII: American Standard Code for Information Interchange) 코드는 1960년대 미국 ANSI에서 표준화한 정보교환용 7비트 부호체계입니다. 영어 알파벳과 아라비아 숫자, 일부 특수문자를 포함하며 총 128개의 문자를 표현할 수 있습니다.
7비트 부호체계이지만 실제로 아스키 문자를 나타내기 위해서는 8비트가 사용됩니다. 이 나머지 1비트는 패리티 비트(Parity Bit)라고 불리며, 코드의 오류 검출을 위해 쓰입니다.
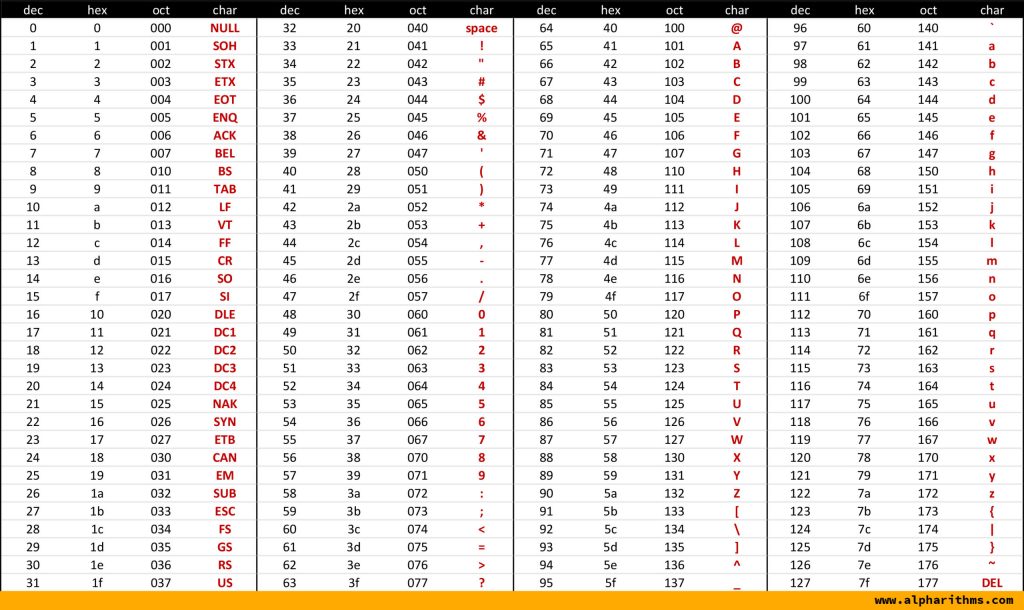
위의 아스키 코드 표를 보면 알 수 있듯이 아스키 문자들은 아스키 코드와 1대 1로 대응합니다. 128개 문자를 표현한다는 부분에서 이미 예상하신 분들도 있겠지만 당연하게도 한글을 표현할 수 없고, 128개 문자에 속하지 못한 글자나 특수문자를 표현할 수 없다는 단점이 있습니다. 따라서 영어권 외의 나라들은 아스키 코드 외에 자신들의 언어를 나타낼 수 있는 인코딩 방식이 필요했고 한국에서는 EUC-KR이 출범하게 됩니다.
EUC-KR
저는 평소에 폰트에 관심이 많아서 VS Code를 사용할 때도 주기적으로 폰트를 바꿔 가며 사용합니다. 그런 제가 폰트를 다운로드 받을 때마다 하는 생각은 '영어는 폰트 만들기 정말 쉽겠네'라는 건데요. 26개 알파벳 대소문자와 일부 특수문자만 만들면 되는 영어 폰트와는 달리 한글 폰트는 생각만 해도 복잡합니다. 그래서 대부분의 폰트가 꿹뚧땗쌟과 같이 자주 쓰이지 않는 글자는 지원하지 않죠.
한글 인코딩도 이와 마찬가지로, 초성, 중성, 종성의 조합으로 이루어진 한글의 특징으로 인해 완성형과 조합형 인코딩 방식이 등장하게 되었습니다.
완성형 인코딩 방식은 하나의 글자에 고유한 코드를 부여하는 방식으로, '가'는 1, '나'는 2, '다'는 3 같은 식으로 인코딩 하는 방식입니다. 반면 조합형 인코딩 방식은 초성, 중성, 종성 각각을 위한 비트열을 할당하여 이를 조합해 하나의 코드를 완성합니다.
EUC-KR은 완성형 인코딩 방식을 사용했습니다. 총 2,350개 정도의 한글 단어를 표현할 수 있지만 EUC-KR의 문자 집합에 쀍같은 글자는 정의되지 않았습니다. 쀍 같은 글자는 평소에 잘 쓰이지 않으니 별 문제될 것이 없을 것 같지만 예상하지 못한 곳에서 오류가 나는 등 피해가 발생하면서 EUC-KR의 확장 버전인 마이크로소프트의 CP949가 등장했으나, CP949도 한글 전체를 표현하기에는 역부족이었습니다.
유니코드
EUC-KR는 모든 한글을 표현할 수 없다는 한계가 있었고, 그와는 별개로 언어별로 인코딩을 할 경우 다국어를 지원하는 프로그램을 만들 때 각 나라 언어의 인코딩을 모두 알아야 하는 문제가 있었습니다. 당연하게도 개발자들은 모든 언어의 문자 집합과 인코딩 방식을 통일하면 좋겠다는 생각을 했고 이 과정에서 탄생한 것이 유니코드입니다.
유니코드는 대부분 나라의 문자, 특수문자, 이모티콘까지도 표현할 수 있기 때문에 현대에 가장 많이 사용되고 있는 표준 문자 집합입니다.
아스키 코드나 EUC-KR은 글자에 부여된 값을 그대로 인코딩 값으로 삼았는데, 유니코드는 그 방식이 조금 다릅니다. 글자에 부여된 값 자체를 인코딩된 값으로 삼지 않고 이 값을 다양한 방법으로 인코딩하는데, 이 방법에 따라 크게 UTF-8, UTF-16, UTF-32 등으로 나뉩니다.
 CRA로 생성한 리액트 프로젝트의 index.html 파일. utf-8 방식으로 인코딩 되어있다.
CRA로 생성한 리액트 프로젝트의 index.html 파일. utf-8 방식으로 인코딩 되어있다.
이 중에서 가장 많이 사용되는 방식은 UTF-8로, 아스키 코드 값을 그대로 보존하는 방식이라 호환성이 가장 좋습니다. 유니코드를 사용하는 프로그램에서 방식이 따로 명시되지 않았을 경우 UTF-8이라고 보아도 무방합니다.
마치면서
책을 읽을 때는 채 30분이 걸리지 않았던 파트이지만 직접 글을 작성하니 거의 반나절이 걸리는군요. 요즘 공부의 효율성에 대해 생각이 많은데, 흘러가듯 학습한 것들은 흘러가듯 잊히는 것 같습니다. 그래서 한 번 정한 주제가 있으면 진득하게 파고들고자 합니다.
오늘은 컴퓨터가 이해하는 언어 0과 1, 그리고 그 언어로 인간이 이해하는 숫자와 문자를 어떻게 표현할 수 있는지 알아보았습니다. 책의 목차를 살펴보니 오늘 다룬 부분은 컴퓨터가 이해하는 '데이터'에 대한 부분이고, 다음 챕터에서 컴퓨터가 이해하는 '명령어'에 대해서 다룬다고 합니다.
앞으로도 혼공컴운을 읽으며 글을 쓰고 싶은 주제가 생기면 시리즈로 찾아뵙겠습니다. 오늘도 끝까지 읽어주셔서 감사합니다.
