
(이번 글은 제 생각이 많이 포함되어 있으며 틀린 내용이 있을 수 있습니다. 틀린 부분 지적해주세요..!)
정보 출처: [https://blog.cleancoder.com/uncle-bob/2012/08/13/the-clean-architecture.html](https://blog.cleancoder.com/uncle-bob/2012/08/13/the-clean-architecture.html)개요
클린 아키텍처란 무엇일까? 자기소개서에 클린 아키텍처를 지향한다고 했었지만 막상 클린 아키텍처에 대한 이해도가 적었던것 같다. 이번 포스트는 클린 아키텍처에 대해 기록함과 동시에 내 생각을 더해보려고 한다.
내가 생각한 "클린"이란 단어는 짧고 보기 쉬운 로직으로 되어 있는 것을 전제로 한다고 생각한다. 하지만 더욱 더 큰 프로젝트를 접할수록 클린과는 거리가 멀어져가는 내 코드들을 볼 수 있었다. 대부분의 개발자들도 이를 경험했을 것이며 코딩이란 땅의 첫 개척자들은 고생을 꽤나 했을거 같다.
그렇다면 그 개척자들은 어떤 생각을 하였을까? 제일 먼저 나온 개념이 뭔지는 몰라도 지금과는 다를것이다. 왜냐하면 지금은 그 당시보다 더 복잡하고 방대한 기능 및 서비스를 제공하기 때문이다.
뭐 어찌됐든 좋은 코드, 좋은 구조는 항상 바뀔 수 있다는 것이다. 그렇기 때문에 나는 아키텍처에 대해 공부할때 그 당시 상황을 생각해본다. "문제 발견 - 해결" 이 두가지를 간결히 생각해보거나 알아보는 것만으로도 그 아키텍처의 핵심내용을 이해하는데 큰 도움이 된다고 생각한다.
많은 아키텍처의 개념이 구축되어 왔지만 그들의 공통점은 다음과 같다.
1. 각 프레임워크의 독립성
2. testable 추구
3. 레이어 분리 및 독립성 확보
즉, 각 레이어 또는 모듈마다 독립성을 확보하여 유닛테스트를 가능하게 만들고 독자적으로 이용가능하게 만드는 것이다.
그래서 Clean Architecture가 뭔데?!
현재의 어플리케이션은 수많은 기능을 제공한다. 많은 기능이 있더라도 "DataSource에서 Data를 얻어 앱 화면에 띄우고 사용자와의 상호작용에 따라 그에 맞는 기능을 제공한다" 라는 심플한 흐름이 다 일것이다. 이런 상황 속에서 Clean Architecture는"데이터의 단방향 흐름"을 중요시한다.
내 경험상 양방향으로 데이터가 흐를때의 문제는
1. 데이터가 사용자의 상호작용으로 부터 온것인지 DataSource로부터 온것인지 모른다.
2. 데이터 흐름의 양쪽에 낀 객체(즉, UI와 DataSource 두 방향에서 오는 데이터를 처리해야 하는 객체)는 어디서 다뤄야 하는가?
등이 있었다.
확실히 데이터 흐름을 단방향으로 고정하니 객체지향의 개념이 명확해지고 논리의 흐름을 확인하기 쉬웠다. 하지만 이 객체지향은 대부분의 아키텍처가 가지고 있는 개념이며 생각을 분리시켜 개발자로 하여금 개발 자체에 집중할 수 있게 해준다.
팀원의 모듈을 이용하는 하는 경우, 그 모듈의 메소드를 이해하고 이용해야 한다. 그렇기 때문에 해당 메소드나 클래스의 이름이 수행하는 역할을 직접적으로 표현할 수 있어야 한다고 한다. UseCase가 그 예시일 것이다. operator invoke를 이용하여 한 역할만을 수행하고 이름을 통하여 역할에 대해 명확히 알 수 있다.
Clean Architecture는 이를 Dependecy Inversion으로 해결한다. 고레벨 모듈은 저레벨 모듈에 의존해서는 안되고 두 모듈 모두 추상성에 의존해야한다는 뜻인데... 솔직히 이해가 전혀 안된다!
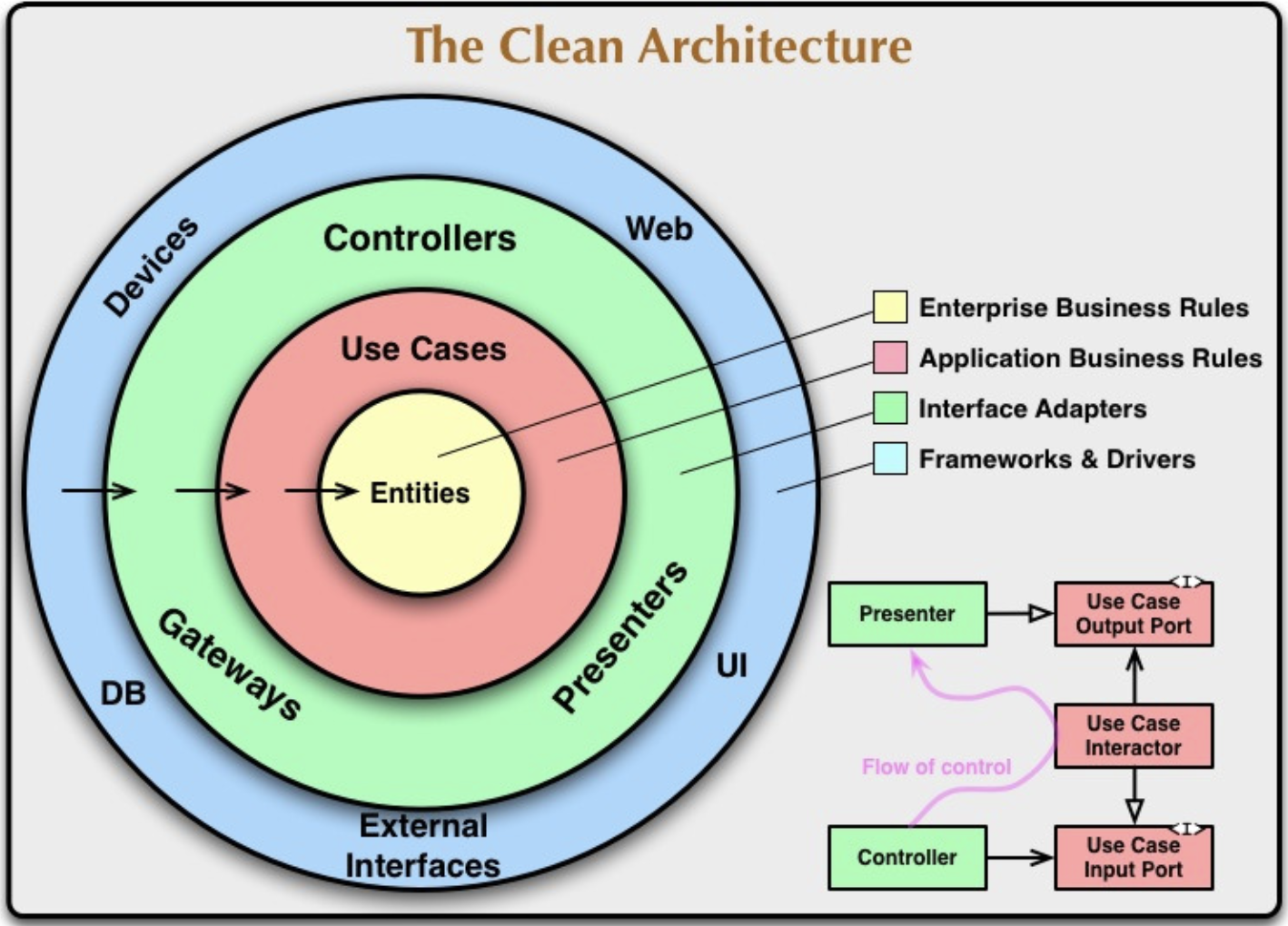 출처 https://blog.cleancoder.com/uncle-bob/2012/08/13/the-clean-architecture.html
출처 https://blog.cleancoder.com/uncle-bob/2012/08/13/the-clean-architecture.html
Clean Architecture의 다이어그램이다. 제일 바깥부터 interface, controller, use case, entity로 되어있고 바깥 개념이 안쪽 개념을 품는 식으로 표현되어 있다.
각 Circle 설명
- Entity: 업무에 필요한 데이터를 정리하고 다루기 위해 만든 독립체로, 가능한 수정되지 않아야 한다. 중요한 역할은 기업의 Business Rule을 서술하고 매우 추상적이다. 메소드를 가진 객체나 데이터 구조를 가진 세트로 표현될 수 있다. DB에서 말하는 Entity는 이와 다른 개념이다. 서버에서는 기업의 Business Rule Entity의 일부 속성을 가져와 DB에 Table의 형태로 정의하는 것이다. 즉, Android의 Room Entity를 정의할때나 서버에서 Entity를 정의할땐 Business Rule Entity에서 필요한 속성을 가져와 메소드를 추가하여 이용하는 것이다.
- UseCase: 시스템의 동작을 사용자의 입장에서 풀어쓴 시나리오이며, Business 로직을 감싸는 역할을 한다. 또한 개발자는 UseCase의 바깥 원에서 해당 Class의 이름만을 보고 어떤 동작을 하는지 쉽게 파악할 수 있다.
- Interface Adapters: 외부 내부 데이터들을 이용하기 쉽게 바꾸는 작업을 한다. 즉, 받은 데이터를 use-case 또는 entity가 이용하기 좋은 포맷 또는 어떤 persistence framework가 이용하기 쉬운 포맷으로 바꾼다는 것이다. MVC 구조를 가지고 있으며 View<-Model(data)->Controller 식으로 되어있다. 제일 많은 코드를 필요로 하는 레이어인거 같다.
- FrameWorks & Drivers: DB나 Web 등과 같은 Framework 및 tool들로 이루어져 있으며 많은 코드를 쓰지 않고 그저 잇는 역할만을 수행하면 된다. 예를 들어 Web View에 정보를 띄우거나 DB에서 원하는 데이터를 가져오는 것이 있다. 하지만 의문이 든 점이 있었는데...
Dependency Rule
Clean Architecture가 작동하기 위한 기본적인 개념이다. 안 쪽 Circle일수록 추상적이고 바깥쪽으로 갈수록 구체적이다. R.C. Martin의 표현을 그대로 하면 안쪽 Circle은 policies고 바깥쪽 Circle은 Mechanisms이다. 그렇다면 policies와 Mechanisms는 무슨 뜻일까?
policies는 우리 말로 정책이라는 뜻이다. 그러니깐 위에서 말한 Business Rule은 해당 앱을 다스린다. 즉, 앱은 기업의 Business Rule을 기반으로 작동하며 앱이 해야할 것과 하지 말아야 할 것을 정의한다고 할 수 있다. 반대로 Mechanisms는 policies를 이용하기 위해 구체적으로 tool, framework, library를 참조하여 구현하는 것을 목표로 한다. 즉, policies를 전달하는 역할을 한다고 할 수 있다. 그렇기 때문에 FrameWorks & Drivers에 적은 코드가 필요한 것이다.
또한 매우 중요한 특징이 하나 있는데, 바로 Source Code Dependency는 안으로만 향한다는 것이다. 안쪽 Circle은 바깥쪽 Circle의 어떠한 Field도 알지 못해야 하며 data format도 마찬가지이다. 하지만 추상화를 통해 이용해도 된다. 바깥 원에서 implement된 interface의 이용이 가능하다는 것이다. 즉, 특정한 implement에 종속되는 것이 아닌 바깥 원에서 implemnt한 객체를 통해 안쪽 원에 종속성을 주입하는 것이다. 예를 들면 repository에 의존하는 usecase를 만들때, GetEmailUseCase(emailRepo: EmailRepository)로 생성자를 정의한다. 또한 EmailRepository는 interface이며 그 안에 선언된 함수로 비즈니스 로직을 use case 안에 작성한다. 해당 EmailRepository interface가 implement된 객체는 바로 바깥 원(보통: viewmodel)에서 EmailRepositoryImpl를 생성하여 주입한다.
(이 의존성을 주입하기 위해 impl된 객체들을 자동으로 만들어주는 것이 DI 툴이며 Android에서는 Hilt, Dagger, Koin 등이 있다.)
의문. Present-Domain-Data 레이어와 Clean Architecture Circle 레이어는 무슨 관계인가?
공부하면서 계속 이해하기가 어려웠다. 둘이 1대1로 매치되는 관계라 생각했기 때문에 다른 개념들이 계속 팅겨져나갔었다.
(출처:https://medium.com/@aboutcoding/clean-architecture-the-essence-of-the-dependency-rule-969f1e8417f6)
위 글에서 읽은 내용이다. 개요 부분을 요약하자면 다이어그램을 보고 폴더 구조적인 계층으로 생각하는 개발자들이 많았고 Clean Architecture의 다이어그램은 Dependecy의 흐름에 따라 Shorcut으로 만들었다는 것이다. Present-Domain-Data 레이어는 보통 폴더 구조를 나눠 관심사항을 분리시킨 것에 가까운거 같고, 다른 하나는 Dependency 관리를 위한 layer라는 것이다. Present-Domain-Data 레이어 구조가 Clean Architecture에서 온 것이기 때문에 데이터나 dependency의 흐름을 엿볼 수 있다.
Present-Domain-Data 레이어와의 관계 이어보기
현업 Android에서 제일 크게 폴더를 나눌때 Present-Domain-Data로 나누고 있는거 같다.
Present
- Activity, Fragment: interface adpater의 Presenters에 해당
- DI를 위한 hilt: Frameworks & Drivers에 해당한다.
Domain
- Use Case: 당연히 Application Business Rule 중 Use Case에 해당
Data
- Data Source: Frameworks & Drivers 중 DB 또는 External Interface에 해당. API가 External Interface에 포함된다.
- Repository: interface adpater 중 IO를 관리하는 GateWay에 해당한다.
Models
: 이들은 모든 Circle에 존재할 수 있다. 서버의 DB와 통신하여 얻은 Dto, Room에 저장하는 Entity, Circle 간 데이터 이동을 위한 format들이 그 예이다.
마무리
정리를 하면서 헷갈렸던 내용들이 많이 해결이 되었다. 특히, 서버에서의 Entity와 Clean Architecture가 말하는 Entity를 완전히 같다고 생각하여 이에 대한 자료를 서칭하는데 시간이 오래 걸렸다.
하지만 그만큼 이해하는데 큰 도움이 되었으며 말로만 들었던 DIP(Dependency Inversion Principle)에 대해 차분히 고민해보는 시간이 되었다. Clean Architecture를 고안한 R.C Martin이 낸 Clean Architecture: A Craftsman's Guide to Software Structure and Design을 번역한 책도 있으니 한번 읽고 다시 추가로 정리해보아야 겠다.
