🏅 Goal
Character encoding에 대해 이해한다.
🌱 캐릭터셋(character set, 문자집합)
글자나 기호들의 집합을 정의한 것이다.
아스키(ASCII)와 같이 문자가 추가될수 없는 것과 유니코드(Unicode)와 같이 문자가 추가될 수 있는 것이 존재한다.
ASCII (American Standard Code for Information Interchange)
유니코드는 현존하는 문자인코딩 방법들을 유니코드로 교체하는 것이 목적이며 XML이나 자바 운영체제등에서도 지원한다.
캐릭터셋의 중 아스키(ASCII)라는 캐릭터셋은 아래와 같이 나열되어 있다.
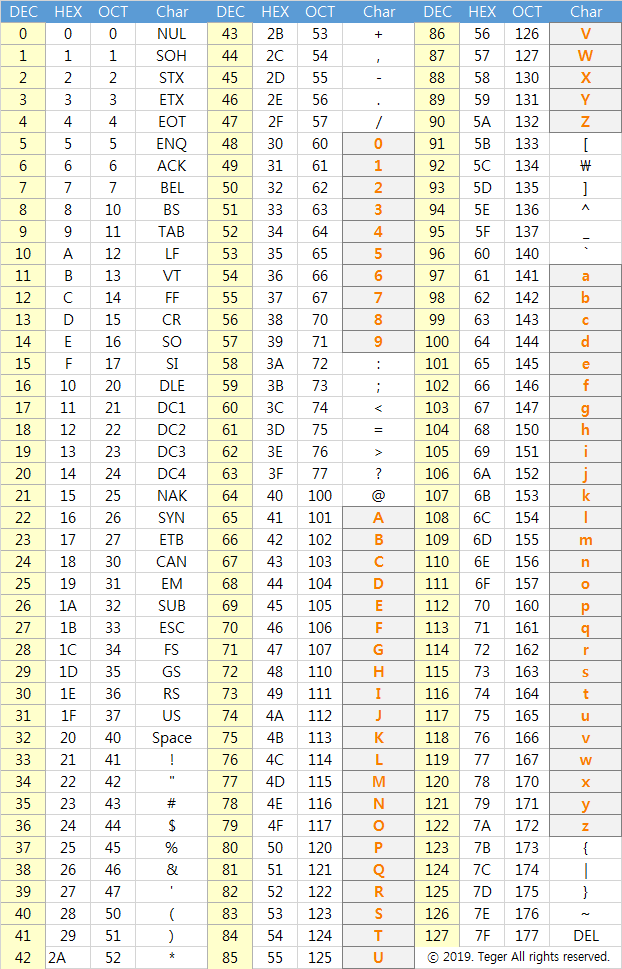
보이는 봐와 같이 null 부터 중간에 영문, 숫자.. 그리고 del 까지 일련의 순서를 만들어 놓았으며 그걸 ASCII라는 이름의 캐릭터셋이라 부르고 있다.
이때, 문자를 주고받을 필요성이 있는 누구들이(또는 무엇들이) 서로 이 ASCII 캐릭터셋을 알고, 문자를 주고 받자고 약속했다면 A라를 문자를 보내기 위해 알고있는 번호인 10진수 65를 보내면 좋겠다.
이는 사람에게는 불편하지만 기계들에게는 매우 효율적인 방법이다.
'A'기계에서 'B'기계에게 65라는 수치를 전송한다고 하면 기계입장에서는 컴퓨터는 많은 일을 할수 있지만 기본은 1과 0밖에 모르는 때문에 '1000001'을 보내는 것으로 상호 같은 문자로 인식할 수 있을 것이다.
(65는 16진수로는 41, 2진수로는 '1000001' )
이렇게 영어는 표현하기 쉽다. 하지만 한글은 사람에게는 배우기 쉬은 글이지만 시스템으로 표현하기에는 어려움이 있어 보인다.
🌲 문자 인코딩( Character Encording )
사전적인 의미로는 문자들의 집합을 부호화하는 방법이라고 되어 있다.
특정 문자열등을 어떤 하나의 캐릭터셋의 숫자형태의 나열로 변경하는 것을 인코딩(encoding, 부호화) 이라고 하고 반대의 경우인 숫자형태의 나열을 문자열 형태로 만드는 것을 디코딩(decoding,복호화) 이라고 한다.
캐릭터셋과 인코딩은 동의어로 사용되는 경우가 많다.
🌱 EUC-KR
완성형이라고 불리우는 한글 인코딩 방식이다.
한국산업규격으로 지정된 정보교환용부호( KS X 1001, KS X 1003) 계열의 인코딩방식으로 모든 현재 한글을 표현할수 없다라는 단점이 있다.
🌱 UTF-8
조합형이라고 불리우는 한글 인코딩 방식이다.
유니코드를 위한 가변 길이 문자 인코딩으로 문자를 나타내기 위해 1바이트에서 4바이트까지 사용한다.
현재 많은 부분에서 본 인코딩방식을 사용하고 있다.
🌱 Reference
