모음 사전
문제 설명
사전에 알파벳 모음 'A', 'E', 'I', 'O', 'U'만을 사용하여 만들 수 있는, 길이 5 이하의 모든 단어가 수록되어 있습니다. 사전에서 첫 번째 단어는 "A"이고, 그다음은 "AA"이며, 마지막 단어는 "UUUUU"입니다.
단어 하나 word가 매개변수로 주어질 때, 이 단어가 사전에서 몇 번째 단어인지 return 하도록 solution 함수를 완성해주세요.
제한사항
- word의 길이는 1 이상 5 이하입니다.
- word는 알파벳 대문자 'A', 'E', 'I', 'O', 'U'로만 이루어져 있습니다.
입출력 예
| word | result |
|---|---|
"AAAAE" | 6 |
"AAAE" | 10 |
"I" | 1563 |
"EIO" | 1189 |
입출력 예 설명
입출력 예 #1
사전에서 첫 번째 단어는 "A"이고, 그다음은 "AA", "AAA", "AAAA", "AAAAA", "AAAAE", ... 와 같습니다. "AAAAE"는 사전에서 6번째 단어입니다.
입출력 예 #2
"AAAE"는 "A", "AA", "AAA", "AAAA", "AAAAA", "AAAAE", "AAAAI", "AAAAO", "AAAAU"의 다음인 10번째 단어입니다.
입출력 예 #3
"I"는 1563번째 단어입니다.
입출력 예 #4
"EIO"는 1189번째 단어입니다.
풀이
alpha_list = ['A', 'E', 'I', 'O', 'U']
result = 1
print(word)
for i in range(len(word)):
word_index = alpha_list.index(word[i])
# print(5 - i)
left_len = len(alpha_list[0:word_index])
# print(left_len)
# print("+++++")
if left_len :
for k in range(5 - i):
result += left_len*5**k
result += 1
else :
result += 1
answer = result - 1처음에는 완전탐색으로 DFS를 쓰면 시간 초과가 날 거 같아서 경우의 수로 풀었다. 물론 두 가지 경우 모두 정답처리가 가능했지만 경우의 수 풀이쪽이 훨씬 빠르고 메모리도 적게 사용함을 확인 할 수 있었다.
간단하게 로직을 설명하자면 ,
단어가 EIO일 경우, A부터 E까지의 경우의 수 + E부터 EI까지의 경우의 수 + EI부터 EIO까지의 경우의 수를 모두 더해준다. 이때 남은 자리는 5가지의 경우가 올 수 있고 하나씩 남은 자리는 하나씩 공백으로 둘 수 있기 때문에 A부터 E까지의 경우의 수 는 15^4 + 1 5^3 + 1 5^2 + 1 5 + 1*5^0 + 1(자기 자신)이 된다.
def solution(word):
print(word)
alphabets = ['A', 'E', 'I', 'O', 'U']
global cnt
cnt = 0
global flag
flag = False
def dfs(result):
# print(result)
global cnt
cnt += 1
#찾았을떄 True를 반환
if result == word:
print("found!")
return True
# 못찾았을 경우
else :
if len(result) >= 5 :
return False
else :
for alphabet in alphabets:
if dfs(result + alphabet):
return True
for alphabet in alphabets:
if dfs(alphabet):
break
answer = cnt
return answer완전탐색 (DFS)를 이용한 로직이다. A부터 순차적으로 하나씩 더해서 word에 맞는지 확인하며 맞으면 True를, 만약 길이가 5를 넘어가는 순간 탐색을 멈춰야하기 때문에 Fasle를 return해준다. (그냥 return 해줘도 무방하다) 만약 해당 타켓 word와 맞으면 바로 break를 하고 cnt를 출력한다.
프렌즈4블록
블라인드 공채를 통과한 신입 사원 라이언은 신규 게임 개발 업무를 맡게 되었다. 이번에 출시할 게임 제목은 "프렌즈4블록".
같은 모양의 카카오프렌즈 블록이 2×2 형태로 4개가 붙어있을 경우 사라지면서 점수를 얻는 게임이다.

만약 판이 위와 같이 주어질 경우, 라이언이 2×2로 배치된 7개 블록과 콘이 2×2로 배치된 4개 블록이 지워진다. 같은 블록은 여러 2×2에 포함될 수 있으며, 지워지는 조건에 만족하는 2×2 모양이 여러 개 있다면 한꺼번에 지워진다.
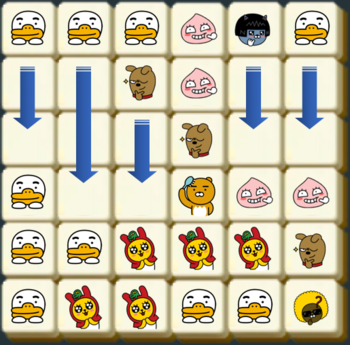
블록이 지워진 후에 위에 있는 블록이 아래로 떨어져 빈 공간을 채우게 된다.

만약 빈 공간을 채운 후에 다시 2×2 형태로 같은 모양의 블록이 모이면 다시 지워지고 떨어지고를 반복하게 된다.

위 초기 배치를 문자로 표시하면 아래와 같다.
TTTANT
RRFACC
RRRFCC
TRRRAA
TTMMMF
TMMTTJ각 문자는 라이언(R), 무지(M), 어피치(A), 프로도(F), 네오(N), 튜브(T), 제이지(J), 콘(C)을 의미한다
입력으로 블록의 첫 배치가 주어졌을 때, 지워지는 블록은 모두 몇 개인지 판단하는 프로그램을 제작하라.
입력 형식
- 입력으로 판의 높이
m, 폭n과 판의 배치 정보board가 들어온다. - 2 ≦
n,m≦ 30 board는 길이n인 문자열m개의 배열로 주어진다. 블록을 나타내는 문자는 대문자 A에서 Z가 사용된다.
출력 형식
입력으로 주어진 판 정보를 가지고 몇 개의 블록이 지워질지 출력하라.
입출력 예제
| m | n | board | answer |
|---|---|---|---|
| 4 | 5 | ["CCBDE", "AAADE", "AAABF", "CCBBF"] | 14 |
| 6 | 6 | ["TTTANT", "RRFACC", "RRRFCC", "TRRRAA", "TTMMMF", "TMMTTJ"] | 15 |
예제에 대한 설명
- 입출력 예제 1의 경우, 첫 번째에는 A 블록 6개가 지워지고, 두 번째에는 B 블록 4개와 C 블록 4개가 지워져, 모두 14개의 블록이 지워진다.
- 입출력 예제 2는 본문 설명에 있는 그림을 옮긴 것이다. 11개와 4개의 블록이 차례로 지워지며, 모두 15개의 블록이 지워진다.
# 우 우하 하
dx = [0, 1, 1]
dy = [1, 1, 0]
global cnt
cnt = 0
for i in range(m):
board[i] = list(board[i])
def bfs(now_board):
for i in range(int(m)):
for j in range(int(n)):
now_cnt = 1
tmp_list = []
now_letter = now_board[i][j]
tmp_list.append([i, j])
for k in range(3):
next_x = i + dx[k]
next_y = j + dy[k]
if 0 <= next_x < int(m) and 0 <= next_y < int(n):
if now_board[next_x][next_y] == now_letter and now_board[next_x][next_y] != 0:
now_cnt += 1
tmp_list.append([next_x, next_y])
if now_cnt == 4:
for coord in tmp_list:
now_board[coord[0]][coord[1]] = 0
# print(now_board)
break처음에 정사각형의 같은 블럭이 제거되거 중복되게 제거되지 않은 건 줄 알았다가 다시 지우고 처음부터 풀었다 ㅠㅠ
기본적으로 어차피 왼쪽부터 오른쪽으로 위쪽부터 아래쪽으로 순회하기 때문에 오른쪽, 오른쪽 아래 대각, 아래 이렇게 확인하면서 가면 정사각형의 같은 모양의 블록을 찾을 수 있다고 생각하였다.
import copy
def solution(m, n, board):
for i in range(m):
board[i] = list(board[i])
# m은 세로 n은 가로
# 우 우하 하
dx = [0, 1, 1]
dy = [1, 1, 0]
def deleteblock(now_board, cnt):
tmp_board = copy.deepcopy(now_board)
for i in range(m):
for j in range(n):
tmp_cnt = 1
tmp_list = [[i, j]]
now_letter = now_board[i][j]
# print(now_letter)
for k in range(3):
next_x = i + dx[k]
next_y = j + dy[k]
if 0 <= next_x < m and 0 <= next_y < n:
# print(now_board[next_x][next_y])
# print("+++")
if now_board[next_x][next_y] == now_letter :
tmp_cnt += 1
tmp_list.append([next_x, next_y])
# print("HI2")
if tmp_cnt == 4:
# print("HI")
for coord in tmp_list:
# print(coord)
if tmp_board[coord[0]][coord[1]]:
tmp_board[coord[0]][coord[1]] = 0
cnt += 1
return tmp_board, cnt
# 뒤집어서 삭제하고 다시 뒤집자
def clearboard(tmp_board):
changed_board = list(map(list, zip(*tmp_board)))
for i in range(n):
if 0 in changed_board[i]:
zero_cnt = changed_board[i].count(0)
for _ in range(zero_cnt):
changed_board[i].remove(0)
for _ in range(zero_cnt):
changed_board[i].insert(0, 0)
# print(changed_board[i])
result = list(map(list, zip(*changed_board)))
return result
test_board , cnt = deleteblock(board, 0)
# print(test_board)
# print(clearboard(test_board))
answer = 0
while True:
test_board, cnt = deleteblock(board, 0)
if cnt == 0:
break
answer += cnt
board = clearboard(test_board)
return answer배울점
문제를 풀면서 파이썬 몇 가지 코드들은 외워두면 상당히 유용할 듯 싶다. 메인 로직이 처음에 사각형인 점을 찾는데 이걸 바로 없어졌다고 표시하면 겹치는 블록일 경우, 다음 정사각형을 인식할 수 없게 된다. 따라서 copy라이브러리를 활용하여 깊은 복사(얉은 복사하면 에러가 생김 2차원 리스트이기 떄문이다) copy.deepcopy() . 이렇게 같은 블록이 정사각형으로 된 블록들을 복사된 보드에 표시하고 이를 정리하는 로직 또한 필요하다. 리스트로 풀어야 하지만 세로줄은 리스트식으로 풀 수 가 없어 list(map(list, zip(*li)))을 이용하여 풀었다.
list(map(list, zip(*board)))의 원리
zip()은 안에 있는 서로 다른 리스트가 있을 경우, 순차적으로 각 리스트에 있는 요소들을 하나씩 뽑아서 이를 하나의 튜플로 묶어준다.
예를 들어,
A = '1234'
B = '5678'
C = '4321'
D = '8765'
for node in zip(A, B, C, D):
print(node)출력
('1', '5', '4', '8')
('2', '6', '3', '7')
('3', '7', '2', '6')
('4', '8', '1', '5')이런식으로 된다.
따라서 *args를 사용하여 board안에 있는 리스트들을 뽑는다. 이를 zip을 이용하여 각 리스트 맨 앞 요소들을 하나의 튜플로 묶어 map(list,) 를 이용하여 튜플을 리스트로 변환해준다. 이를 다시 리스트로 묶어주어 행 열이 변환된 이중리스트가 된다.
copy.deepcopy() , list(map(list, zip(*li))), insert(0, 0)
기억하자
