자바의 대격변
자바의 시작
- 자바는 객체지향 프로그래밍이라는 소프트웨어 엔지니어링적인 이점을 가지고 있었고, jvm만 설치되어있다면, 어디서
나 실행시킬 수 있다는 장점 때문에 크게 사랑 받았다. - 초기 C언어의 이식성을 닮아서 자바 역시 jvm이 설치되어있는 환경이라면 프로그램을 실행 시킬 수 있었다.
자바가 직면한 요구사항
병렬 처리
- 빅데이터를 처리할 필요성이 늘어났고, 멀티코어 컴퓨터와 같은 병렬 프로세싱이 가능한 장비들
이 보급되면서 새로운 요구사항들이 생겨남. - 병렬처리 모델은 크게 2가지 모델로 구분 됨.
-- 여기서 이 2가지 모델이 무엇인지 궁금해져 한 번 알아보았다.
Data 병렬 처리 모델
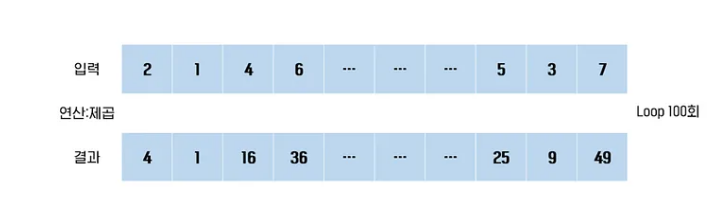
숫자 100개가 들어 있는 배열의 각 숫자의 제곱을 구하는 작업이 있다고 가정하자.
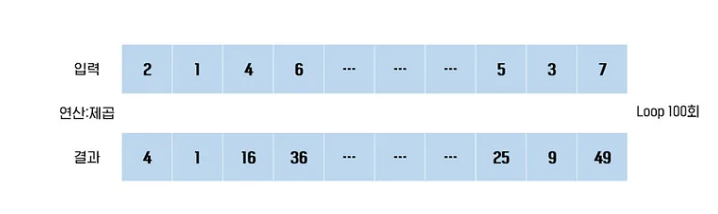
위 그림과 같이 100개의 데이터를 처리하는데 loop 100번을 돌아야 한다.
그럼, 1회당 4개의 데이터를 병렬 처리할 수 있다고 가정해보자.
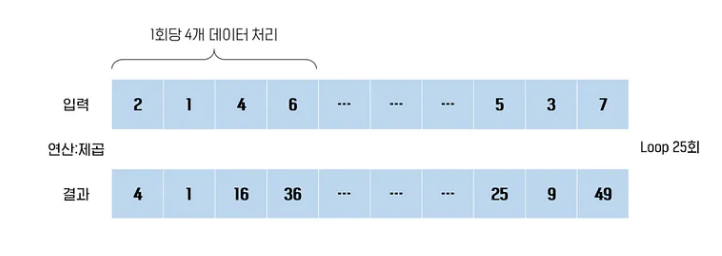
100개의 데이터를 처리하는데 loop 25번이면 처리할 수 있다. 이를 Data 병렬 처리 모델이라 한다.
위와 같은 처리 기술로는 대표적으로 다음과 같은 기술들이 있다.
▶ CPU SSE (Streaming SIMD Extensions)
-
SIMD (Single Instruction Multiple Data)라고도 함.
-
단일 명령어로 복수의 데이터를 처리.
-
xmm이라는 8개의 128 bit 레지스터(샌드브릿지 아키텍처부터는 256 bit 레지스터) 존재하여 해당 레지스터를 통해 복수 데이터를 처리하는 기술
▶ OpenMP (Open Multi-Processing)
-
공유 메모리 다중 처리 프로그래밍 API
-
특정 구간을 병렬화 시켜주는 기술
▶ Intel TBB (Threading Building Blocks)의 Generic Parallel Algorithms
- parallel_for, parallel_do, parallel_while, parallel_reduce, parallel_scan 등등
▶ CUDA
- NVIDIA 사 GPGPU의 매니코어 사용할 수 있는 라이브러리
▶ OpenCL (Open Computing Language)
- CUDA 보다 좀 더 확장된 개념으로 CPU, GPU, FPGA 등등의 멀티/매니코어 플랫폼을 이용하기 위한 표준 기술 등이 있다.
▶ SDAccel
- Xilinx 사의 FPGA 기반 프로그램을 보다 손쉽게 작성할 수 있도록 하는 개발 플렛폼으로 OpenCL, C, C++등의 언어로 작성할 수 있다.
Task 병렬 처리 모델 (Task : 작업 단위)
자동차를 만드는 공장이라고 가정해 보자. Task 병렬 처리 모델에서는 가중치가 필요한데, 예제에서는 가중치를 작업 시간으로 정했다.

해당 각각의 Task를 3개의 PE(Processing Element, 실행의 기본 단위가 되는 하드웨어 유닛)로 나누어보자. 어려우니 3 core로 나눈다고 가정한다.
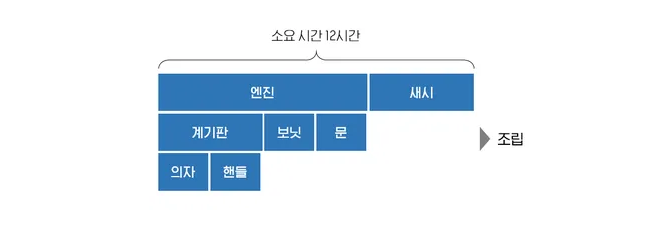
소요 시간이 24시간에서 12시간으로 줄었는데, 언뜻 보기에도 이상하다. 위의 예제는 Task를 잘못 분할한 예제다.
그럼, 각각의 Task의 작업 시간을 고려해서 바르게 분할해 보자.
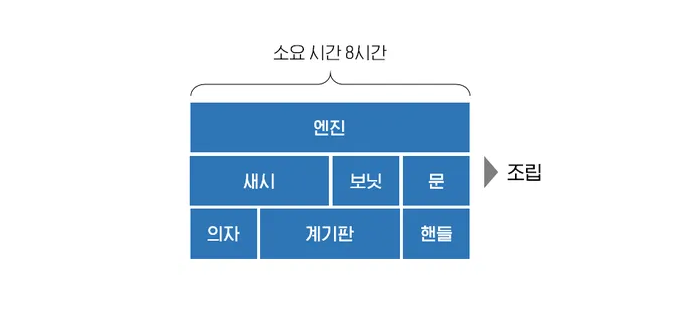
소요시간 12시간 작업이 8시간으로 줄면서, 보기 좋게 분할되었지요. 그러나, 현실 세계에서 위의 예제처럼 예쁘게 분할하기는 쉽지 않다. 많은 테스트를 통해 경험치를 쌓아야 한다. 이런 걸, Task 병렬 처리 모델이라고 한다.
실제 프로그램을 구현함에 있어서는 Data 병렬 처리 모델과 Task 병렬 처리 모델을 골고루 잘 활용하여 써야 한다.
또한, Task 병렬 처리 모델에서 제일 중요한 것은 서로 독립적인 Task(즉, 타 Task에 영향을 적게 주는)를 잘 분리해서 분할해야 한다는 것이다. 여러 개의 Task에서 하나의 데이터를 갱신하는 구조에 병렬 처리를 사용하려면 데이터 동기화부터 시작해서 매우 복잡해지기 때문이다.
위와 같은 처리 기술 종류에는 대표적으로 아래와 같은 기술들이 있다.
▶ Intel TBB (Threading Building Blocks)의 Flow Graph 와 Task Scheduler
▶ CUDA
: NVIDIA 사 GPGPU의 매니코어 사용할 수 있는 라이브러리
▶ OpenCL (Open Computing Language)
: CUDA 보다 좀 더 확장된 개념으로 CPU, GPU, FPGA 등등의 멀티/매니코어 플랫폼을 이용하기 위한 표준 기술
▶ SDAccel
: Xilinx 사의 FPGA 기반 프로그램을 보다 손쉽게 작성할 수 있도록 하는 개발 플랫폼. OpenCL, C, C++등의 언어로 작성할 수 있다.
지금까지 병렬 처리의 개념적인 2가지 모델에 대하여 살펴보았는데, 여기서 짚고 넘어가야 하는 중요한 법칙이 하나 있다.
바로 “암달의 법칙”이다.
암달의 법칙
진 암달이라는 연구자가 시스템의 어느 한 부분이 향상될 때 전체 시스템은 최대 얼마큼 향상될 수 있는지 예측하는 연구를 진행했다.
그의 주장은 이러하다.
- 시스템 전체를 2배 빠르게 수행하면, 실제 2배가 향상된다고 볼 수 있다.
그러나, 시스템의 절반만 2배 빠르게 수행하면, 시스템 전체는 1.33배가 향상된다"
아래 그림을 보자.

위와 같은 작업이 있다고 했을 때 어느 특정 구간을 병렬 처리를 진행합니다.
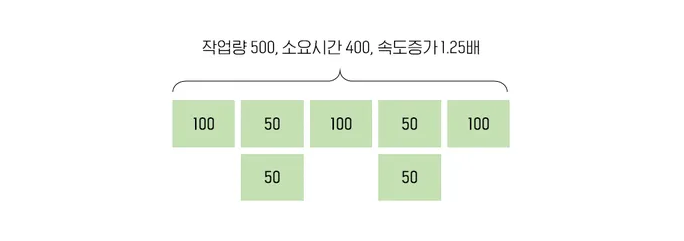
더 향상시켜
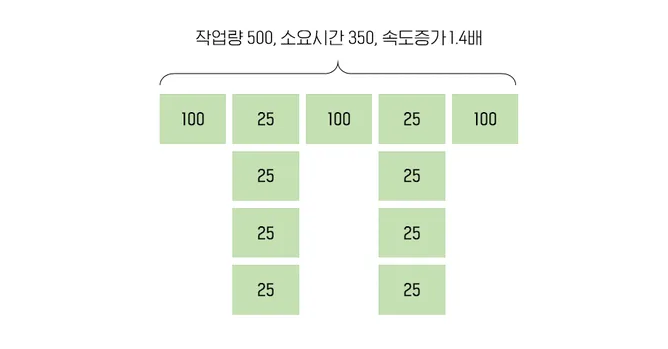
더 향상시켜
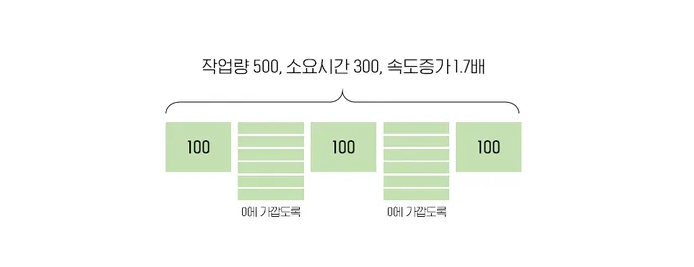
결국, 암달의 법칙이란 '아무리 많은 core를 가지고 특정 구간을 0에 가깝게 병렬화한다고 해도, 전체 수행 시간은 직렬화 구간의 실행 속도보다 더 빨라질 수는 없다'는 것.
마치, CUDA를 통해 병렬 프로그램을 할 때 GPU의 수많은 core를 활용하여 병렬 처리한다고 하더라도 cache memory에 있는 데이터를 GPU 메모리에 복사하고 GPU의 수행 결과를 cache memory에 복사하는 시간보다 빨라질 수는 없다는 얘기이다.
그 후 20년이 지난 요즘 암달의 법칙을 새롭게 해석한 연구자가 있다.
존 구스타프슨
기존에 암달의 법칙에 하드웨어 기술이 급속하게 향상된다는 것을 추가한 내용이다.

위의 그림에서 보는 것과 같이 하드웨어 기술의 발달로 동일 소요 시간당 작업량이 늘어날 수 있고 그로 인해 작업량을 기준으로 속도가 향상된다는 이야기이다.
-- 병렬처리에 관한 굉장히 흥미로운 고찰이다.
함수형 프로그래밍
-
함수형 프로그래밍은, 객체 지향 프로그래밍처럼 프로그래밍의 패러다임의 한 종류.
객체 지향 프로그래밍의 핵심 아이디어?
- 객체 지향 프로그래밍의 핵심 아이디어 자체는 간단하다.
a. '프로그램을 객체들의 협력과 상호작용으로 바라보고 구현한다' - 그 객체들을 정의하기 위해서 추상화와 같은 개념들을 사용하는 것.
- 핵심 개념을 통해서 달성하는 효용은 다음과 같다.
a. 코드의 재사용성이 높아진다.
b. 코드를 유지보수, 확장 하기 쉬워진다.
c. 코드를 신뢰성 있게 사용하기 쉬워진다.
- 객체 지향 프로그래밍의 핵심 아이디어 자체는 간단하다.
함수형 프로그래밍의 핵심 아이디어?
- 함수형 프로그래밍의 핵심 아이디어 역시 간단합니다.
a. “수학의 함수처럼, 특정한 데이터에 의존하지 않고, 관련없는 데이터를 변경하지도 않으며, 결과값이 오직 입력
값에만 영향을 받는 함수를 순수함수라고 합니다”
-
순수한 함수와 순수하지 못한 함수들
// 수학의 함수 f(x, y) = x + 2xy // 순수한 메서드 // input에 따라 output은 항상 일정! public int someMethod(int x, int y) { return x + 2y; } class notFunc { private int y = 0; private int result; // 순수 메서드가 아닌 메서드 // 메서드 안에서 제어할 수 없는 y라는 값에 의해 output이 바뀔 수 있다 public int anotherMethod(int x) { return x + this.y * 2; } // 순수 메서드가 아닌 메서드 2 // 메서드 내에서 this.result 값을 변경하고 반환하기 때문에 // 순수 메서드라고 보기는 어렵습니다! public int otherMethod(int x, int y) { int result = x + 2 * y; this.result = result; return result; } }b. '프로그램을 순수한 함수의 모음으로 바라보고 구현한다'.
- 핵심 개념을 통해서 달성하는 효용은 다음과 같다.
a. 검증이 쉽다 (검증이 필요한 부분만 검증 할 수 있음)
b. 성능 최적화가 쉽다 (특정 input에 대한 output을 재사용 할 수 있음 - 캐싱)
c. 동시성 문제를 해결하기 쉽다 (함수는 다른 값의 변경을 야기하지 않음)
결론 - 자바함수의 변화
자바 함수형 프로그래밍의 기능들을 추가하기로 결정!
-
함수형 프로그래밍 아이디어 1 : 함수를 일급 값으로
- 우리가 지금까지 배웠던 자바에서 “조작할 수 있는”값은 다음과 같다.
a. 기본값 (int, long, bollean, …)
b. 객체 - 1-a, 1-b 와 같은 값들은 다음과 같은 특징을 갖는다.
a. 함수에 인자로 넘길 수 있다.
b. 함수의 결과로 반환 할 수 있다.
c. 값을 수정할 수 있다
d. 값을 변수에 대입할 수 있다. - 사실상 프로그래밍에서 지원하는 모든 연산을 지원하고 있고, 이러한 연산을 모두 지원하는 “값”들을 일급 시민, 또
는 일급 객체라고 한다. - 그러나 메서드는 어떤가?
a. 메서드에 인자로 메서드를 넘길 수 있는가?
b. 메서드의 결과로 메서드를 반환 할 수 있는가?
c. 메서드를 변수에 대입 할 수 있는가? - 특정한 연산을 지원하지 않는 값이기 때문에 메서드는 이급 시민으로 볼 수 있다.
- 그렇지만 함수를 값으로 취급 할 수 있다면 매우 많은 것들을 할 수 있고, 함수형 프로그래밍에서는 이를 적극 이용
해 오고 있었다.
- 우리가 지금까지 배웠던 자바에서 “조작할 수 있는”값은 다음과 같다.
-
결론 : Java 8에 메서드 참조 기능이 도입!
