구조체 개념
Struct는 C의 유산이며 Class와 함께 사용자 지정 타입(User defined type)으로 쓰이는 자료 타입이다. 하지만 Class가 워낙 강력한 기능을 가지고 있기 때문에 struct는 보통 간단한 자료들을 모아 하나의 자료 구조를 만들때에나 많이 쓴다. Struct는 다음과 같이 선언하고 사용한다.
#include <iostream>
using namespace std;
struct Person {
int age;
string name;
char sex;
int siblings;
};
int main() {
Person person;
person = { 27, "Taeuk", 'm', 2 };
cout << "Your name is " << person.name << " and age is " << person.age << endl;
}
구조체 맴버 맞춤(Struct Member Alignment)
#include <iostream>
using namespace std;
struct MyData1 {
char a;
double b;
int c;
};
struct MyData2 {
char a;
int c;
double b;
};
int main() {
MyData1 s1;
MyData2 s2;
cout << sizeof(s1) << endl;
cout << sizeof(s2) << endl;
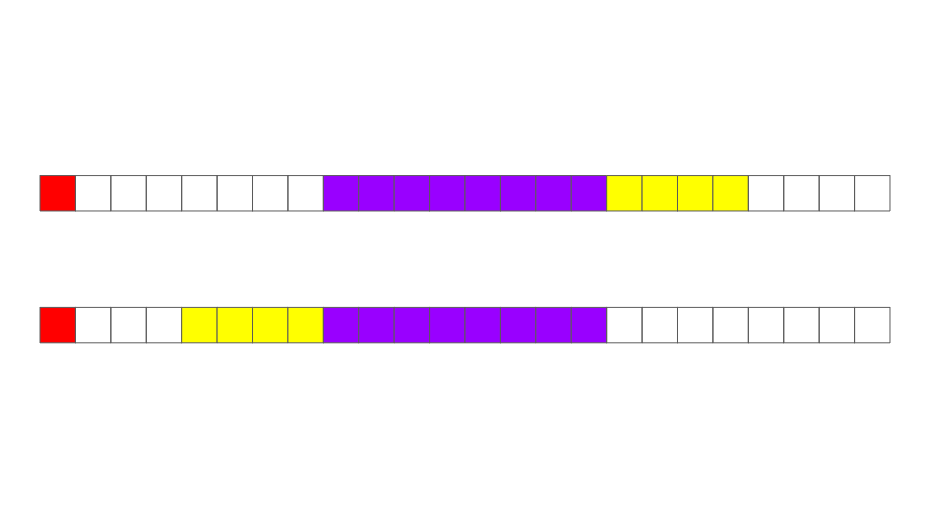
}신기하게도 struct에 맴버 변수를 어떤 순서로 배열하느냐에 따라 그 struct 변수를 선언했을때 잡히는 메모리의 크기가 다르게 된다. 위의 코드를 살펴보자. 두 개의 struct MyData1이랑 MyData2의 맴버 변수의 종류와 개수는 동일하다. 한 가지 차이점이 있다면 2개의 맴버 변수가 구조제 정의 부분에서 배열된 순서가 다르다는 점이다. main에서 이 둘의 크기(sizeof)를 비교해보면 s1과 s2는 각각 24byte와 16byte가 찍히는 것을 볼 수 있다. 이를 이해하여면 구조체 맴버 맞춤(Struct Member Alignment)이라는 개념을 이해하여야 한다.
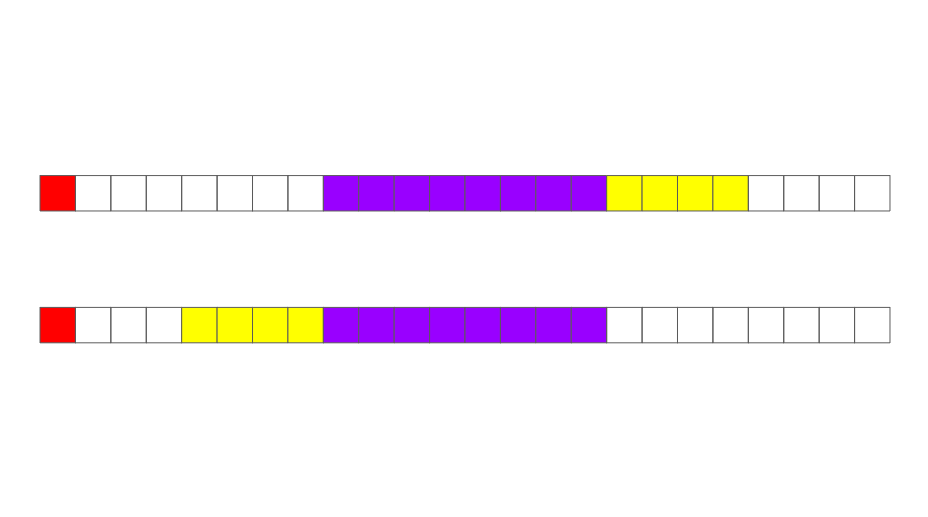
구조체 맴버 맞춤에서의 핵심은 구조체 안의 가장 큰 변수의 자료크기로 기본적인 chunk가 결정된다는 사실이다. 위의 예시에서는 double(8byte)이다. s1부터 살펴보면, 맨 처음에 8byte의 공간을 할당하고 거기에 char a를 넣는다. 그 다음에 double b를 넣어야 하는데 이미 a가 들어가 있기 때문에 다음 8byte 공간을 만들고 거기에 b를 저장한다. 마지막으로 int c를 위해 새로운 8byte를 또 만들고 c를 저장한다. 그래서 총 8+8+8 = 24byte의 공간이 할당되게 된다.
s2의 경우는 이와 다르다. a 저장을 위해 8byte을 할당하고 그 다음에 c를 저장하려고 봤더니 남은 공간 7(8byte - 1byte)byte의 공간이 남아있다.
우리는 지금까지 구조체 맴버 맞춤에서 가장 큰 맴버 변수의 자료 크기로 chunk가 결정된다는 사실을 알았다. 하지만, 이 chunk 안에서도 또 sub-chunk가 결정된다는 사실을 알아야 한다. 다음 예시를 보자.
#include <iostream>
using namespace std;
struct MyData1 {
char a;
char b;
char c;
char d;
int e;
double f;
};
struct MyData2 {
char a;
char b;
int e;
char c;
char d;
double f;
};
int main() {
MyData1 s1;
MyData2 s2;
cout << sizeof(s1) << endl;
cout << sizeof(s2) << endl;
system("pause");
}위 코드도 마찬가지로 맴버 변수의 순서만 다르지 맴버 변수의 개수, 종류는 같은 두 개의 struct인 MyData1과 MyData2를 준비해보았다. 결과를 찍어보면 MyData1은 16byte, MyData2는 24byte가 나오는 것을 알 수 있다. sub-chunk을 생각하지 않으면 둘 다 16byte의 결과가 나올 것이라고 예상했을 것이다.
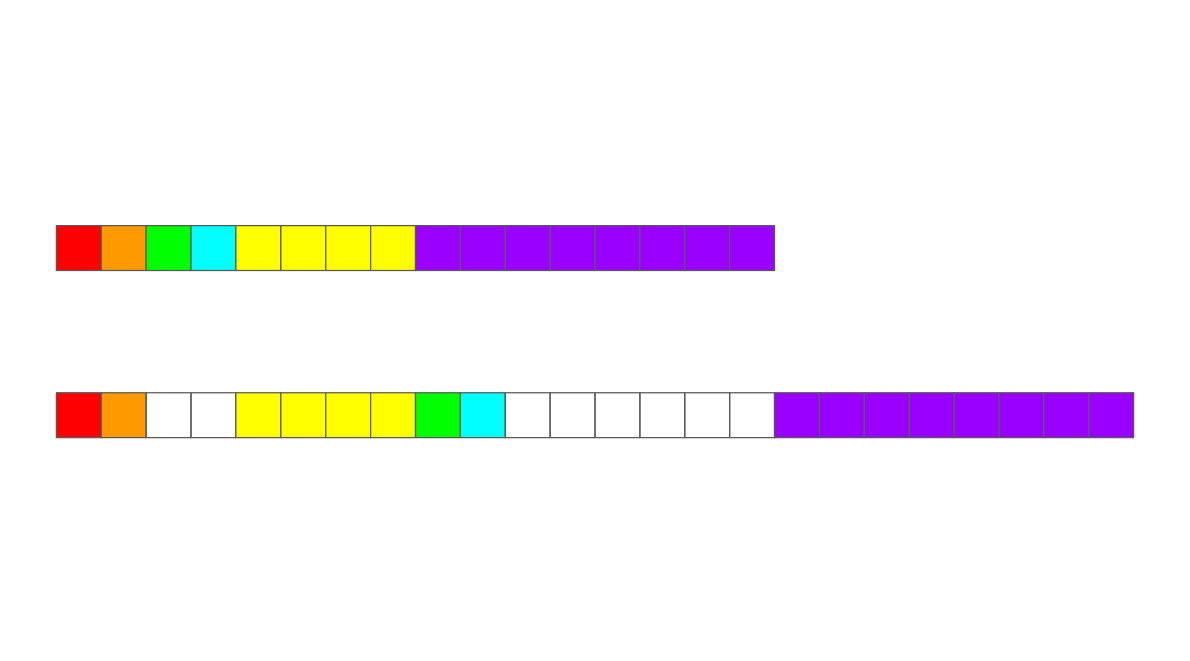
MyData1이 실제 메모리에 들어가는 것에 대한 예측은 잘 맞았을 것이다. 하지만 MyData2는 살짝 달랐을 것이다. 그 이유는 chunk 안에서 들어가는 자료 타입들 중 가장 큰 값을 기준으로 sub-chunk의 크기가 또 결정되기 때문이다. MyData2를 보면 char a, char b가 들어간 후 int e가 들어가려도 할때 chunk(8byte)를 다시 4 byte로 나누게 된다. 그러면 기존 앞 부분에는 4byte에 이미 2byte(1byte + 1byte)가 위치하고 있기 때문에 그 다음 sub-chunk에 int e가 위치하게 된다!!
구조체 패딩(Struct Padding)
위의 예시에서처럼(MyData2) 중간중간에 비는 비트를 구조체 패딩이라고 한다. 구조체 패딩을 하면 맴버 변수들이 메모리에 일정한 규칙으로 정렬되어 빠른 엑세스 타임을 가질 수 있지만 동시에 노는 패딩 비트로 인해 메모리를 많이 잡아먹게 된다.
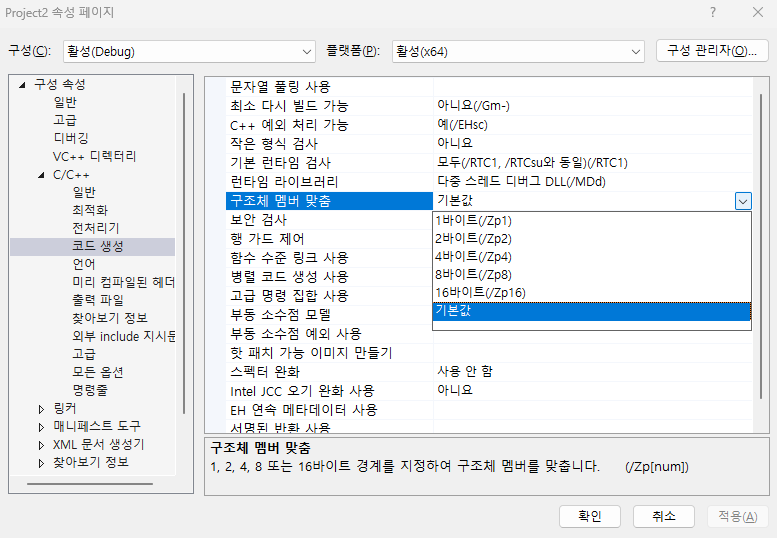
다음은 Visual Studio에서 구조체 맴버 맞춤을 바꿀 수 있는 설정 화면이다. 이 부분을 설정하면 chunk와 sub-chunk를 가장 큰 맴버 변수의 크기로 맞추는 것이 아닌 유동적으로 맞추게 된다. 하지만, 정말로 필요한 상황이 아니면 건드리지 않는 것이 좋아 보인다(사실 그럴 상황이 언제일지 감도 오지 않는다..)!
참고
