Redshift를 활용하여 Sql을 공부하기 위한 환경을 만들어 보겠습니다.
먼저 AWS Management Console을 이용하여 Redshift 대시보드를 만들어줍니다. (학습을 위한 무료 Serverless를 사용하였습니다.)
이제 대시보드에 데이터를 미리 저장해서 사용할 것인데 사용할 데이터베이스의 예제는 다음과 같습니다.
관계형 데이터베이스 예제
웹 서비스 사용자와 그에 맞는 세션 정보를 임의의 데이터를 저장하여 활용할 예정입니다.
사용자 ID
- 보통 웹서비스에서는 등록된 사용자마다 부여하는 유일한 ID
세션 ID
- 세션마다 부여되는 ID
여기서 세션이란?
사용자의 방문을 논리적인 단위로 나눈 것- 사용자가 외부 링크(보통 광고)를 타고 오거나 직접 방문해서 올 경우 세션을 생성
- 사용자가 방문 후 30분간 interaction이 없다가 뭔가를 하는 경우 새로 세션을 생성
- 즉 하나의 사용자는 여러 개의 세션을 가질 수 있음
- 보통 세션의 경우 세션을 만들어낸 접점(경유지)를 채널이란 이름으로 기록해둠
(마케팅 관련 기여도 분석을 위함) - 또한 세션이 생긴 시간도 기록
정보 활용
- 이러한 정보들을 기반으로 다양한 데이터 분석과 지표 설정이 가능
- 마케팅 관련, 사용자 트래픽 관련
- DAU, WAU, MAU등의 일주월별 Active User 차트
- Marketing Channel Attribution 분석
e.g. 어느 채널에 광고를 하는 것이 가장 효과적인가?
데이터베이스와 테이블(스키마)
큰 틀의 데이터베이스 구성을 이렇게 하고
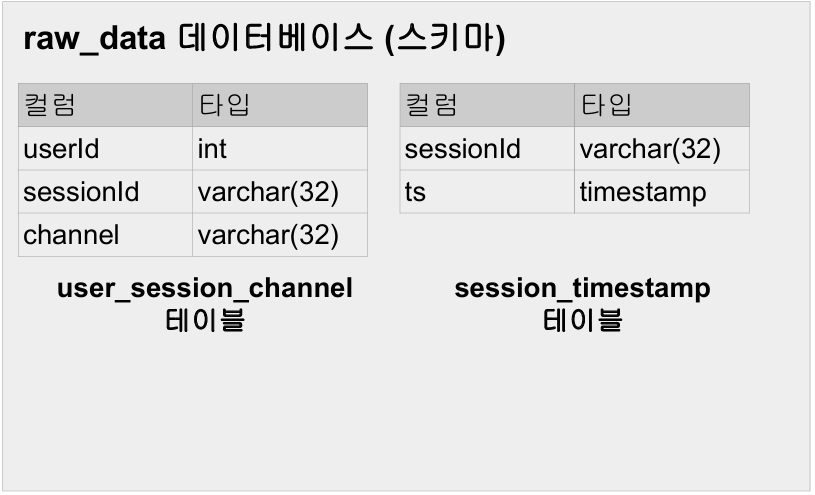
각각의 테이블들을 다음과 같이 저장해놓는다.
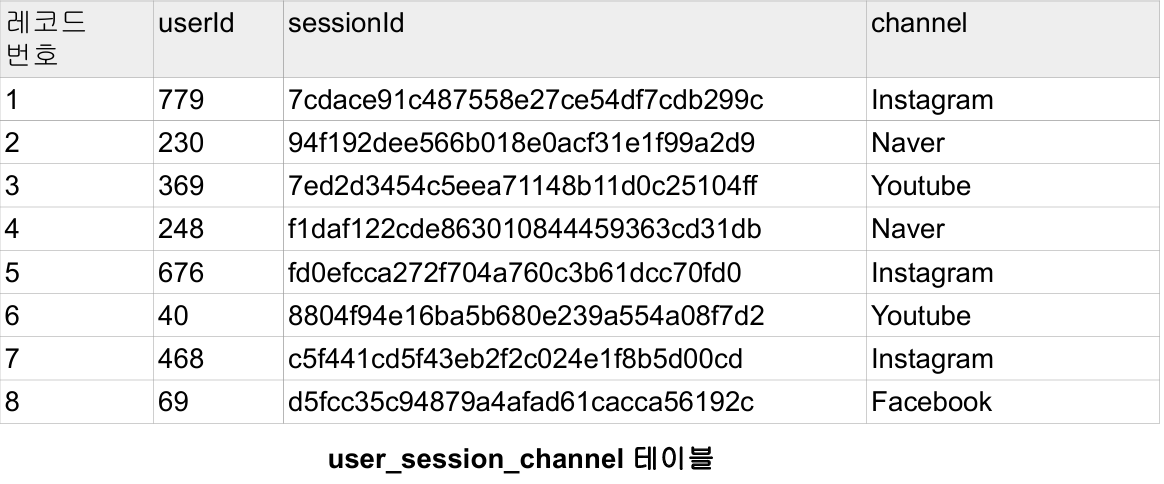 | 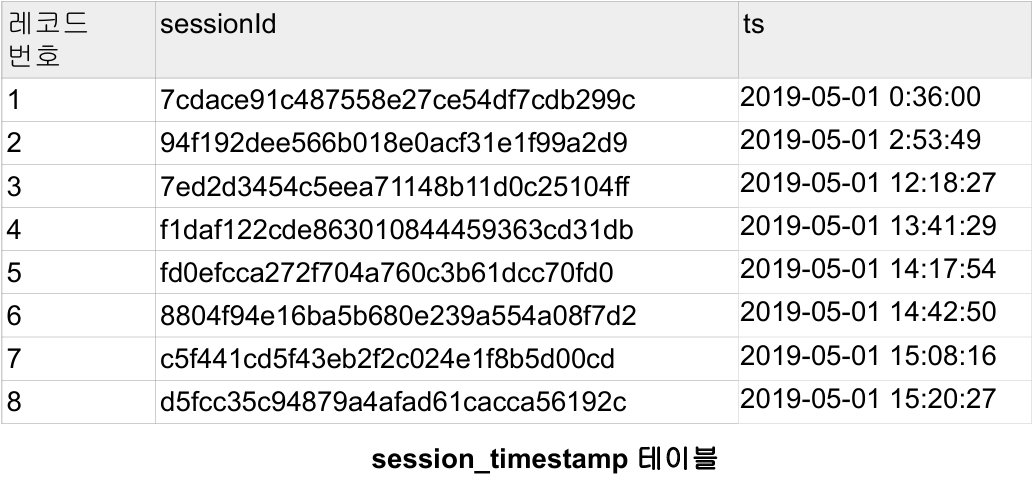 |
|---|---|
user_session_channel 테이블 | session_timestamp 테이블 |
SQL 소개
위에서 저장한 데이터들을 이용하여 Redshift 중심으로 DDL과 DML을 알아보겠습니다.
SQL 기본
- 먼저 다수의 SQL 문을 실행한다면 세미콜론으로 분리 필요
- SQL문1; SQL문2; SQL문3;
- SQL 주석
- -- : 인라인 한줄짜리 주석. 자바에서 //에 해당
- / -- /: 여러 줄에 걸쳐 사용 가능한 주석
- SQL 키워드는 대문자를 사용한다던지 하는 나름대로의 포맷팅이 필요
- 팀 프로젝트라면 팀에서 사용하는 공통 포맷이 필요
- 테이블/필드이름의 명명규칙을 정하는 것이 중요
- 단수형 vs. 복수형
- User vs. Users
- _ vs. CamelCasing
- user_session_channel vs. UserSessionChannel
SQL DDL (테이블 구조 정의 언어)
- CREATE TABLE
- Primary key 속성을 지정할 수 있으나 무시됨
- Primary key uniqueness
- Big Data 데이터웨어하우스에서는 지켜지지 않음 (Redshift, Snowflake, BigQuery)
- Primary key uniqueness
- CTAS: CREATE TABLE table_name AS SELECT
- vs. CREATE TABLE and then INSERT
e.g.
- vs. CREATE TABLE and then INSERT
CREATE TABLE raw_data.user_session_channel (
userid int,
sessionid varchar(32) primary key,
channel varchar(32)
);- DROP TABLE
DROP TABLE table_name;
/*없는 테이블을 지우려고 하는 경우 에러를 냄*/
DROP TABLE IF EXISTS table_name;
/*IF EXISTS를 이용하여 에러 방지*/
vs. DELETE FROM
/*DELETE FROM은 조건에 맞는 레코드들을 지움 (테이블 자체는 존재)*/3.ALTER TABLE
새로운 컬럼 추가:
- ALTER TABLE 테이블이름 ADD COLUMN 필드이름 필드타입;
기존 컬럼 이름 변경:
- ALTER TABLE 테이블이름 RENAME 현재필드이름 to 새필드이름
기존 컬럼 제거:
- ALTER TABLE 테이블이름 DROP COLUMN 필드이름;
테이블 이름 변경:
- ALTER TABLE 현재테이블이름 RENAME to 새테이블이름;SQL DML (테이블 데이터 조작 언어)
- 레코드 질의 언어: SELECT
- SELECT FROM: 테이블에서 레코드와 필드를 읽어오는데 사용
- WHERE를 사용해서 레코드 선택 조건을 지정
- GROUP BY를 통해 정보를 그룹 레벨에서 뽑는데 사용하기도 함
- DAU, WAU, MAU 계산은 GROUP BY를 필요로 함
- ORDER BY를 사용해서 레코드 순서를 결정하기도 함
- 보통 다수의 테이블의 조인해서 사용하기도 함
- 레코드 수정 언어:
- INSERT INTO: 테이블에 레코드를 추가하는데 사용
- UPDATE FROM: 테이블 레코드의 필드 값 수정
- DELETE FROM: 테이블에서 레코드를 삭제
- vs. TRUNCATE
레코드를 삭제하는것은 동일하나 다르게 처리함
- vs. TRUNCATE
구글 Colab
Redshift를 활용하여 Sql을 공부하기 위한 환경으로 Colab을 이용해 보겠습니다.
구글 colab에서는 Sql이 업데이트 되어서 다른 모듈과 충돌하여 다운그레이드를 이용해주어야 할 필요가있습니다.
!pip install ipython-sql==0.4.1
!pip install SQLAlchemy==1.4.49그후 sql을 이용하기 위해 아래의 코드를 실행해 주고
%load_ext sql아래와 같은 방식으로 이용하여 줍니다.
%%sql
SQL코드내용SELECT
SELECT를 이용하는데 추가적인 정보를 소개하겠습니다.
1. SELECT
- 테이블(들)에서 레코드들(혹은 레코드수)을 읽어오는데 사용
- WHERE를 사용해 조건을 만족하는 레코드
e.g.
SELECT의 기본적인 문법
SELECT 필드이름1, 필드이름2, …
FROM 테이블이름;
*을 통해 모든 필드를 불러오는 방법이 있습니다.
또는 테이블의 이름을 자신이 원하는 순서대로 불러올 수 있습니다.
SELECT *
FROM 테이블이름1, 테이블이름2, 테이블이름3;
유일한 필드 이름을 알고 싶은 경우
SELECT DISTINCT 필드이름
FROM 테이블이름;
필드의 모든 레코드 수 카운트. COUNT(*). 하나의 레코드
SELECT 필드이름, COUNT(1)
FROM 테이블이름;
추가로 WHERE을 이용해 세부이름의 레코드만 카운트도 가능합니다.
WHERE 필드 = '세부이름';
CASE WHEN
- 필드 값의 변환을 위해 사용 가능
CASE WHEN 조건 THEN 참일때 값 ELSE 거짓일때 값 END 필드이름
- 여러 조건을 사용하여 변환하는 것도 가능
CASE
WHEN 조건1 THEN 값1
WHEN 조건2 THEN 값2
ELSE 값3
END 필드이름
NULL이란?
- 값이 존재하지 않음을 나타내는 상수. 0 혹은 ""과는 다름
- 필드 지정시 값이 없는 경우 NULL로 지정 가능
테이블 정의시 디폴트 값으로도 지정 가능
- 어떤 필드의 값이 NULL인지 아닌지 비교는 특수한 문법을 필요로 함
field1 is NULL 혹은 field1 is not NULL
- NULL이 사칙연산에 사용되면 그 결과는?
SELECT 0 + NULL, 0 - NULL, 0 * NULL, 0/NULL
- 전부 NULL값이 나오게 됩니다!
IN
- WHERE channel in (‘Google’, ‘Youtube’)
WHERE channel = ‘Google’ OR channel = ‘Youtube’
- NOT IN
LIKE and ILIKE
- LIKE is 는 case sensitive string match. ILIKE is 는 case-insensitive string match
- WHERE 필드이름 LIKE ‘가%’ -> ‘가*’
- WHERE 필드이름 LIKE ‘%나%’ -> ‘*나*’
- NOT LIKE or NOT ILIKE
BETWEEN
- Used for date range matching
위의 오퍼레이터들은 CASE WHEN 사이에서도 사용가능
STRING Functions
- LEFT(str, N)
왼쪽부터 N개의 str만 가져옴
- REPLACE(str, exp1, exp2)
exp1의 값을 exp2의 값으로 교체해줌
- UPPER(str)
대문자로 변경
- LOWER(str)
소문자로 변경
- LEN(str)
- LPAD, RPAD
특정 str을 붙여준다 (L, R으로)
- SUBSTRING
LEFT와 비슷하지만 시작위치를 설정할 수 있다.
ORDER BY
- Default ordering is ascending
ORDER BY 1 ASC
- Descending requires “DESC”
ORDER BY 1 DESC
- Ordering by multiple columns:
ORDER BY 1 DESC, 2, 3
- NULL 값 순서는?
NULL 값들은 오름차순 일 경우 (ASC), 마지막에 위치함
NULL 값들은 내림차순 일 경우 (DESC) 처음에 위치함
이를 바꾸고 싶다면 NULLS FIRST 혹은 NULLS LAST를 사용
타입 변환
DATE Conversion:
- 타임존 관련 변환
CONVERT_TIMEZONE('America/Los_Angeles', ts)
select pg_timezone_names();
- DATE_TRUNCATE
시간, 일 또는 월 등 지정하는 날짜 부분을 기준으로 타임스탬프 표현식 또는 리터럴을 자릅니다.
- DATE_TRUNC
첫번째 인자가 어떤 값을 추출하는지 지정(week, month, day, …)
- EXTRACT or DATE_PART:
날짜시간에서 특정 부분의 값을 추출가능
- DATEDIFF
날짜의 차이점 반환
- DATEADD
날짜 더해주기
- GETDATE
현재날짜
- TO_CHAR, TO_TIMESTAMP
날짜를 char형으로 바꿔주거나 char를 날짜형식으로 바꿔줌
주
늘 새로운걸 도전하는 의지