
DB Lock
DB Lock은 트랜잭션 처리의 순차성을 보장하기 위한 기법
-공유락(LS) Read Lock라고도 하는 공유락은 트랜잭션이 읽기를 할 때 사용하는 락이며, 데이터를 읽기만하기 때문에 같은 공유락 끼리는 동시에 접근 가능
-배타락(LX)Write Lock라고도 하는 베타락은 데이터를 변경할 때 사용하는 락이며, 트랜잭션이 완료될 때까지 유지되며, 베타락이 끝나기 전까지 어떠한 접근도 허용x
Elastic Search
쉽게말해서 Elastic Search는 프로그램으로서의 검색엔진이다.(현재 가지고 있는 데이터 중에서 특정한 데이터를 검색할 수 있는 기능을 제공)
⭐ 검색엔진의 핵심 개념(Index,Inverted-Index)
- Index : 특정한 데이터가 어느 위치에 있는지 미리 저장해두어 검색 시에 빠른 속도로 찾을 수 있는것 (ex. 책의 목차)
- Inverted-Index : 키워드를 통해 문서를 찾아내는 방식. 검색성능이 매우 빠르다.

-
위 그림은 색인을 사용한 검색이다.
-
일반적으로 위의 테이블 데이터에서 한줄씩 like %fox 검색을 통해 데이터를 검색
-
하지만 이렇게 작은 데이터셋에서 검색을 할 때는 상관이 없지만 , 만일 매우 많은 데이터가 존재한다고 가정하면 검색을 위해서 우리의 검색엔진은 1번부터 순서대로 끝까지 검색해서 최악의 경우 엄청난 속도지연이 발생 --> 이러한 현상을 해결하기 위해 역색인(Inverted-Index)필요
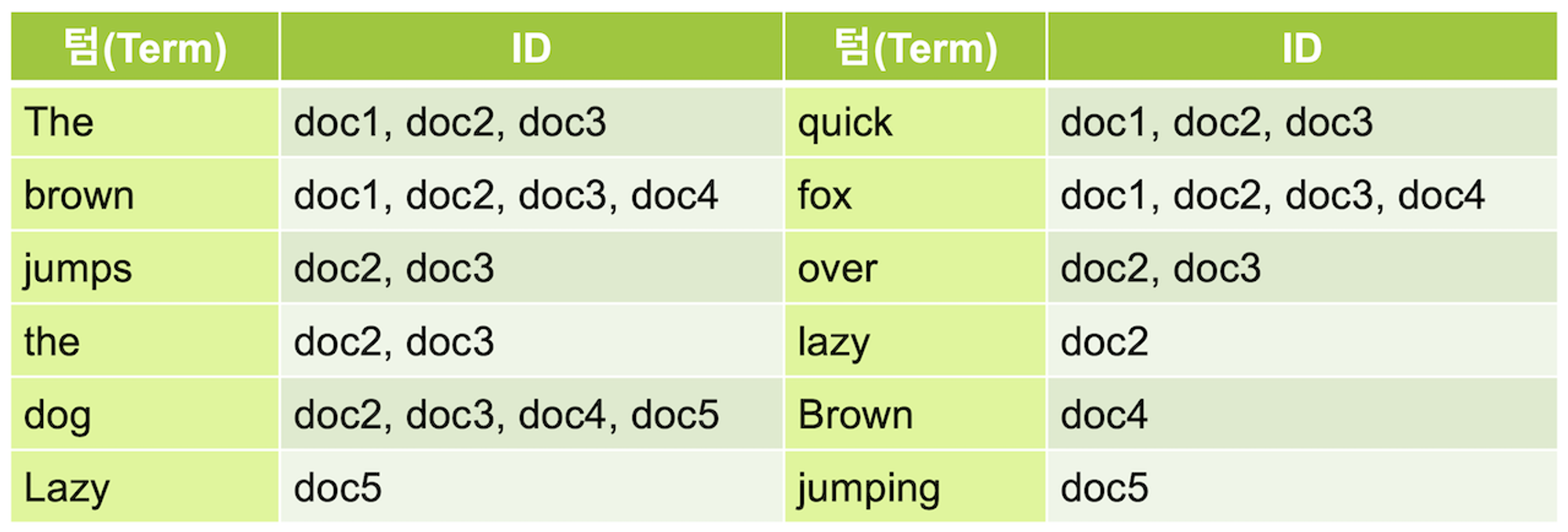
-
위 그림은 역색인을 사용한 검색이다.
-
역색인을 사용하는 검색 엔진에서는 추출된 각 키워드를 term이라고 한다.
-
이렇게 역색인이 있으면, fox를 포함하고 있는 문서의 id를 바로 얻어올 수 있다.
- 문서의 id는 PK, 물리적 주소등에 해당됨
-
역색인을 사용하면 데이터가 늘어나도 찾아가야 할 행이 늘어나는 것이 아니라 역색인이 가르키는 id의 배열 값이 추가되는 것이므로 큰 속도의 저하 없이 여전히 빠른 속도로 검색 가능
DB가 있는데 굳이 검색엔진?
-
관계형 데이터베이스는 단순 텍스트 매칭에 대한 검색만을 제공
- 요즘 최신 버전에서는 N-GRAM 기반의 FULL-TEXT 검색을 지원하지만, 한글 검색의 경우에 아직 많이 빈약함
-
텍스트를 여러 단어로 변형하거나 텍스트의 특질을 이용한 동의어나 유의어를 활용한 검색 가능
-
Elastic Search에서는 RDBMS에서 불가능한 비정형 데이터의 색인과 검색이 가능
-
역색인 지원으로 매우 빠른 검색이 가능
-
요즘은 Elastic Search가 제공하는 강력하는 기능을 활용하기 위해 DB에 저장된 데이터 중 검색 및 분석하고 싶은 DATA만 Elastic Search로 Indexing하고, Kibana를 활용해 분석 및 reporting을 시각화 하는것이 추세. 이를 위해 RDBMS에 저장된 DATA와 Elastic Search로 Indexing한 DATA의 동기화를 유지하는것이 검색기능을 활용하기 위한 필수 요건.
💡 요약
RDBMS와 Elastic Search는 사용하는 목적성이 다름
RDBMS는 어플리케이션에서 데이터 저장 용도 및 간단한 데이터 조회 용도로 사용
Elastic Search는 검색 시스템 트래픽이 늘어나고 요구사항이 늘어남에 따라 이는 RDBMS로 커버하기 힘들기에 커버하기 위한 검색에 특화된 해결 시스템
RDBMS로 쌓인 많은 데이터는 검색을 좀 더 효과적으로 하기 위한 데이터 구조로 변형하여 Elastic Search와 같은 검색 엔진에 저장. 이를 보통 데이터 파이프라인이라고 부름.
