2606-바이러스
문제
문제
신종 바이러스인 웜 바이러스는 네트워크를 통해 전파된다. 한 컴퓨터가 웜 바이러스에 걸리면 그 컴퓨터와 네트워크 상에서 연결되어 있는 모든 컴퓨터는 웜 바이러스에 걸리게 된다.
예를 들어 7대의 컴퓨터가 <그림 1>과 같이 네트워크 상에서 연결되어 있다고 하자. 1번 컴퓨터가 웜 바이러스에 걸리면 웜 바이러스는 2번과 5번 컴퓨터를 거쳐 3번과 6번 컴퓨터까지 전파되어 2, 3, 5, 6 네 대의 컴퓨터는 웜 바이러스에 걸리게 된다. 하지만 4번과 7번 컴퓨터는 1번 컴퓨터와 네트워크상에서 연결되어 있지 않기 때문에 영향을 받지 않는다.
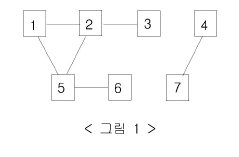
어느 날 1번 컴퓨터가 웜 바이러스에 걸렸다. 컴퓨터의 수와 네트워크 상에서 서로 연결되어 있는 정보가 주어질 때, 1번 컴퓨터를 통해 웜 바이러스에 걸리게 되는 컴퓨터의 수를 출력하는 프로그램을 작성하시오.
입력
첫째 줄에는 컴퓨터의 수가 주어진다. 컴퓨터의 수는 100 이하인 양의 정수이고 각 컴퓨터에는 1번 부터 차례대로 번호가 매겨진다. 둘째 줄에는 네트워크 상에서 직접 연결되어 있는 컴퓨터 쌍의 수가 주어진다. 이어서 그 수만큼 한 줄에 한 쌍씩 네트워크 상에서 직접 연결되어 있는 컴퓨터의 번호 쌍이 주어진다.
출력
1번 컴퓨터가 웜 바이러스에 걸렸을 때, 1번 컴퓨터를 통해 웜 바이러스에 걸리게 되는 컴퓨터의 수를 첫째 줄에 출력한다.
요구사항
네트워크 상에서 컴퓨터들이 연결되어 있다. 1번 컴퓨터가 웜 바이러스에 걸렸을 때, 연결된 모든 컴퓨터로 바이러스가 전파된다.
입력: 컴퓨터의 수(N), 연결된 쌍의 수(M), 그리고 연결된 번호 쌍들.
목표: 1번 컴퓨터를 통해 바이러스에 걸리게 되는 컴퓨터의 수를 출력하라. (1번 컴퓨터 자체는 카운트에서 제외)
접근 방식
이 문제는 전형적인 그래프 탐색(Graph Traversal) 문제다. '유기농 배추' 문제가 2차원 좌표 위에서 상하좌우로 움직이는 것이었다면, 이 문제는 노드(컴퓨터)와 간선(연결)을 따라 이동해야 한다.
1) 데이터 저장: 인접 리스트 (Adjacency List)
컴퓨터의 개수가 100개 이하로 적지만, 희소 그래프(Sparse Graph)일 경우를 대비해 메모리 효율이 좋은 ArrayList<ArrayList> 구조를 선택했다.
인덱스 1번부터 N번까지 각 컴퓨터마다 연결된 리스트를 갖는다.
2) 양방향 연결 (핵심!)
문제에서 "직접 연결되어 있다"고 했으므로, 네트워크는 방향성이 없는 그래프(Undirected Graph)다.
입력이 1 2로 주어지면, 1번에서도 2번을 갈 수 있고, 2번에서도 1번을 갈 수 있어야 한다.
따라서 graph.get(a).add(b) 뿐만 아니라 graph.get(b).add(a)도 반드시 해줘야 한다.
3) DFS 탐색과 카운팅
boolean[] visited 배열로 방문 여부를 체크하여 무한 루프를 방지한다.
1번 노드부터 DFS를 시작하고, 방문하지 않은 노드를 만날 때마다 answer를 1씩 증가시킨다. 이렇게 하면 나중에 1번을 뺄 필요 없이 정확히 '새로 감염된 컴퓨터 수'만 셀 수 있다.
코드
import java.io.BufferedReader;
import java.io.IOException;
import java.io.InputStreamReader;
import java.util.*;
public class Main {
static ArrayList<ArrayList<Integer>> graph;
static int answer = 0;
static boolean[] visited;
public static void main(String[] args) throws IOException {
BufferedReader br = new BufferedReader(new InputStreamReader(System.in));
StringTokenizer st;
graph = new ArrayList<>();
st = new StringTokenizer(br.readLine());
int n = Integer.parseInt(st.nextToken());
st = new StringTokenizer(br.readLine());
int k = Integer.parseInt(st.nextToken());
for(int i=0; i<=n; i++){
graph.add(new ArrayList<>());
}
visited = new boolean[n+1];
for(int i=0; i<k; i++) {
st = new StringTokenizer(br.readLine());
int a = Integer.parseInt(st.nextToken());
int b = Integer.parseInt(st.nextToken());
graph.get(a).add(b);
graph.get(b).add(a);
}
visited[1] = true;
dfs(1);
System.out.println(answer);
}
static void dfs(int idx) {
for(int x : graph.get(idx)) {
if(!visited[x]) {
visited[x] = true;
answer++;
dfs(x);
}
}
}
}느낀점
-
단방향 vs 양방향의 중요성 처음 구현할 때 습관적으로 graph.get(a).add(b)만 작성했다가 오답 처리를 받았다.
문제점: 입력 데이터가 항상 부모->자식 순서나 작은 수->큰 수 순서로 들어온다는 보장이 없다. 예를 들어 2 1 순서로 입력이 들어왔을 때 단방향으로만 저장하면, 우리는 1번부터 탐색을 시작하므로 2번으로 넘어갈 수가 없게 되어 끊긴다.
해결: 네트워크나 친구 관계 같은 문제는 무조건 양방향(Bidirectional) 매핑을 해줘야 함을 뼈저리게 느꼈다.
-
변수명과 코드 가독성 처음엔 ArrayList 변수명을 단순히 al로, 연결 개수를 k로 썼는데, 나중에 코드를 다시 볼 때 헷갈릴 수 있음을 느꼈다. graph, m(Edge) 등 의미가 명확한 변수명을 쓰는 습관을 들여야겠다.
-
DFS 3연타 성공 오늘 '유기농 배추(좌표)', '타겟 넘버(재귀)', '바이러스(그래프)'를 연달아 풀면서, "상태를 정의하고 연결된 곳으로 파고든다"는 DFS의 핵심 원리가 머릿속에 확실히 자리 잡았다.
