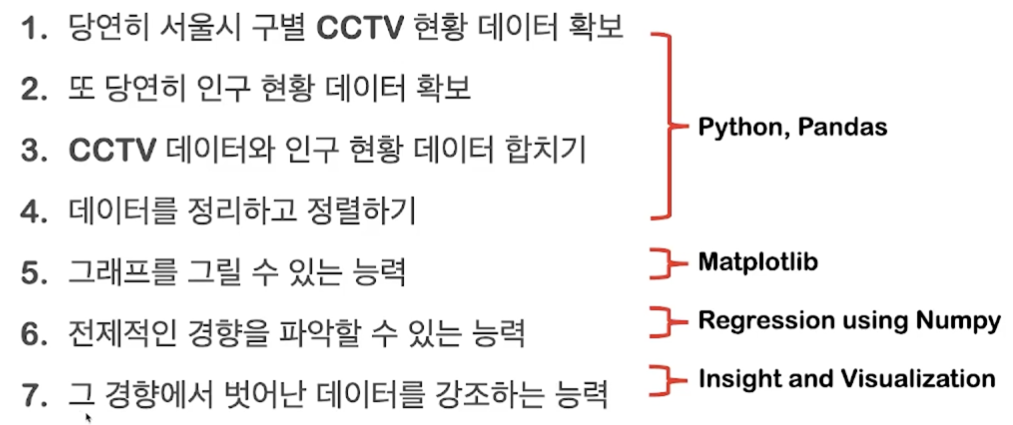
전체적인 흐름 및 목표
Pandas로 csv, 엑셀 파일 읽기
pandas란?
- R만큼의 강력한 데이터 핸들링 성능을 제공하는 모듈
- 표로 되어있는 숫자 데이터를 읽는 데 가장 많이 사용됨
csv 파일 읽기
import pandas as pdpd.read_csv(경로, 인코딩)- 다른 파일형식을 읽고 싶다면
read_파일형식을 지정하면 됨
pandas dataframe의 구조
- Column Name: 세로 방향의 데이터들의 이름
- Index: 가로방향의 데이터들의 이름
- Column
- Values
.columns: column의 이름을 조회할 수 있음
column명 변경하기
CCTV_Seoul.rename(columns={CCTV_Seoul.columns[0]: "구별"}, inplace=True)- 기존 CCTV_Seoul의 첫번째 컬럼명을 "구별"로 변경하는 코드.
inplace값을True로 주어야 함
- 기존 CCTV_Seoul의 첫번째 컬럼명을 "구별"로 변경하는 코드.
필요한 컬럼 지정하기
pd.read_excel(경로, header=2, usecols="B, D, G, J, N")header: 자료를 읽기 시작할 행usecols: 읽어올 엑셀의 컬럼
데이터 조회하기
.head()- 기본값은 5행이고 조회할 데이터 수를 조절하고 싶다면 인자로 조회할 데이터 수를 주면 됨. 기본값이 5
.tail()- 데이터의 끝에서부터 조회. 데이터의 총 수를 알기 좋음
pandas 기초
-
pandas의 데이터형을 구성하는 기본은
seriesa = pd.series([1, 2, 3])
-
날짜, 시간 이용
dates = pd.date_range("20130101", periods=6)- 2013년 1월 1일부터 6일간
-
pandas에서 가장 많이 사용되는 데이터형은
DataFrame이고 index와 columns를 지정df = pd.DataFrame(np.random.randn(6, 4), index=dates, columns=["A", "B", "C", "D"])
-
head()- 앞부분 5개
-
.index, .columns, .values -
.info()DataFrame의 기본정보 확인- 각 컬럼의 크기와 데이터 형태를 확인하는 경우가 많음
-
.describe()DataFrame의 통계적 기본정보 확인(평균, 표준편차 등등)
-
.sort_values(by=기준, ascending=True)- 정렬
-
df["A"]- "A" 컬럼만 읽기
slice로 지정 가능- 인덱스나 컬럼의 "이름"으로 slice하는 경우 리스트에서의
slice와 달리 끝을 포함함
- 인덱스나 컬럼의 "이름"으로 slice하는 경우 리스트에서의
-
df.loc[:, ["A", "B"]]- 행과 열을 지정
:는 모든 행 또는 열을 의미- 컬럼이나 인덱스의 "이름"으로 접근
-
df.iloc[3]- 번호로 접근
df.iloc[[1, 2, 4], [0, 2]]: 1, 2, 4번 행 + 0, 2번 열
-
df[조건]- 조건에 맞는 데이터를 조회
- 단 pandas의 버전에 따라 조금씩 허용되는 문법이 다르기 때문에 버전확인 필요
-
df[컬럼명]- 컬럼명이 기존에 존재하지 않을 때는
df[컬럼명] = 데이터와 같이 데이터를 추가할 수 있음
- 컬럼명이 기존에 존재하지 않을 때는
-
.isin(확인할 데이터)- 데이터가 있는지 확인
-
del df["E"]- 특정 컬럼 제거
-
.apply(함수)- 함수를 데이터들에 적용
