0. 개요
지난 수요일 15분 간 전체 서비스가 중단되는 장애가 발생했습니다. 원인은 몽고디비의 컬렉션에 인덱스를 추가하는 과정에서 primary 노드 컬렉션에 인덱스가 추가될 때 primary 노드에 대한 모든 요청에 대한 Write 작업이 중단되었고 서비스앱과 여러 서비스들이 몽고디비의 요청에 응답받지 못해 발생한 장애였습니다.(자세한 내용은 밑에 정리를 해두었습니다)
이번 계기를 통해 몽고디비에서의 인덱스와 foreground / background / hybrid 인덱스 빌드, 롤링 인덱스 빌드 등에 대한 개념을 정리해보려고 합니다.
1. MongoDB
몽고 DB는 관계형 데이터베이스(relational database)가 아닌 도큐먼트 지향 데이터베이스(document-oriented database) 입니다. 도큐먼트 지향 데이터베이스에서는 RDB의 행(row) 개념 대신 도큐먼트(document)를 사용하는데 이때 도큐먼트의 키와 값의 타입을 미리 정의하지 않습니다. 한마디로 고정된 스키마가 없고, 그렇기에 필요에 따라 쉽게 키를 추가하거나 제거할 수 있습니다.
몽고 DB의 장점은 도큐먼트 지향 데이터 모델을 통한 높은 확장성과 다양한 인덱스와 고성능, ReplicaSet을 통한 높은 가용성 등이 있습니다.
몽고 DB의 데이터베이스의 주요 개념 및 계층은 아래와 같습니다(RDB와 비교)
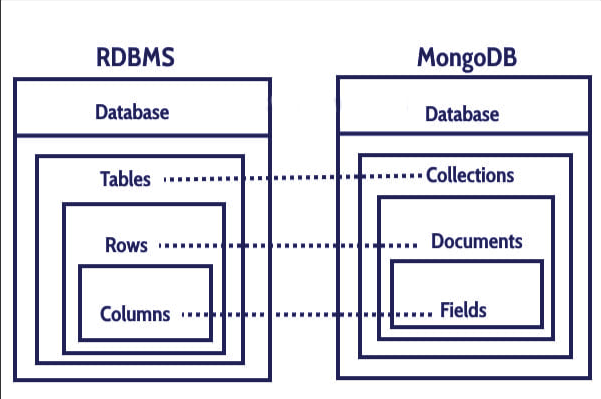
2. MongoDB Index와 성능
인덱스는 몽고 DB의 핵심 기능입니다. 고성능을 지향하는 몽고 DB에서 각 컬렉션에 적합한 인덱스를 선택하는 것은 그 목적을 달성하는데 큰 영향을 미치며 데이터가 많아질수록 그 진가가 크게 발휘됩니다. 기본적으로 모든 컬렉션은 생성될 때 기본적으로 _id 필드에 대한 인덱스가 부여됩니다(_id는 몽고 DB의 모든 도큐먼트가 생성될 때 부여되는 값으로 같은 _id를 가진 문서를 중복적으로 추가하는 것을 방지). 하나의 컬렉션에 최대 64개의 인덱스까지 생성가능합니다.
쿼리 성능적인 부분에서 인덱스는 중요한 개념이지만 인덱스를 사용하는데는 유지비용이 발생합니다. 데이터가 변경될 때마다 몽고 DB는 모든 인덱스를 갱신합니다. 따라서 쓰기 작업이 빈번한 컬렉션에서의 복잡한 인덱스 설계는 오히려 성능을 저하시킬 수도 있습니다. 또한 몽고디비의 인덱스는 메모리에 저장되어 있습니다. 하나의 인덱스는 16kb의 크기를 가지기 때문에 인덱스를 무수히 많이 생성한다면 쿼리 성능 저하를 유발할 수 있습니다.
따라서 데이터베이스와 실행할 쿼리 종류등을 고려하여 인덱스를 잘 설계해야합니다.
3. MongoDB Index 추가
몽고 DB에서 인덱스를 생성하는 방법은 아래와 같습니다. 인덱스 생성을 희망하는 데이터베이스.컬렉션에 원하는 도큐먼트 키값과 정렬 방향을 value값에 넣으면 컬렉션에 인덱스가 생성됩니다. 새로운 인덱스 구축은 많은 시간과 많은 리소스를 요구합니다. 그렇기에 몽고 DB 4.2 버전 이전에는 인덱스를 최대한 빨리 구축하기 위해 컬렉션의 모든 읽기와 쓰기작업을 중단(Exclusive)시켰습니다.
3.1 foreground index build
따라서 아래의 쿼리처럼 별도의 옵션을 주지 않은 채 인덱스를 생성한다면 진행 컬렉션에 대한 global lock이 잡히며 모든 요청이 중단될 것입니다.
<database>.<collection>.createIndex({"<indexKey>": 1})3.2 background index build
background 옵션을 추가해주며 global lock을 피할 수가 있습니다. background 옵션을 추가해준다면 작업 중인 collection으로 요청이 있다면 인덱스 생성 잠시 중단되었다가 요청 완료 후 다시 인덱스를 생성합니다.
<database>.<collection>.createIndex({"<indexKey>": 1}, {"background": true})따라서 동시 사용성이 증가하지만 foreground 방식에 비해 느리다는 단점이 있습니다. 무엇보다도 몽고 DB의 경우, 메모리 성능이 전체적인 퍼포먼스에 영향을 주게 되는데, 인덱스 생성 작업은 서버에 메모리를 추가적으로 사용하는 작업입니다. 따라서 background 옵션을 통해 인덱스 빌드를 진행할 때는 메모리 모니터링을 함께 진행하는 것이 안정성 측면에서 이점이 있습니다. 만약 인덱스를 추가하는 작업으로 인한 메모리 부족현상이 나타난다면 장시간 성능저하와 지연 현상이 장시간 발생할 수도 있습니다.
3.3 hybrid index build
몽고 DB의 createIndex 명령어는 4.2 버전과 4.4 버전에서 많은 부분 변화했는데, 4.2 버전에서는 인덱스 추가 프로세스 과정에서 시작과 끝에서만 컬렉션에 대한 Exclusive(W) 잠금을 유지하는 최적화 된 빌드 프로세스를 채택했습니다. 이러한 hybrid 인덱스 생성 방식은 이전의 background 인덱스 생성의 성능을 보장하면서 lockless합니다. 4.4 버전에서는 모든 ReplicaSet에서 인덱스가 동시에 빌드됩니다.
4. Rolling index build
이번 인덱스 추가 작업은 CLI 명령어가 아닌, mongoDB atlas 웹 상에서 제공하는 인덱스 추가 기능을 사용했습니다. 현재 mongoDB atlas cloud 상에서 4.2.xx 버전를 사용하고 있는데, 인덱스 추가 작업 진행 시 rolling index build 옵션이 있어 선택을 한 후 진행을 했습니다. 현재 저희의 mongo cluster는 P-S-S로 구성되어 있고, 클러스터에 인덱스를 추가할 때는 rolling index build를 추천한다고 하여 진행을 하게 되었습니다.
롤링 인덱스 빌드는 replica node(secondary) 부터 시작하여 각 노드별로 인덱스 빌드를 독립적으로 실행합니다. 각 노드별로 인덱스를 빌드할 때는 해당 컬렉션에 대한 모든 쓰기를 중지됩니다. 아마 이번 장애가 primary node 인덱스 빌드 진행될 때 전체의 쓰기 작업이 중지 되면서 장애가 발생했을거라는 추측을 하게되었습니다.
롤링 인덱스 빌드 과정은 아래와 같습니다.
1. replica node(secondary) 중 하나를 중단하고 stand-alone으로 독립 실행하여 재 실행
2. 새로운 인덱스 추가
3. replica set에 stand-alone node를 새로운 구성원으로 추가하고 다시 시작
4. 남은 replica node 에 대한 1~3번 과정 반복
5. primary node 인덱스 빌드
5. MongoDB Index 삭제
<database>.<collection>.dropIndex({"<indexKey>": 1})
<database>.<collection>.dropIndexes()dropIndex()를 통해 인덱스 명을 지정하여 해당 인덱스를 삭제할 수 있습니다. dropIndexes()는 모든 인덱스를 삭제 할 수 있습니다. 단, _id 인덱스는 삭제 되지 않습니다. 4.4 버전 부터는 dropIndexes() 에서는 생성중인 인덱스도 중지 시킬 수 있습니다.
이전 버전에서는 database.currentOp() 를 통해 현재 실행되고 있는 리스트를 출력한다음, 종료하고자하는 op의 id값을 가져와서 database.killOp(op_id)를 진행하면 됩니다.
6. 마무리
정말 길었던 15분이었습니다. 다행히 빠르게(?) 복구되어 더 큰 문제는 없었지만 인덱스를 생성할 때 좀 더 신중하게 결정해야겠다는 큰 배움이 있었습니다.
