개요
간단하게 저의 환경을 소개드리면,
- 현재 회사에서 AWS EC2 + ECS 환경에서 Airflow를 운영하고 있습니다
- 데이터 웨어하우스로 구글 빅쿼리를 사용 중이며, airflow를 통해 메인 데이터베이스에서 데이터를 빅쿼리로 옮기는 ETL Load 작업을 진행하고 있습니다
간단 개념 ! ETL과 Airflow
💡 ETL은 추출(Extract), 변환(Transform), 로드(Load)를 나타내며 조직에서 여러 시스템의 데이터를 단일 데이터베이스, 데이터 저장소, 데이터 웨어하우스 또는 데이터 레이크에 결합하는 방법입니다 출처
💡 Airflow는 Python 기반의 프레임워크로, 워크플로우(workflow)를 작성하고 작업의 스케쥴링, 모니터링을 할 수 있습니다. 많은 기업에서 Airflow를 통해 ETL 자동화를 하고 있습니다.
멱등성
💡 멱등성은 연산을 여러 번 적용하더라도 결과가 달라지지 않는 성질
즉, 다른 날짜/시간/조건에서 동일한 매개변수로 실행되는 경우, 그 결과가 동일하게 유지되어야 한다는 것입니다. 멱등성은 ETL을 구성할 때 중요한 고민 포인트 중 하나입니다. 반복적이고 지속적으로 진행되는 ETL 작업에서 만족스러운 데이터 퀄리티 유지하기 위해서는 작업 누락, 원본 데이터와의 정합성도 중요하지만 결국 작업에 대한 멱등성이 보장되어야 데이터 중복과 같은 이슈에서 안전 할 수 있습니다.
물론 이전에도 멱등성을 고민하지 않은 것은 아닙니다. 이전에는 일부 테이블에 대해서 빅쿼리 WRITE_TRUNCATE 옵션을 통해 데이터의 멱등성을 보장했습니다.
(참고) 빅쿼리 데이터 쓰기 작업에는 두 가지의 옵션을 줄 수 있습니다. [출처]
- WRITE_TRUNCATE: 테이블이 존재하면 BigQuery가 테이블 데이터를 덮어씁니다
- WRITE_APPEND: 테이블이 존재하면 BigQuery가 데이터를 테이블에 추가합니다
방법은 간단합니다. 원본 테이블 전체를 dump 하여 빅쿼리에 적재하면 됩니다. 이 경우, 기존 빅쿼리 테이블을 덮어써버리기 때문에 원본 데이터 베이스의 변경 사항이 빅쿼리에도 즉각 반영이 되고, 몇 번을 반복하더라도 동일한 결과가 유지 됩니다.
하지만 이 경우는 테이블 크기가 작은 테이블에만 적용 할 수 있습니다. 테이블 크기가 일정 수준을 넘어가 버린다면, dump query 자체가 시스템 리소스의 큰 부하를 주게되어, 다른 작업에 영향이 갈 수도 있습니다. 그래서 이런 경우에는 어쩔 수 없이 WRITE_APPEND 옵션을 주고 airflow가 예상대로만 동작하기만을 기대할 수 밖에 없었습니다.
고민
airflow는 자체 DB를 통해 작업 스케쥴링을 관리합니다. airflow는 meta db에 저장된 작업의 최종 상태에 따라 작업을 종료할 수도, 다시 수행할 수도 있습니다.
여기서 문제가 발생합니다. 평시에는 문제가 없지만 종종 airflow가 내려갔다가 올라가는 경우 이전에 누락된 작업들이 다시 한 번에 동작을 하게 되는데, 이 때 멱등성이 보장되지 않은 상태에서 작업이 완료되다보니 일부 데이터들에 대한 중복이 발생하는 것이었습니다.
그럴 때 마다 다시 빅쿼리에서 데이터를 제거하고, 다시 Airflow를 통해 데이터를 보정하곤 했습니다. 물론이 작업에 포함되는 주요 로직이 시간 기반 쿼리이다보니 발생한 문제이기도 하지만, 이것을 해결 한다고 하더라도 근본적으로 중복이 발생할 수도 있는 상황이었습니다.
멱등성이 보장되는 Airflow 로직 만들기 !
위의 고민을 하다가 빅쿼리 MERGE를 사용하여 멱등성을 보장하는 Airflow 로직을 개발하기로 했습니다. 이를 한 장으로 정리하면 아래와 같습니다.
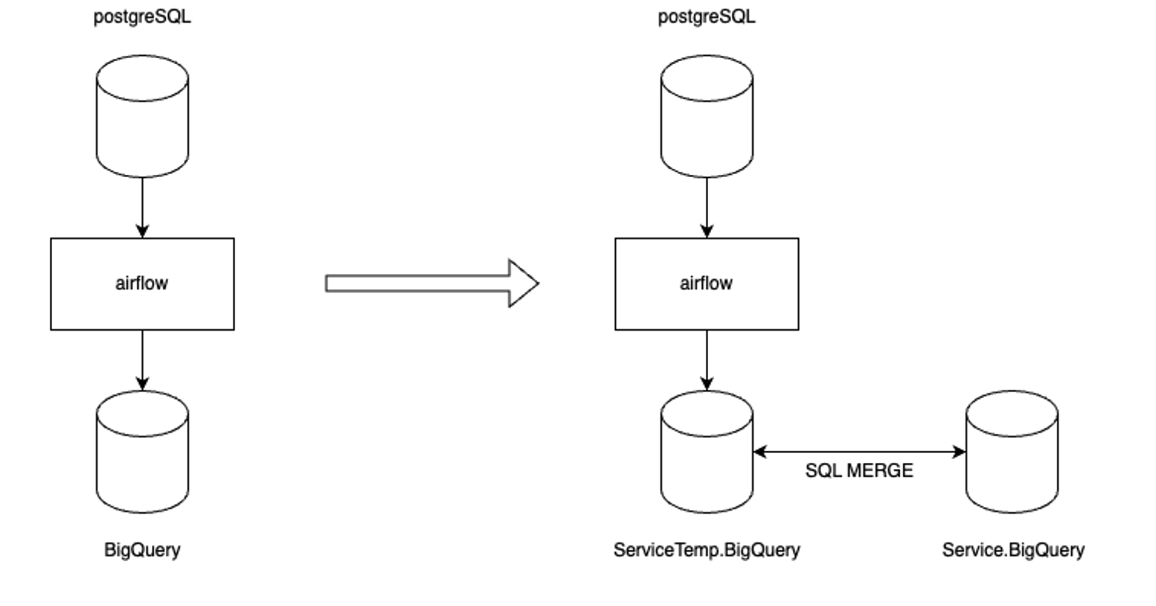
왼쪽이 기존 로직, 오른쪽이 새롭게 도입한 로직입니다.
왼쪽은 간단합니다. 메인 데이터베이스의 데이터를 airflow를 통해 빅쿼리 서비스용 DB로 옮기는 작업입니다. 반면 오른쪽은 메인 데이터베이스의 데이터를 빅쿼리 비지니스 및 분석용 DB 바로 옮기는 것이 아닌 임시 DB에 옮겨 놓은 후 임시 DB 테이블과 서비스 DB 테이블 사이의 MERGE를 통해 최종적으로 데이터를 Load하는 방식입니다.
BigQuery MERGE
빅쿼리 MERGE는 간단합니다. 여러 테이블의 데이터를 합치는 방식으로 병합 조건에 따라, 병합 조건에 만족하면 UPDATE or DELETE를 실행하고 조건에 만족하지 않는다면 INSERT 합니다. 한마디로 있으면 업데이트, 없으면 추가하는 쿼리문 입니다.
MERGE INTO `target_table` USING `source_table`
ON `merge_condition`
WHEN MATCHED THEN
UPDATE SET `column1` = `value1`, `column2` = `value2`, ...
WHEN NOT MATCHED THEN
INSERT (`column1`, `column2`, ...) VALUES (`value1`, `value2`, ...)BigQueryMergeOperator
Airflow에 BigQueryMerge만을 담당하는 Operator는 없습니다. 그래서 기존 BigQueryInsertJobOperator를 상속 받은 BigQueryMergeOperator를 커스텀 했습니다.
먼저 BigQueryInsertJobOperator 의 동작원리는 간단합니다. configuration, 쿼리를 포함한 동작 요청을 정의하면 execute 단계에서 빅쿼리에 해당 작업이 수행됩니다. 따라서 이 BigQueryInsertJobOperator configration을 잘 정의하면 CustomMergeOperator를 만들 수 있습니다.
우선 특정 작업에서만 사용할 것이 아닌 전반적인 로직에서 사용할 것이기에, 하드코딩이 아닌 동적으로 값이 변화해야합니다. configration을 구성하는 작업은 크게 두 단계로 나눴습니다.
- target 빅쿼리 테이블 컬럼 조회
def fields(self):
"""빅쿼리 테이블의 필드 정보"
hook = BigQueryHook(location='asia-northeast3')
try:
schemas = hook.get_schema(
dataset_id=self.target_dataset,
table_id=self.table,
)
return [field['name'] for field in schemas['fields']]
except Exception:
return []- 동적으로 merge query 생성
def merge_query(self):
"""merge query 생성"""
_fields = self.fields
update = ', '.join([f"{field}=source.{field}" for field in _fields])
insert_fields = ', '.join([f"{field}" for field in _fields])
target_source_condition = f"MERGE {self.target_dataset}.{self.table} target USING {self.source_dataset}.{self.table} source"
on_pk_condition = "target.id = source.id"
update_condition = f" WHEN MATCHED THEN UPDATE SET {update}"
insert_condition = f" WHEN NOT MATCHED THEN INSERT ({insert_fields}) VALUES ({insert_fields})"
return target_source_condition + " ON " + on_pk_condition + update_condition + insert_condition마무리
데이터 퀄리티를 높이기 위해서는 단순 멱등성 뿐만 아니라 제 시간에 데이터가 업데이트 되었는지, 원본 데이터 베이스와의 정합성이 보장되는지, 누락된 데이터가 있는지 등 여러가지 요소를 모두 고려해야합니다. 그래도 이번 기회를 통해 적어도 멱등성 관련한 영역에서의 데이터 퀄리티를 높일 수 있어 되어 뿌듯하네요 🚀
