참고링크
- https://velog.io/@seungyeon/카프카-무엇이고-왜-필요할까
- https://ellune.tistory.com/22?category=769027
- https://jessyt.tistory.com/131
- https://webfirewood.tistory.com/128
링크드 인이 카프카를 만든 이유
- end-to-end 연결 방식 아키텍쳐의 많은 문제점 해결을 위해서
- 통합 / 중앙화 된 전송 영역이 없음. end-to-end 연결이 복잡해짐
- 문제 해결 발생 시 여러 시스템을 확인해야함. 문제 해결이 어려워짐
- 데이터 파이프 라인 관리의 어려움
- 연결된 시스템 마다 각기 다른 방식으로 구현될 수 있음 → 파이프 라인의 통합과 확장이 어려움
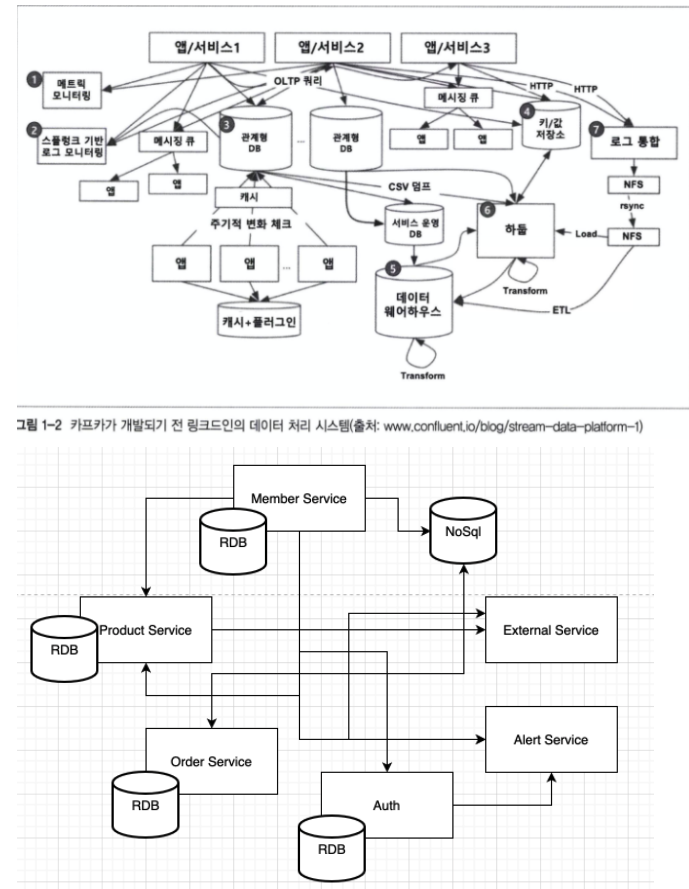
메시징 시스템이 없이 직접 연결하여 서비스가 진행된다면
- 메시징 시스템 서버를 거치지 않기 때문에 속도 면에서는 상대적으로 빠를 수 있음
- 하지만 송 / 수신자의 상태에 따라 각각 장애 처리를 해야하며, 참여하는 송 / 수신자가 많아질 수록 이 난이도는 올라가며 각 개체를 연결하는데에도 많은 어려움이 있음 → 확장성의 문제
링크든 인의 해결책
- 모든 시스템을 데이터로 전송할 수 있고
- 실시간 처리가 가능하며
- 급속도로 성장하는 서비스를 위해 확장이 용이한 시스템(카프카)을 만들자 !
카프카 개발팀의 목표
- 프로듀서와 컨슈머의 분리
- 높은 처리량으로 실시간 처리
- 메시징 시스템과 같이 영구 메시지를 여러 컨슈머에게 제공
- 메시지 최적화
- 다양한 제품과 시스템에 쉽게 연동
- 데이터 증가에 따른 무중단 scale-out이 가능한 시스템
- 이벤트 / 데이터의 흐름을 중앙에서 관리
- end-to-end 방식
- 메시지를 잃지 않음
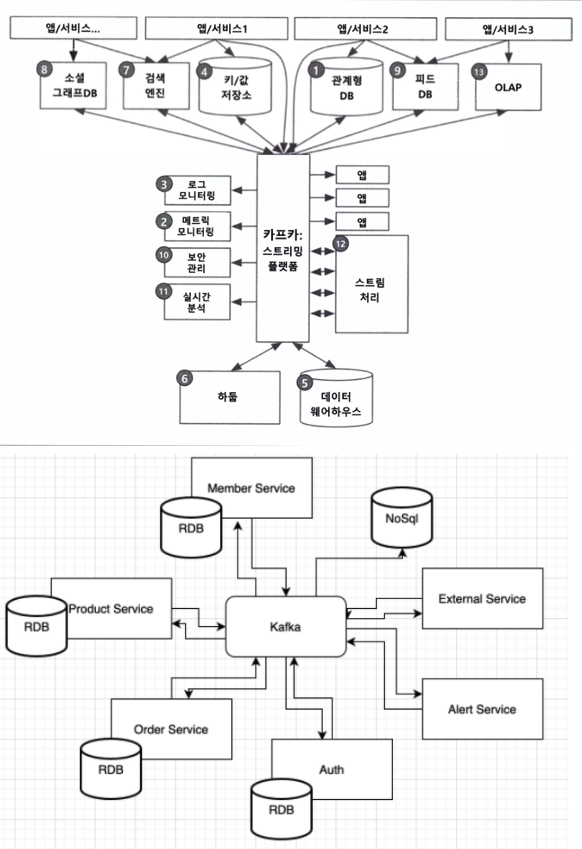
펍(Pub) / 섭(Sub) 모델의 특징
- 프로듀서가 메시지를 직접 전달하지 않고 중간의 메시징 시스템에 전달
- 컨슈머가 불능 상태라도 프로듀서는 메시징 시스템에 전달 할 수 있으며 메시지는 유실되지 않음. 이후 컨슈머가 정상적으로 돌아온다면 메시지를 가져옴
- 각각 개체가 N:N 통신을 하는 것이 아니기에 확장이 용이
- 메시지가 정확하게 전달되었는지 확인이 어렵다
- 중간에 메시징 시스템이 있기 때문에 메시지 전달 속도가 상대적으로 느리다
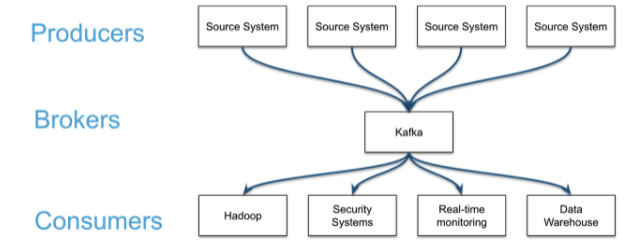
카프카 활용 사례
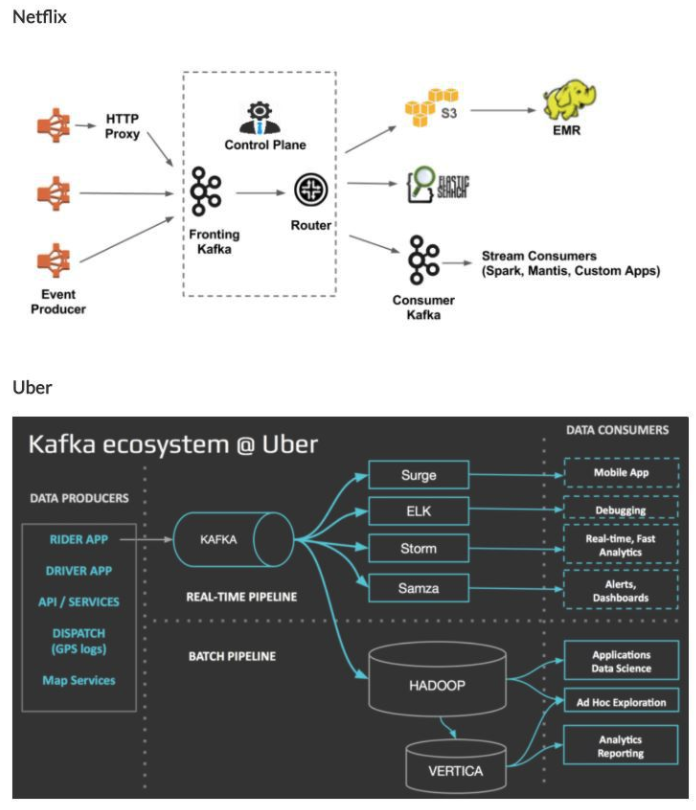
하나의 클러스터에 데이터를 집중시키는 이유 ? (== 카프카를 사용하는 이유)
데이터 허브의 역할
1. 일부러 많은 데이터를 하나의 클러스터에 집중시키고 있음
2. 데이터를 사용하는 서비스가 해당 데이터를 쉽게 찾을 수 있을 뿐 아니라 서비스에서 데이터에 접근하는 수단도 통일시킬 수 있음
3. 아키텍쳐를 단순하게 유지할 수 있음
운영의 효율성 및 확장성
1. 지원하는 모든 서비스와 시스템별 Kafka 클러스터를 하나씩 준비 해야 한다면 지원 대상 서비스와 시스템 수에 비례해서 운영 비용이 증가함
2. 엔지니어링 자원을 전부 그 클러스터에 집중시켜서 클러스터의 신뢰성과 성능을 극대화하는 전략
