
근사치 집계 함수
APPROX_COUNT_DISTINCT
COUNT(DISTINCT expression)의 대략적인 결과를 반환합니다.
반환되는 값은 통계적 추정치이며 실제 값과 다를 수 있습니다.
이 함수는 COUNT(DISTINCT expression)보다 정확성이 떨어지지만 대량의 데이터를 입력할 때 성능 면에서 유리합니다.
예시
SELECT APPROX_COUNT_DISTINCT(x) as approx_distinct
FROM UNNEST([0, 1, 1, 2, 3, 5]) as x;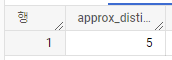
APPROX_QUANTILES
expression값 그룹의 근사치 경계를 반환합니다.
여기서 number는 생성할 분위 수를 나타냅니다.
이 함수는 number+1요소 배열을 반환합니다.
첫 번째 요소는 근사치의 최솟값이며 마지막 요소는 근사치의 최댓값입니다.
예시
SELECT APPROX_QUANTILES(x, 3) AS approx_quantiles
FROM UNNEST([1, 1, 1, 4, 5, 6, 7, 8, 9, 10]) AS x;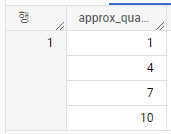
APPROX_TOP_COUNT
expression이 근사치 최상위 요소를 반환합니다.
number매개변수는 반환되는 요소의 수를 지정합니다.
예시
SELECT APPROX_TOP_COUNT(x, 2) as approx_top_count
FROM UNNEST(["apple", "apple", "pear", "pear", "pear", "banana"]) as x;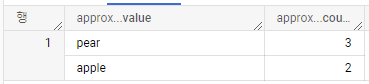
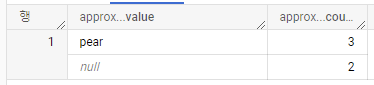
SELECT APPROX_TOP_COUNT(x, 2) as approx_top_count
FROM UNNEST([NULL, "pear", "pear", "pear", "apple", NULL]) as x;APPROX_TOP_COUNT는 입력에서 NULL을 무시하지 않습니다.
APPROX_TOP_SUM
할당된 weight의 합계를 바탕으로 expression의 근사치 최상위 요소를 반환합니다.
number매개변수는 반환되는 요소의 수를 지정합니다.
예시
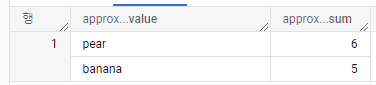
SELECT APPROX_TOP_SUM(x, weight, 2) AS approx_top_sum FROM
UNNEST([
STRUCT("apple" AS x, 3 AS weight),
("pear", 2),
("apple", 0),
("banana", 5),
("pear", 4)
]);
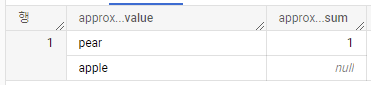
SELECT APPROX_TOP_SUM(x, weight, 2) AS approx_top_sum FROM
UNNEST([STRUCT("apple" AS x, NULL AS weight), ("pear", 1), ("pear", NULL)]);APPROX_TOP_SUM은 expression 및 weight 매개변수의 NULL값을 무시하지 않습니다.
출처
https://cloud.google.com/bigquery/docs/reference/standard-sql/approximate_aggregate_functions?hl=ko

(전)Backend Developer / (현)Data Engineer