
목차
들어가며
- BigQuery는 SQL문법을 사용하고 있기 때문에, 많은 사람들이 처음에 쉽게 접할 수 있다
- 그러나 자주보기 힘들 ARRAY, STRUCT, UNNEST를 만나면 많은 사람들이 어려워 한다
- 특히 Google Analytics 데이터나 Firebase 데이터 작업 시
Cannot access field name on a value with type ARRAY와 같은 Error을 접하게 된다 - 자료형들에 대한 설명과 이런 데이터를 쿼리할 때 어떻게 사용해야 하는지에 대해 정리 해보자
- 참고로, BigQuery는 비정규화 되었을 때 성능이 가장 뛰어나다.
-
비정규화를 위해 중첩(Nested)및 반복(Repeated)열을 사용한다.
-
중첩된 레코드를 사용할 때 장점
- 빅쿼리 퍼포먼스 개선
- 데이터 저장 용량의 효율
- 스키마가 바뀌어도 유연하게 대응 가능(출처 : https://cloud.google.com/bigquery/docs/nested-repeated)
-
BigQuery ARRAY
- 공식 문서
- BigQuery는 데이터 유형이 동일한 값으로 구성된 목록을 ARRAY(배열)라 부른다
-
파이썬의 LIST와 유사(완전히 동일하지는 않음)
-
하나의 행에 데이터 타입이 동일한 여러 값이 저장 됨
-
빅쿼리 UI에서 배열을 보여줄 때 세로로 나열 됨
SELECT [1,2,3] AS array_sample, 1 AS int_value UNION ALL SELECT [3,5,7] AS array_sample, 2 AS int_value
-
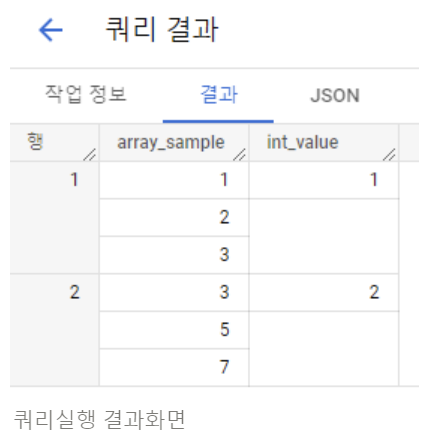
- 행 하나에 딸려있는 경우 ARRAY
- ARRAY 생성 방법
- 대괄호 (
[,]) 사용SELECT [1, 2, 3] AS array_sample - ARRAY 사용
SELECT ARRAY<INT64>[1, 2, 3] AS int_array - GENERATE 함수 사용
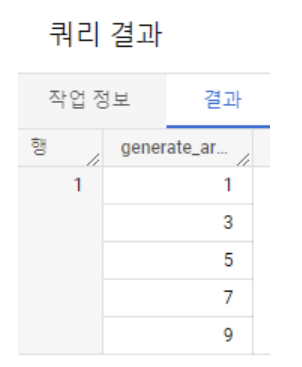
GENERATE_ARRAY,GENERATE_DATE_ARRAY,GENERATE_TIMESTAMP_ARRAY등 사용GENERATE_ARRAY(시작, 종료, 간격): python에서range(start, end, step)과 동일SELECT GENERATE_ARRAY(1, 10, 2) AS generate_array_date
- 대괄호 (
-
GENERATE_DATE_ARRAY도GENERATE_ARRAY와 동일SELECT GENERATE_DATE_ARRAY('2020-01-01', '2020-02-01', INTERVAL 1 WEEK) AS generate_date_array_data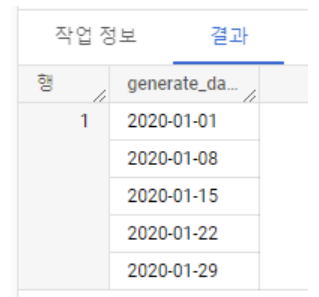
- ARRAY_AGG 사용
- ARRAY_AGG, ARRAY_CONCAT_AGG 등 사용
- Table에 저장된 데이터를 SELECT하고 ARRAY로 묶고싶은 경우 사용
WITH programing_languages AS (SELECT "python" AS programing_language UNION ALL SELECT "go" AS programing_language UNION ALL SELECT "scala" AS programing_language) SELECT ARRAY_AGG(programing_language) AS programing_languages_array FROM programing_languages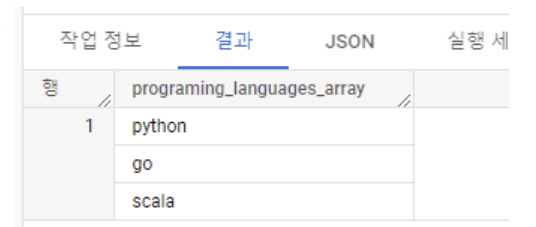
- 배열 내 접근 - 배열의 N번째 값을 가져오고 싶은 경우 OFFSET, ORDINAL을 사용할 수 있다 - OFFSET: 0부터 시작 - ORDINAL: 1부터 시작 - 존재하지 않는 N을 지정하면 에러가 발생하는데, 이럴 경우 SAFE_를 앞에 붙여주면 (SAFE_OFFSET, SAFE_ORDICAL)에러가 발생하지 않고 NULL이 return된다WITH programming_languages AS (SELECT "python" AS programming_language UNION ALL SELECT "go" AS programming_language UNION ALL SELECT "scala" AS programming_language) SELECT ARRAY_AGG(programming_language)[OFFSET(0)] AS programming_languages_array, ARRAY_AGG(programming_language)[ORDINAL(1)] AS programming_languages_array2 FROM programming_languages
- 배열 역순 - ARRAY_REVERSE 사용WITH programming_languages AS (SELECT "python" AS programming_language UNION ALL SELECT "go" AS programming_language UNION ALL SELECT "scala" AS programming_language) SELECT ARRAY_REVERSE(ARRAY_AGG(programming_language)) AS programming_languages_array_reverse FROM programming_languages
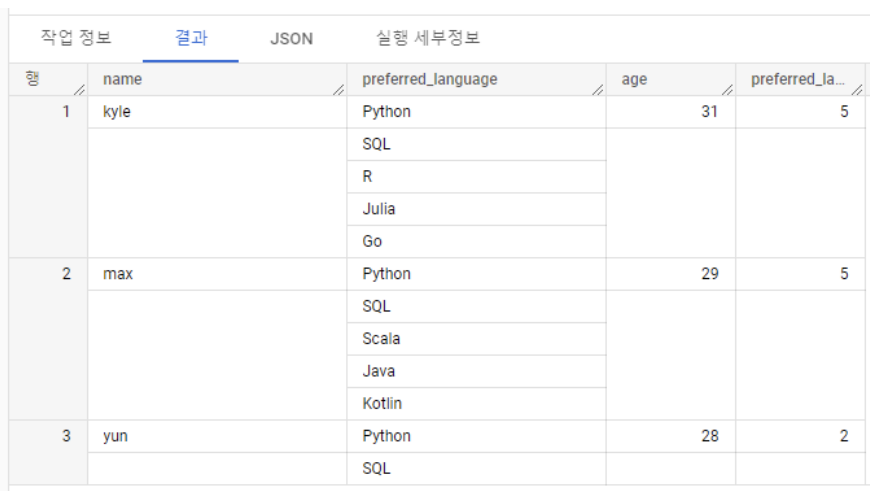
- 배열의 길이 - ARRAY_LENGTH 함수 사용WITH example_data AS( SELECT 'kyle' AS name, ['Python', 'SQL', 'R', 'Julia', 'Go'] AS preferred_language, 31 AS age UNION ALL SELECT 'max' AS name, ['Python', 'SQL', 'Scala', 'Java', 'Kotlin'] AS preferred_language, 29 AS age UNION ALL SELECT 'yun' AS name, ['Python', 'SQL'] AS preferred_language, 28 AS age ) SELECT *, ARRAY_LENGTH(preferred_language) AS preferred_language_len FROM example_data - ARRAY_AGG 사용
BigQuery STRUCT
- 공식 문서
- 구조체로, BigQuery UI에서 RECORD로 표현 된다
- 각각 유형(필수)과 필드 이름(선택사항)이 있는 정렬된 필드의 컨테이너
- C의 Struct
- Python 3.7에 나온 Data Class와 유사
- 처음엔 Python의 Dict와 유사한 느낌(실제로 유사하지않음)
- Python에서 Dict in List, List in Dict, List in List처럼 BigQuery의 ARRAY와 STRUCT도 Array in Struct, Struct in Array, Struct in Struct등이 가능하다
- 따라서 ARRAY를 접하다보면 STRUCT도 알아야 할 경우가 생긴다.
- Firebase에서 저장된 데이터를 볼 때 특히 많이 등장
- STRUCT 생성 방법
- 소괄호 (
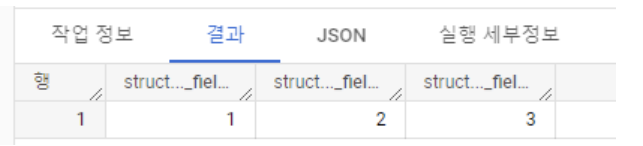
(,)) 사용SELECT (1,2,3) AS struct_test
- 소괄호 (
- STRUCT <타입> 사용
SELECT STRUCT<INT64, INT64, STRING>(1, 2, 'HI') AS struct_test;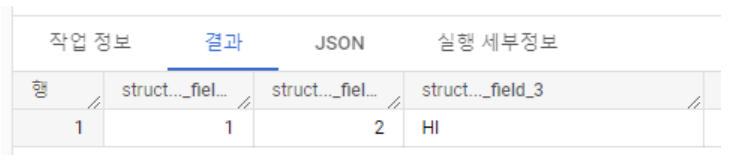
- ARRAY 안에 여러 STRUCT를 사용하고 싶은 경우
- ARRAY(SELECT AS STRUCT) 이런 형태로 사용
SELECT
ARRAY(
SELECT AS STRUCT 1 as hi, 2, 3
UNION ALL
SELECT AS STRUCT 4 as hi, 5, 6
) AS new_array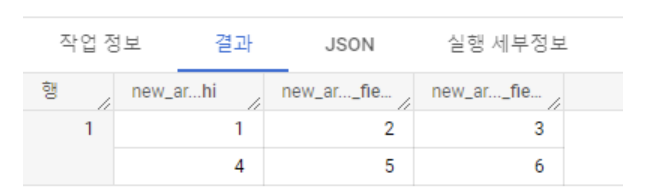
BigQuery UNNEST
- 공식 문서
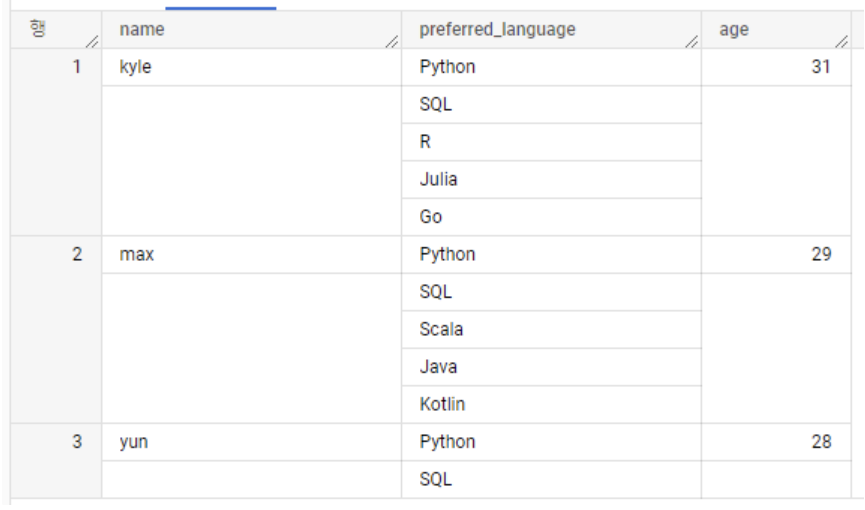
- 예시를 위해 사람들이 선호하는 프로그래밍 언어와 나이가 저장된 데이터가 있다고 가정
- 배열에 통째로 접근하고 싶은 경우엔 평소처럼 컬럼을 지정
- preferred_language
WITH example_data AS( SELECT 'kyle' AS name, ['Python', 'SQL', 'R', 'Julia', 'Go'] AS preferred_language, 31 AS age UNION ALL SELECT 'max' AS name, ['Python', 'SQL', 'Scala', 'Java', 'Kotlin'] AS preferred_language, 29 AS age UNION ALL SELECT 'yun' AS name, ['Python', 'SQL'] AS preferred_language, 28 AS age ) SELECT name, preferred_language, age FROM example_data
- preferred_language
- 만약 Julia 언어를 선호하는 사람을 추출하고 싶다면?
- 배열을 평면화(Flatten)해서 배열에 있는 값을 펴줘야 한다
- 배열을 펴 줄때 사용하는 것은 UNNEST로, Nest한 데이터를 UNNEST하게 만드는 것
- UNNEST 연산자는 ARRAY를 입력으로 받고 ARRAY의 각 요소에 대한 행이 한 개씩 포함된 테이블을 return함
- Nested에 대한 자세한 정보
- UNNEST() 사용하는 방법
- UNNEST한 결과와 Table을 CROSS JOIN함
- Julia를 선호하는 사람을 추출하는 사람을 찾기 위해 UNNEST를 사용해보자 (필터링 아직 x)
WITH example_data AS( SELECT 'kyle' AS name, ['Python', 'SQL', 'R', 'Julia', 'Go'] AS preferred_language, 31 AS age UNION ALL SELECT 'max' AS name, ['Python', 'SQL', 'Scala', 'Java', 'Kotlin'] AS preferred_language, 29 AS age UNION ALL SELECT 'yun' AS name, ['Python', 'SQL'] AS preferred_language, 28 AS age ) SELECT name, prefer_lang, age FROM example_data, UNNEST(example_data.preferred_language) as prefer_lang
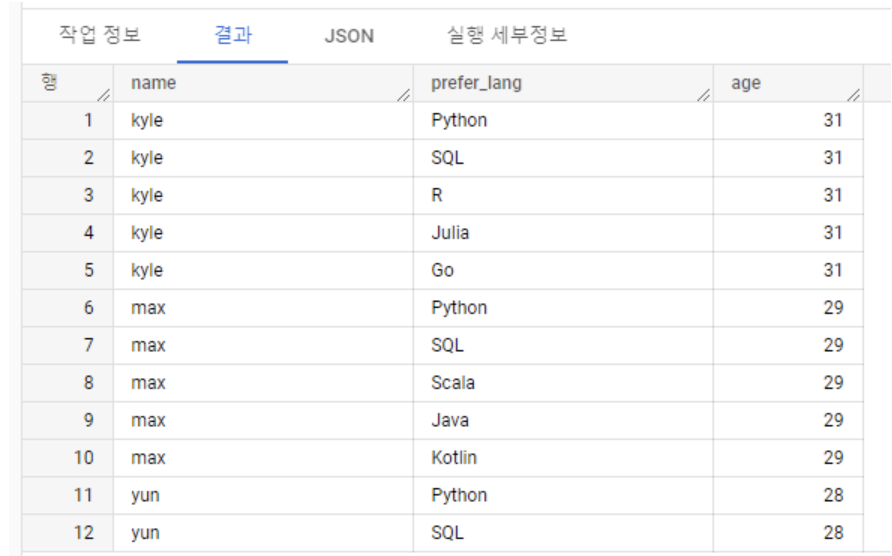
여기서 where로 julia 필터링 해주면 찾을 수 있다
출처

(전)Backend Developer / (현)Data Engineer