로드 밸런서를 사용하는 일반적인 3계층(3-Tier) 분산 처리 모델은 구성 요소에 문제가 생겼을 때 문제를 해결하기에 어려움이 있다.
일반적인 분산 처리 모델
다음은 로드 밸런서로 구성한 일반적인 3계층(3-Tier) 분산 처리 모델을 표현한 도식이다.
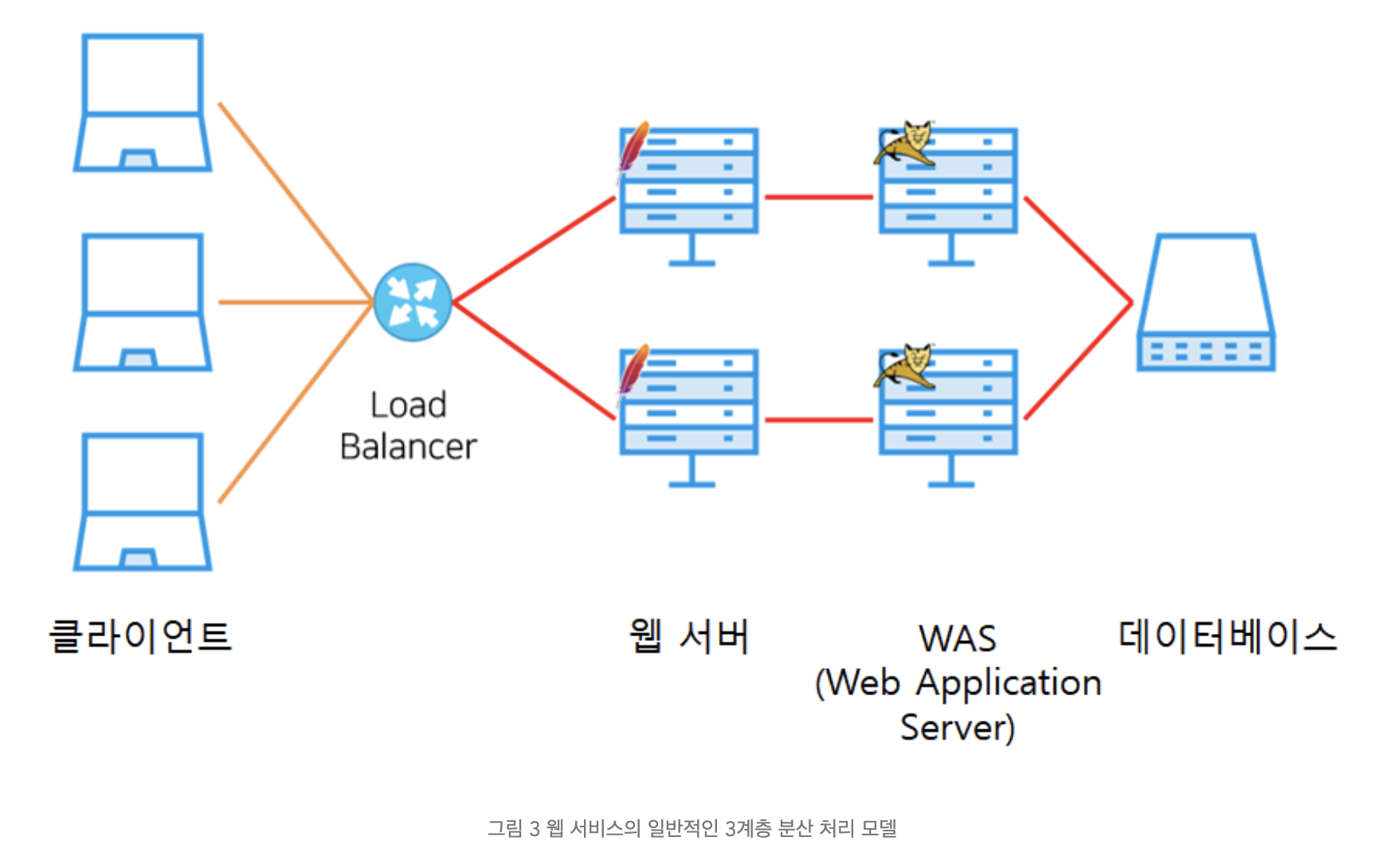
클라이언트의 트래픽이 로드 밸런서를 통해 각 웹 서버로 분산된다. WAS는 동일한 데이터베이스를 참조한다.
이런 분산 처리 환경에서 각 구성 요소에 문제가 생긴다면 어떻게 처리해야 할까?
로드 밸런서에 문제가 생기면 로드 밸런서를 다중화한 다음 DNS 라운드로빈 방식 등을 적용해 문제를 처리할 수 있다.
DNS 라운드로빈 방식
별도의 SW,HW로드벨런싱 장비 없이 오직 DNS만을 이용하여 도메인 레코드 정보를 조회하는 시점에서 트래픽을 분산하는 기법이다.
웹 뿐만 아니라, 도메인을 사용하는 모든 서비스(FTP,SMTP 등)에 사용이 가능하다.
하지만 WAS에 문제가 생기면 다음과 같은 점을 고려해야 하기 때문에 다중화로 문제를 해결하기가 쉽지 않다.
WAS에 문제가 생겼을 때 웹 서버가 다른 WAS를 찾도록 해야 한다.
사용자가 로그인한 상태라면 WAS에 세션 클러스터링을 설정해야 한다.
세션 클러스터링 설정을 위한 추가 작업이 필요하고 관리 지점이 증가한다.
데이터베이스에서는 다음과 같은 점을 고려해야 하기 때문에 역시 다중화로 문제를 해결하기가 쉽지 않다.
데이터 동기화 등의 문제 때문에 데이터 스토리지 레이어는 다중화가 특히 어려운 부분에 속한다.
사용하는 데이터베이스가 RDB라면 다중화를 어떻게 할 것인지, 데이터를 어떻게 분산할 것인지에 관해 깊이 고민해야 한다. 예를 들어 샤딩 등을 도입했을 때 데이터가 늘어나 샤드를 추가해야 한다면 기존 데이터의 마이그레이션은 어떻게 할지 고민해야 한다.
사용하는 데이터베이스가 NoSQL이라면 데이터 정합성, 동기화, 장애 복구 시 다수결에 의한 데이터 오염 가능성 등을 고려해야 한다.
GCDN
CSS와 JavaScript, 이미지와 같이 공통으로 호출되는 리소스는 한 번 업로드되면 잘 변하지 않는다. 이런 리소스를 네이버 메인 페이지의 웹 서버에서 직접 제공하면 트래픽 부하가 엄청나게 가중된다. 예를 들어 100KB 용량의 이미지를 10만 명이 조회하면 대략 10GB의 트래픽이 발생한다. 그래서 공통적으로 호출되는 리소스의 부하 분산을 위해 GCDN을 사용한다. 리소스를 GCDN으로 분산하면 네이버 메인 페이지의 트래픽을 상당히 절감할 수 있다.
또한, GCDN에서 지원하는 GSLB(Global Server LB) 기능은 접속한 IP 주소에서 가장 가까운 CDN 서버를 자동으로 선정해 연결하기 때문에 사용자가 빠른 서비스 속도를 체감할 수 있다.
SSI
SSI는 웹 서버(Apache, NGINX 등)에서 지원하는 서버사이드 스크립트 언어다. 서버에 있는 특정 파일을 읽어오거나 특정 쿠키 유무의 판별 등 간단한 기능을 실행할 수 있다. 이런 기능을 WAS에서만 실행할 수 있다고 생각하고 WAS에 요청을 보내는 경우가 많다. 하지만 SSI를 사용해 웹 서버에서 기능을 처리하면 WAS의 부담을 줄여 WAS의 성능에 여유를 줄 수 있게 되고, 웹 서버의 활용도도 높여 서버의 자원을 더 효율적으로 사용할 수 있다.
Apache 커스텀 모듈
APR은 프레임워크와 비슷하게 운영체제에 독립적으로 HTTP 기반 통신을 처리할 수 있도록 하는 라이브러리다. 메모리 할당, 메모리 풀링, 파일 입출력, 멀티스레드 관련 처리 등에 필요한 기능이 포함되어 있다. Apache HTTP 서버도 APR 기반으로 작성되어 있다. APR에 관한 더 자세한 내용은 Apache Portable Runtime 프로젝트 사이트를 참고한다.
마이크로서비스의 부분 도입
외부 시스템과 API 연동을 담당하는 부분은 특히 Node.js로 구축했다. 네이버 메인 페이지에서는 동시에 여러 대의 외부 시스템과 API 연동을 실행해야 하는 경우가 많다. Node.js를 사용하면 병렬 처리 시 스레드 문제 등을 고려할 필요가 없고, 비동기식으로 외부 시스템 연동 시 병렬로 여러 개의 요청을 한 번에 처리할 수 있다. 그래서 이러한 기능을 구현하기에는 기존에 사용하던 Java보다는 Node.js로 구현하는 것이 더 유리하다고 판단했다. 또한 부서 내 언어적 다양성을 확보해 용도에 맞는 적절한 기술을 사용할 수 있고, 부서원의 기술 역량 향상에 도움을 주는 장점도 있다.
API 서버에는 또한 서킷 브레이커를 적용했다. WAS에는 서버의 모니터링과 관리를 위해 서비스 디스커버리를 적용했다.
서킷 브레이커
서킷 브레이커는 외부 서비스의 장애로 인한 연쇄적 장애 전파를 막기 위해 자동으로 외부 서비스와 연결을 차단 및 복구하는 역할을 한다. 서킷 브레이커를 사용하는 목적은 애플리케이션의 안정성과 장애 저항력을 높이는 데 있다. 분산 환경에서는 네트워크 일시 단절 또는 트래픽 폭증으로 인한 간헐적 시간 초과 등의 상황이 종종 발생한다. 이로 인해 다음과 같은 연쇄 장애가 발생할 가능성이 있다.
트래픽 폭증으로 인해 API 서버 등 외부 서비스의 응답이 느려진다.
외부 서비스의 응답이 타임아웃 시간을 초과하면 데이터를 받아오기 위해 외부 서비스를 다시 호출한다.
이전에 들어온 트래픽을 다 처리하지 못한 상태에서 재시도 트래픽이 추가로 적체되어 외부 서비스에 장애가 발생한다.
외부 서비스의 장애로 인하여 데이터를 수신하지 못해 네이버 메인 서비스에도 장애가 발생한다.
일시적인 경우라면 2, 3회 재시도로 정상 데이터를 수신할 수 있다. 하지만 장애 상황이라면 계속 재시도하는 것이 의미도 없을 뿐 아니라 외부 서비스의 장애 복구에 악영향을 미칠 수 있다. 이럴 때는 외부 서비스에서 데이터를 받아오는 것을 포기하고 미리 준비된 응답을 사용자에게 전달하는 것이 시스템 안정성 및 사용 편의성 측면에서 옳다고 할 수 있다.
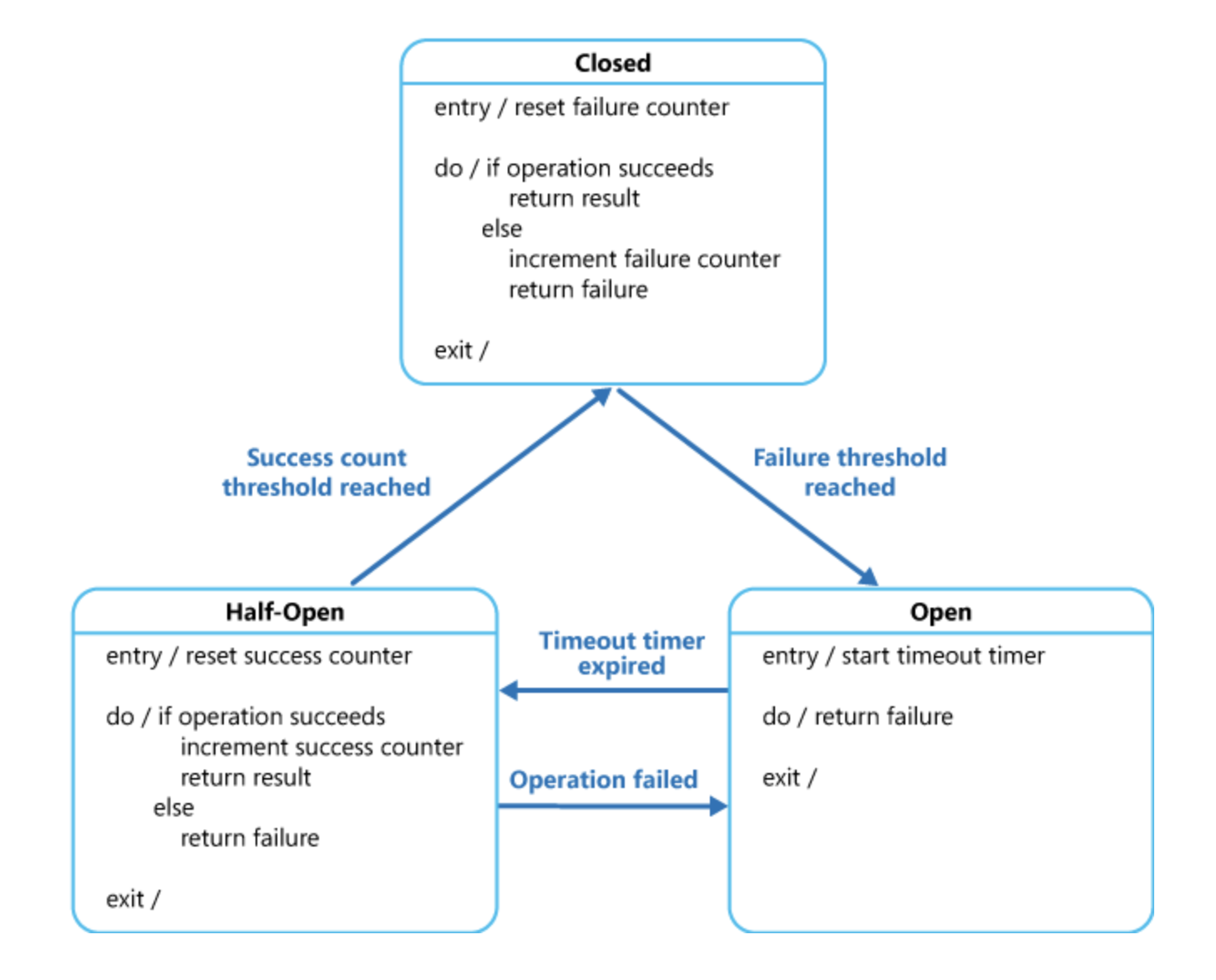
- Closed 상태: 메서드가 정상적으로 작동해 서킷이 닫힌 상태
- Open 상태: 메서드에 문제가 생겨서 서킷이 열린 상태
- Half-Open 상태: Open 상태와 Closed 상태의 중간 상태. 메서드를 주기적으로 확인해 정상이라고 판단되면 Closed 상태로 상태를 전환하고, 정상이 아니라면 Open 상태를 유지한다.
서비스 디스커버리
서비스 디스커버리 서버는 각 서버군의 서버 목록을 관리한다. 서버는 시작할 때 자신의 정보(IP 주소, 포트)를 서비스 디스커버리 서버로 보내고, 서비스 디스커버리 서버는 이 정보를 받아 서버군의 서버 목록을 최신으로 갱신한다. 각 서버군에 있는 서버는 주기적으로 서비스 디스커버리 서버로 목록을 요청해 서버 목록을 최신으로 유지한다. 이러한 방법으로 서버는 재시작 등 외부의 개입이 없어도 자동으로 항상 최신 서버 목록을 확보할 수 있다.
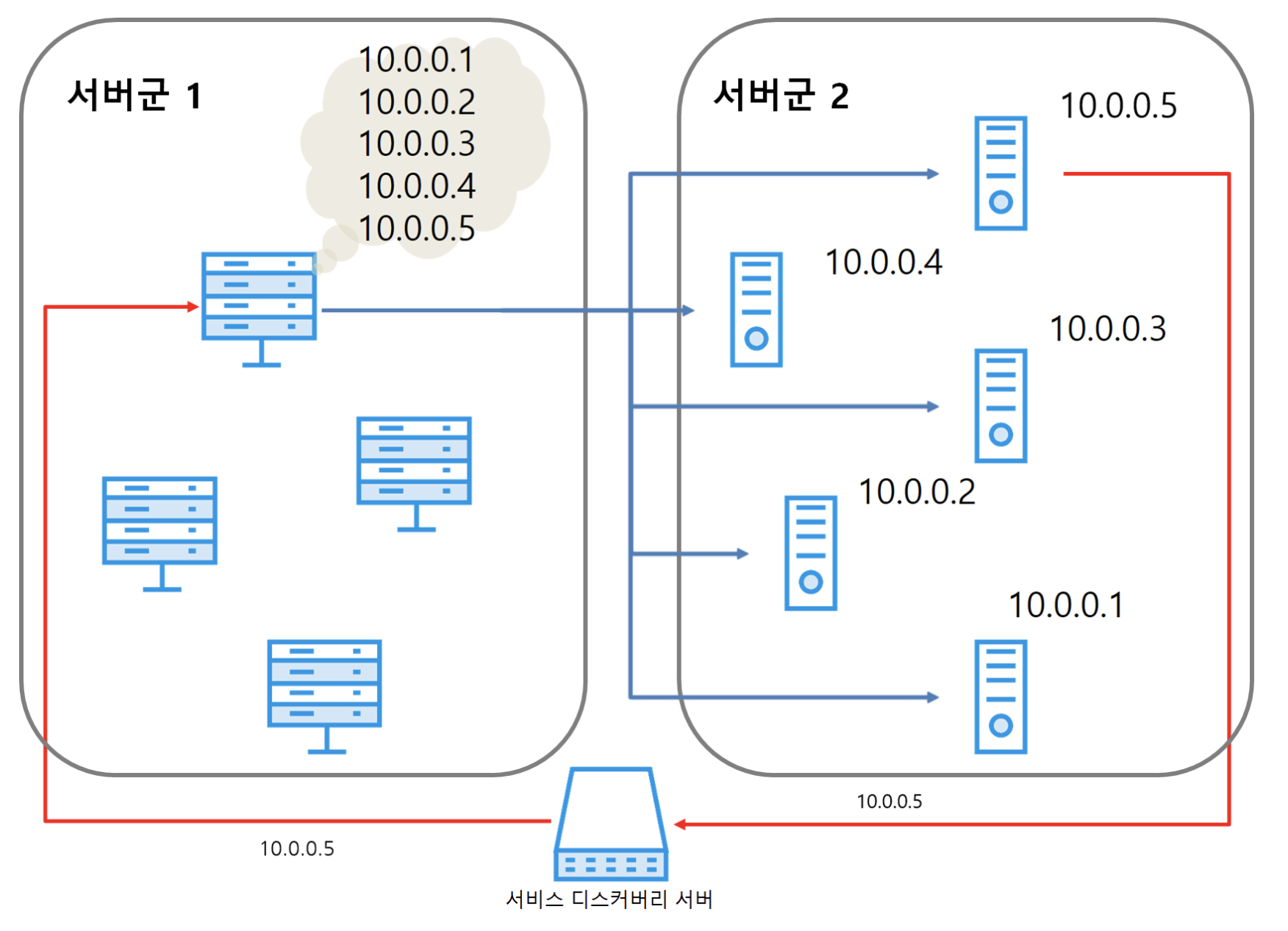
서비스 디스커버리는 특히 클라우드 환경에서 빛을 발한다. 기존 온프레미스(on-premises) 환경에서는 서버를 추가, 삭제하는 일이 많지 않았다. 서버를 추가, 삭제하는 경우에도 통제된 환경에서 주로 작업하므로 갱신 문제가 크지 않다. 하지만 클라우드 환경에서는 수시로 서버가 추가, 삭제된다(특히 오토스케일링 등의 기능을 사용한다면 더욱 더). 이를 사람이 일일이 확인해 서버를 다시 실행하는 것은 불가능에 가깝다. 서비스 디스커버리는 이런 상황에서 아주 유용하게 사용할 수 있는 기술이다.
참고 url: 네이버 메인 페이지의 트래픽 처리
https://d2.naver.com/helloworld/6070967
