이전에 실시간 크롤링으로 채용공고를 보여주려고 했지만, 잡코리아 사이트에서 IP 차단을 당한 경험이 있었다. 그래서 크롤링 데이터를 엑셀로 저장한 후, Spring Boot 기반 시스템에서 엑셀을 읽어 DB에 저장하고 JSP로 출력하는 방식으로 구조를 변경하였다.
💻 기술 스택
-
Backend: Java, Spring Boot, JPA (Hibernate)
-
Frontend: JSP, JSTL
-
DB: MySQL
-
크롤링: Python (requests, BeautifulSoup, pandas)
-
엑셀 처리: Apache POI
의존성 추가(pom.xml)
<!-- MySQL -->
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-j</artifactId>
<version>8.0.33</version>
</dependency>
<!-- JPA -->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-jpa</artifactId>
</dependency>
<!-- Excel 처리 -->
<dependency>
<groupId>org.apache.poi</groupId>
<artifactId>poi</artifactId>
<version>5.2.3</version>
</dependency>
<dependency>
<groupId>org.apache.poi</groupId>
<artifactId>poi-ooxml</artifactId>
<version>5.2.3</version>
</dependency>Controller
boardId=7일 경우 채용공고 게시판으로 진입하도록 구성하여 엑셀 데이터를 읽어 DB에 저장하고, 검색 및 페이징 처리를 하였다.
// 채용공고 게시판 - 엑셀 읽어서 보여주기
if (boardId == 7) {
try {
jobPostingService.saveFromExcel("src/main/resources/jobkorea_requirements.xlsx");
} catch (Exception e) {
e.printStackTrace();
}
List<JobPosting> allJobs = jobPostingService.getAll();
List<JobPosting> filteredJobs = new ArrayList<>();
// 메시지 전달용 변수
String message = null;
String keywordParam = req.getParameter("keyword"); // 실제 요청에 포함됐는지 확인
if (keywordParam != null) { // 사용자가 검색을 시도한 경우
if (keyword != null && !keyword.trim().isBlank()) {
String trimmedKeyword = keyword.trim();
if ("title".equals(searchType)) {
filteredJobs = allJobs.stream()
.filter(job -> job.getTitle().contains(trimmedKeyword))
.collect(Collectors.toList());
} else if ("companyName".equals(searchType)) {
filteredJobs = allJobs.stream()
.filter(job -> job.getCompanyName().contains(trimmedKeyword))
.collect(Collectors.toList());
}
if (filteredJobs.isEmpty()) {
message = "검색 결과가 없습니다.";
}
} else {
// 검색창에 아무것도 안 쓰고 검색 버튼만 눌렀을 때
message = "검색어를 입력하세요.";
filteredJobs = allJobs;
}
} else {
// 검색을 시도하지 않은 경우 (페이지 넘기기 등)
filteredJobs = allJobs;
}
// 페이징 처리
int itemsPerPage = 10;
int totalItems = filteredJobs.size();
int pagesCount = (int) Math.ceil((double) totalItems / itemsPerPage);
int fromIndex = Math.min((page - 1) * itemsPerPage, totalItems);
int toIndex = Math.min(fromIndex + itemsPerPage, totalItems);
List<JobPosting> pagedJobs = filteredJobs.subList(fromIndex, toIndex);
// 페이지 블록 처리 추가
int pageBlockSize = 10;
int currentBlock = (int) Math.ceil((double) page / pageBlockSize);
int startPage = (currentBlock - 1) * pageBlockSize + 1;
int endPage = Math.min(startPage + pageBlockSize - 1, pagesCount);
boolean hasPrev = startPage > 1;
boolean hasNext = endPage < pagesCount;
int prevPage = startPage - 1;
int nextPage = endPage + 1;
// 모델 전달
model.addAttribute("jobPostings", pagedJobs);
model.addAttribute("board", board);
model.addAttribute("page", page);
model.addAttribute("pagesCount", pagesCount);
model.addAttribute("keyword", keyword); // 검색창 유지용
model.addAttribute("searchType", searchType); // 검색타입 유지용
model.addAttribute("message", message); // 알림 메시지
// 페이지 블록 관련 변수 추가
model.addAttribute("startPage", startPage);
model.addAttribute("endPage", endPage);
model.addAttribute("hasPrev", hasPrev);
model.addAttribute("hasNext", hasNext);
model.addAttribute("prevPage", prevPage);
model.addAttribute("nextPage", nextPage);
return "/usr/post/joblist";
}Service
- 엑셀 파일을 파싱하고, 중복 저장을 막기 위해 기존 데이터를
deleteAll()로 삭제 후 새로 저장하도록 하였다.
@Service
@RequiredArgsConstructor
public class JobPostingService {
@Autowired
private JobPostingRepository jobPostingRepository;
public void saveFromExcel(String filePath) throws Exception {
try (InputStream is = new FileInputStream(filePath);
Workbook workbook = new XSSFWorkbook(is)) {
List<JobPosting> jobPostings = new ArrayList<>();
Sheet sheet = workbook.getSheetAt(0);
for (int i = 1; i <= sheet.getLastRowNum(); i++) {
Row row = sheet.getRow(i);
if (row == null) continue;
JobPosting job = new JobPosting();
job.setTitle(getString(row.getCell(0)));
job.setCompanyName(getString(row.getCell(1)));
job.setStartDate(getString(row.getCell(2)));
job.setEndDate(getString(row.getCell(3)));
job.setCertificate(getString(row.getCell(4)));
jobPostings.add(job);
}
// 기존 데이터 삭제 후 저장 (중복 방지)
jobPostingRepository.deleteAll();
jobPostingRepository.saveAll(jobPostings);
}
}
private String getString(Cell cell) {
if (cell == null) return "";
return switch (cell.getCellType()) {
case STRING -> cell.getStringCellValue();
case NUMERIC -> String.valueOf((int) cell.getNumericCellValue());
default -> "";
};
}
public List<JobPosting> getAll() {
return jobPostingRepository.findAll();
}
}
Repository - JAP 사용
public interface JobPostingRepository extends JpaRepository<JobPosting, Long> {
}
VO
@Entity // jpa용
@Data
@AllArgsConstructor
@NoArgsConstructor
public class JobPosting {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
private Long id;
private String title;
private String companyName;
private String certificate;
private String startDate;
private String endDate;
}
오류 해결 과정
@Id누락
Entity 'JobPosting' has no identifier (every '@Entity' class must declare or inherit at least one '@Id')@Entity만 쓰고@ID를 지정하지 않아 발생한 오류였다.@ID와@GeneratedValue를 추가하여 해결!
- 테이블 이름 불일치
Table 'project.job_posting' doesn't exist
- DB에는
job_postings로 생성했는데 Entity에는job_posting으로 되어 있어서 생긴 문제였다. 테이블 이름을 Entity 이름에 맞춰 수정하여 해결!
- 의존성 충돌
mysql:mysql-connector-j:jar:8.0.33 was not found in ...
com.mysql과mysql둘 다 라이브러리에 선언해서 생긴 충돌 문제였다.com.mysql만 남기고mysql삭제해서 해결!
결과
/usr/post/list?boardId=7로 접속하면 채용공고 목록이 아래와 같이 정상적으로 출력된다.
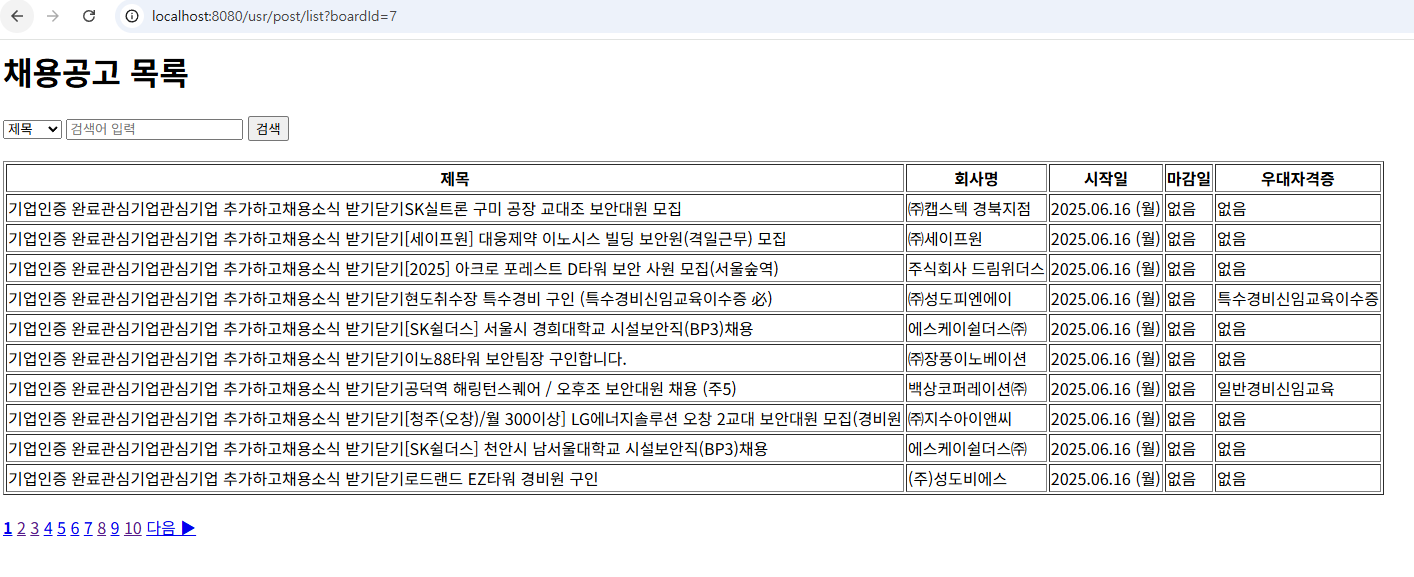
- 정상적으로 출력되었지만, 크롤링 했던 파일을 봤을때, '마감일'이 포함되어 있었는데, 출력 결과를 보니 '마감일'이 없는걸 발견하였다. 그래서 다시 크롤링하여 새 엑셀 파일을
resources디렉터리에 저장한 뒤 불러왔더니 '마감일'이 정상적으로 표시되는 것을 확인하였다.
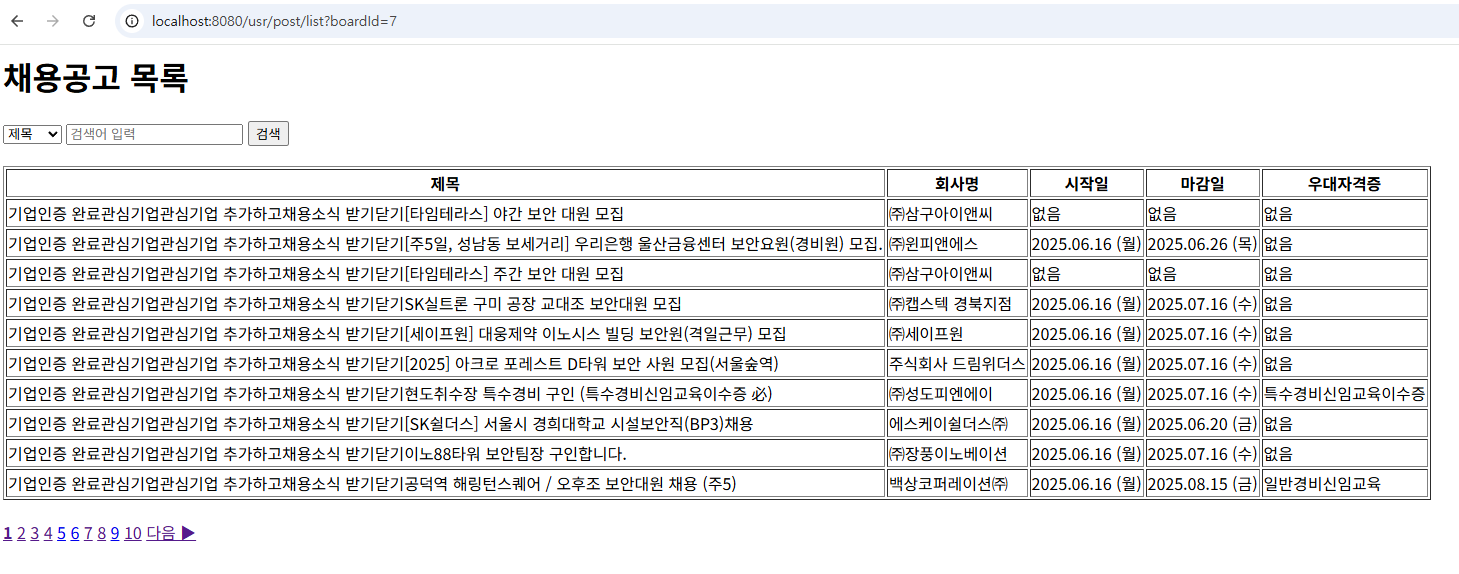
이 두 결과를 비교해보니, 크롤링할 때마다 결과가 바뀐다는 사실을 알게 되었다.
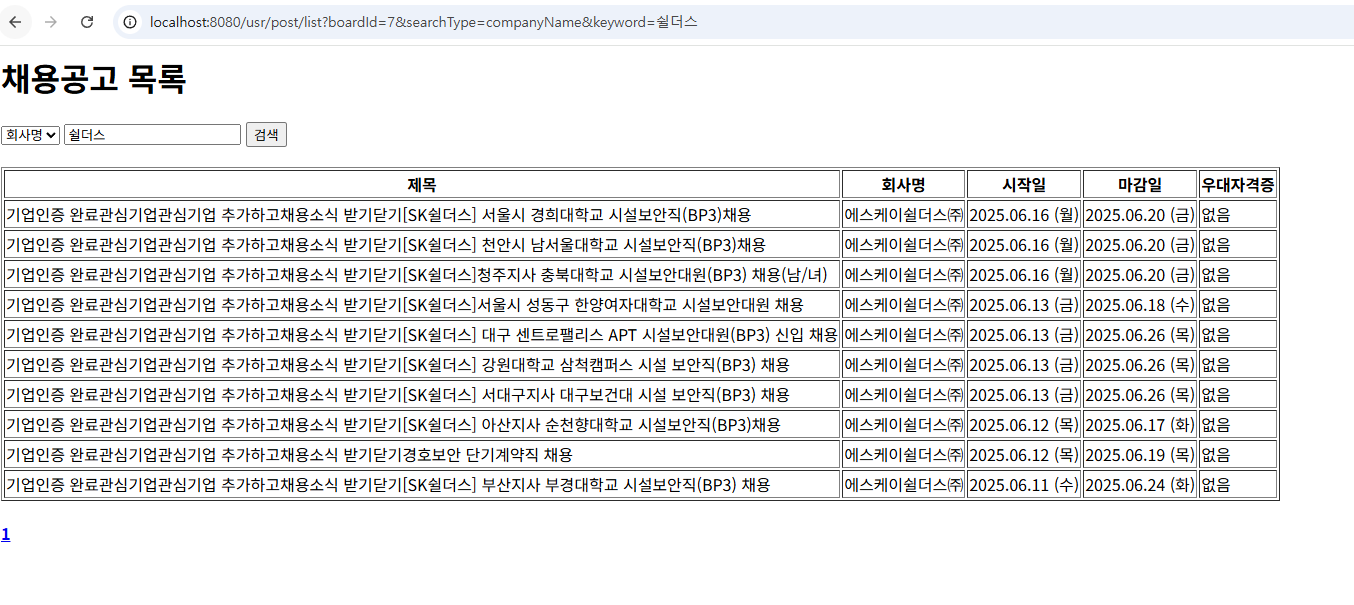
- 마지막으로, 검색 기능 테스트를 위해 회사명 '쉴더스'를 입력한 결과도 정상적으로 동작하는 것을 확인했습니다.
- 검색 창에 아무거나 쳐서 검색했을 경우, alert으로 알려주는 것도 추가했다.
그리고 아무것도 입력하지 않고, 검색 창을 눌렀을때도 똑같다.