SUM
- 테이블에 존재하는 컬럼의 합을 구하고 싶을 때 사용하는 함수
컬럼의 타입이 숫자형인 경우에만 사용할 수 있다.
# emp 테이블의 전체 연봉 합계
SELECT SUM(salary) FROM emp;
# emp 테이블의 그룹화한 연봉 합계
SELECT SUM(salary) FROM emp;
GROUP BY deptId;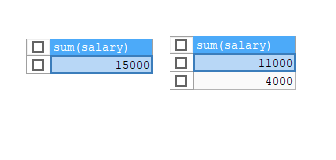
MAX
- 컬럼의 모든 행중 최대값 구하는 함수
# emp 테이블 중 최대 연봉
SELECT MAX(salary) FROM emp;
# 그룹화한 최대 연봉
SELECT deptId,MAX(salary) FROM emp
GROUP BY deptId;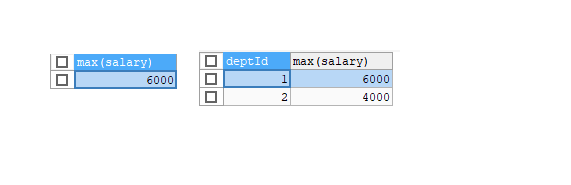
MIN
- 컬럼의 모든 행중 최소값 구하는 함수
# emp 테이블 전체 최소 연봉
SELECT MIN(salary) FROM emp;
# 그룹화된 최소 연봉
SELECT deptId,MIN(salary) FROM emp
GROUP BY deptId;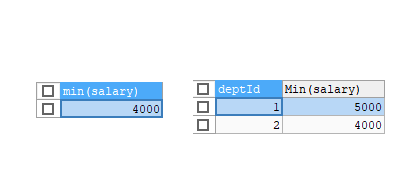
AVG
- 컬럼의 모든 행의 평균값 구하는 함수
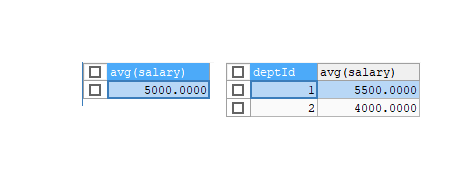
# 전체 평균 연봉
SELECT AVG(salary) FROM emp;
#그룹화한 평균 연봉
SELECT deptId,AVG(salary) FROM emp
GROUP BY deptId;
join 안한 버전 (GROUP_CONCAT)
# 평균 연봉 소수점 있는거
SELECT e.deptId AS '부서번호', GROUP_CONCAT(e.name) AS '사원명',
AVG(salary) AS '평균연봉', MAX(salary) AS '최고연봉',
MIN(salary) AS '최소연봉', COUNT(id) AS '사원수' FROM emp e
GROUP BY deptId;
# 평균 연봉 소수점 없애기
SELECT e.deptId AS '부서번호', GROUP_CONCAT(e.name) AS '사원명',
TRUNCATE(AVG(e.salary),1) AS '평균연봉', MAX(salary) AS '최고연봉',
MIN(salary) AS '최소연봉', COUNT(id) AS '사원수' FROM emp e
GROUP BY deptId; 

GROUP_CONCAT()GROUB BY를 통해 그룹화된 데이터를 하나로 합쳐서 조회할 수 있는 그룹 함수
# 여러 컬럼 사용
SELECT <그룹화 할 컬럼>, GROUP_CONCAT(<합쳐서 보여줄 컬럼>)
FROM <테이블 명>
GROUP BY <그룹화 할 컬럼>
# 구분자 변경
SELECT <그룹화할 컬럼>, GROUP_CONCAT(<합쳐서 보여줄 컬럼> separator '<구분자>')
FROM <테이블 명>
GROUP BY <그룹화 할 컬럼>
# 중복 제거
SELECT <그룹화할 컬럼>, GROUP_CONCAT(DISTINCT <합쳐서 보여줄 컬럼>)
FROM <테이블 명>
GROUP BY <그룹화 할 컬럼>
# 정렬 (ORDER BY)
SELECT <그룹화할 컬럼>, GROUP_CONCAT(<합쳐서 보여줄 컬럼> ORDER BY <합쳐서 보여줄 컬럼>)
FROM <테이블 명>
GROUP BY <그룹화 할 컬럼>- 만약, 중복 제거, 정렬, 구분자 변경을 함께 사용하고 싶을 때는 DISTINCT> ORDER BY > SEPARATOP 순으로 사용해야 한다.
SELECT <그룹화할 컬럼>, GROUP_CONCAT(DISTINCT<합쳐서 보여줄 컬럼> ORDER BY <합쳐서 보여줄 컬럼> separtor '<구분자>')
FROM <테이블 명>
GROUP BY <그룹화 할 컬럼>TRUNCATE(숫자, 버릴 자릿수)- 숫자를 버릴 자릿수 아래로 버림
- 반드시 버릴 자릿수를 명시해야 한다.
join하기
SELECT e.deptId AS '부서번호', d.deptName AS '부서명',
GROUP_CONCAT(e.name) AS '사원명', TRUNCATE(AVG(salary),1) AS '평균연봉', MAX(e.salary) AS '최고연봉',
MIN(e.salary) AS '최소연봉', COUNT(e.salary) AS '사원수' FROM emp AS e
INNER JOIN dept AS d
ON e.deptId = d.id
GROUP BY deptId;
- join 안한 버전에서 dept 테이블에 있는 부서명까지 추가한 것이다.
- dept 와 table 에
AS 별칭을 넣으면 테이블 명을 다 입력하지 않고 별칭으로 입력할 수 있다.
HAVING 사용
SELECT e.deptId AS '부서번호', d.deptName AS '부서명',
GROUP_CONCAT(e.name) AS '사원명', TRUNCATE(AVG(salary),1) AS '평균연봉', MAX(e.salary) AS '최고연봉',
MIN(e.salary) AS '최소연봉', COUNT(e.salary) AS '사원수' FROM emp AS e
INNER JOIN dept AS d
ON e.deptId = d.id
GROUP BY deptId
HAVING AVG(e.salary) >= 5000;
HAVING- 일반적으로 SELECT문은 FROM > WHERE > GROUP BY > HAVING > SELECT > ORDER BY 순으로 실행된다.
- WHERE가 GROUP BY 보다 먼저 실행되기 때문에 GROUP BY 이후로 쓸 수 없다. 그래서 GROUP BY 다음에 HAVING을 사용하면 된다.
UNION 사용
- UNION을 사용하려면 각 쿼리의 컬럼의 개수 및 데이터 타입이 일치해야 한다.
- 대응하는 컬럼 명이 같아야 한다.
- ODER BY절은 마지막에 한 번 사용이 가능하다.
#부서번호 합치기
SELECT deptId AS '부서번호' FROM emp
UNION
SELECT id AS '부서번호' FROM dept;