샤딩이란?
샤딩은 동일한 스키마를 가지고 있는 여러대의 데이터베이스 서버들에 데이터를 작은 단위로 나누어 분산 저장하는 기법이다. 이때, 작은 단위를 샤드(shard)라고 부른다.
어떻게 보면 샤딩은 수평 파티셔닝의 일종이다. 차이점은 파티셔닝은 모든 데이터를 동일한 컴퓨터에 저장하지만, 샤딩은 데이터를 서로 다른 컴퓨터에 분산한다는 점이다. 물리적으로 서로 다른 컴퓨터에 데이터를 저장하므로, 쿼리 성능 향상과 더불어 부하가 분산되는 효과까지 얻을 수 있다. 즉, 샤딩은 데이터베이스 차원의 수평 확장(scale-out)인 셈이다.
주의점
데이터를 물리적으로 독립된 데이터베이스에 각각 분할하여 저장하므로, 여러 샤드에 걸친 데이터를 조인하는 것이 어렵다. 또한, 한 데이터베이스에 집중적으로 데이터가 몰리면 Hotspot이 되어 성능이 느려진다. 따라서 데이터를 여러 샤드로 고르게 분배하는 것이 중요하다. 또 Celebrity Problem 등 다양한 문제가 존재한다.
샤딩의 종류
샤딩의 종류는 다양하지만, 크게 Hash Sharding, Range Sharding 두 가지를 알아보겠다.
Hash Sharding
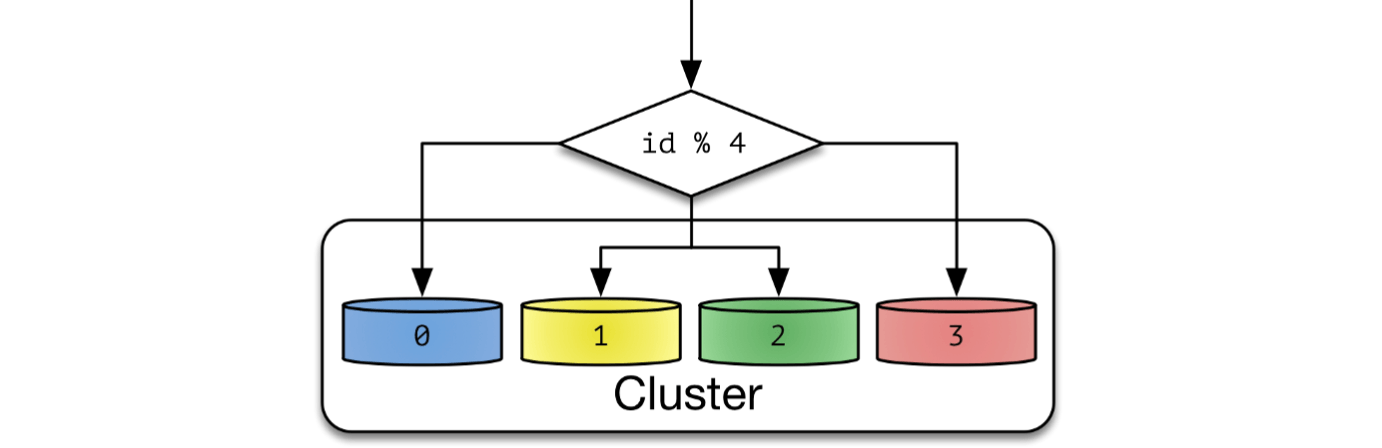
Hash Sharding 중 나머지 연산을 사용한 Modular Sharding 을 알아본다. Modular Sharding은 PK값의 모듈러 연산 결과를 통해 샤드를 결정하는 방식이다. 총 데이터베이스 수가 정해져있을 때 유용하다. 데이터베이스 개수가 줄어들거나 늘어나면 해시 함수도 변경해야하고, 따라서 데이터의 재 정렬이 필요하다.
Range Sharding
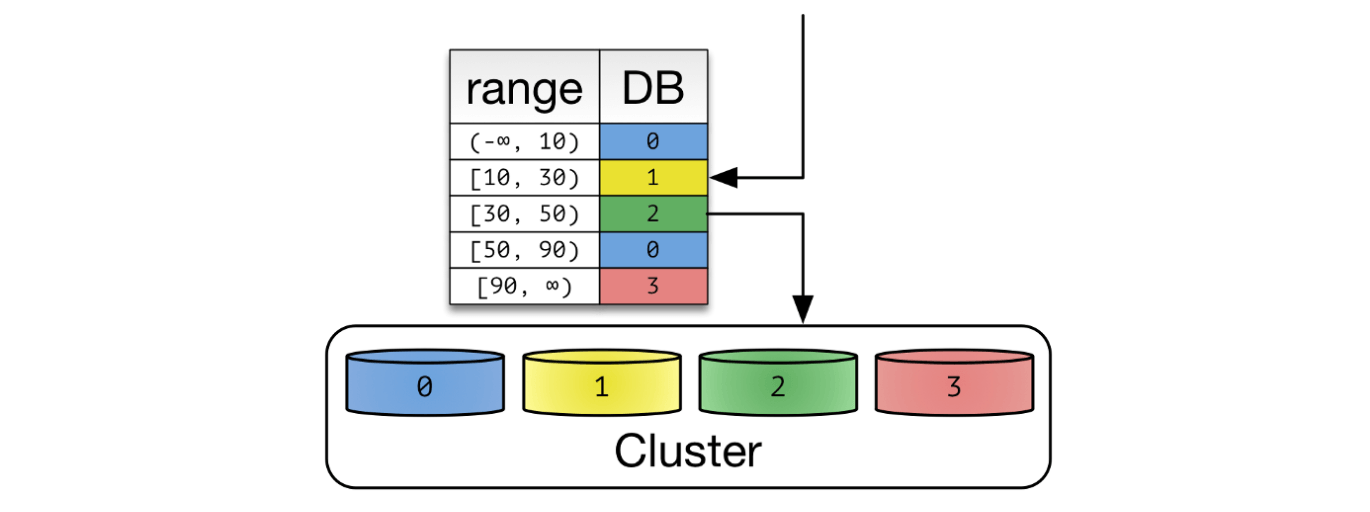
PK 값을 범위로 지정하여 샤드를 지정하는 방식이다. 예를 들어 PK가 1~1,000 까지는 1번 샤드에, 1,001~2,000 까지는 2번 샤드에, 2,001~ 부터는 3번 샤드에 저장할 수 있다. Hash Sharding 대비 데이터베이스 증설 작업에 큰 리소스가 소요되지 않는다. 따라서 급격히 증가할 수 있는 성격의 데이터는 Range Sharding 을 사용함이 좋아보인다. 이런 특징으로 Range Sharding은 Dynamic Sharding 으로도 불린다.
다만, 이렇게 기껏 분산을 시켜놨는데 특정한 데이터베이스에만 부하가 몰릴 수 있다. 예를 들어 페이스북 게시물을 Range Sharding 했다고 가정해보자. 대부분의 트래픽은 최근에 작성한 게시물에서 발생할 것이다. 위 그림에서는 2, 3번 샤드에만 부하가 몰리는 것이다. 부하 분산을 위해 데이터가 몰리는 DB는 다시 재 샤딩(re-sharding)하고, 트래픽이 저조한 데이터베이스는 다시 통합하는 작업이 필요할 것이다.
결론
샤딩은 데이터를 분산하여 저장한다는 관점에서 파티셔닝과 비슷하지만
파티셔닝의 경우와는 다르게 물리적으로 다른 공간에 데이터를 분리한다는 것이 특징이다.
