
성능 개선이나 list를 순회하면서 지우고 싶을 때 iterator를 많이 쓰게 된다. 그래서 이번 포스팅으로 iterator에 관련된 모든 것을 정리하고자 한다.
1. Iterator란?
Iterator는 자바 컬렉션 프레임워크에서 컬렉션(List, Set, Map 등)을 순차적으로 탐색하기 위한 인터페이스다. 컬렉션의 내부 구조를 몰라도 통일된 방법으로 순회할 수 있게 해준다.
1) 왜 필요할까?
for (int i = 0; i < list.size(); i++) ... 같은 인덱스 기반 탐색은 ArrayList엔 가능하지만, HashSet, LinkedList, HashMap 같은 컬렉션에는 적합하지 않다. ArrayList는 인덱스 기반 탐색이기에 O(1)이 걸리지만, 나머지는 처음부터 해당 index까지 순회해야하기 때문에 O(N)이 걸려 성능이 훨씬 저하된다. iterator를 사용해, 노드를 참조하고, 참조한 노드 다음 노드를 찾는게 훨씬 효율적이다.
2) 동작 과정
LinkedList일 때의 iterator를 설명하겠다. LinkedList의 iterator는 ListItr 객체를 반환하는데, 저장하는 내용은 다음과 같다.
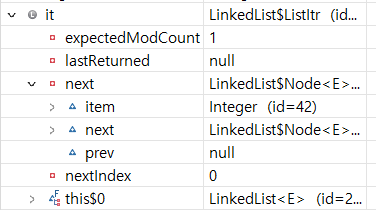
expectedModCount: CME를 체크할 때 쓰는 변순데, 수정 동작이 있을 때마다 modCount가 변동되고, 이것이 expectedModCount랑 같은지 다른지 유무에 따라 CME를 판별한다. 밑에 더 자세한 설명이 있다.lastReturned: 반환했던 Node를 참조하는 변수다. Iterator.next()를 호출 할 때, 반환되는 값을 가지고 있는 Node를 참조하는 변수다. 즉, 현재 가리키는 값이라고 보면 된다.next: Iterator.next()를 호출할 때, 갈 Node를 참조하는 변수다.
next()를 호출했을 때, 예시를 들어보겠다.
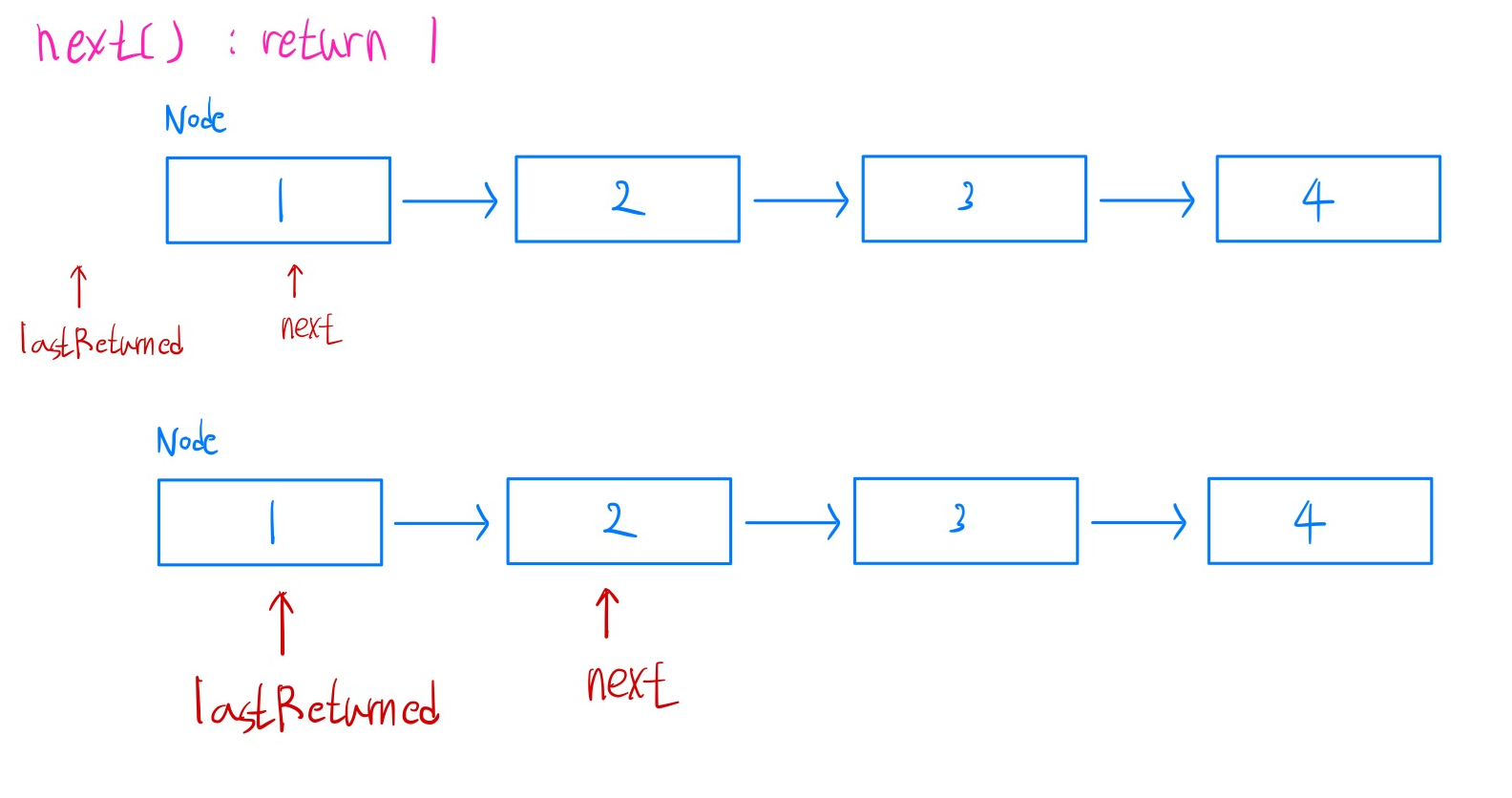
처음 상태에서는 lastReturned가 null, next가 첫번째 노드를 가리킨다. 그리고 Iterator.next()를 호출하면, lastReturned가 next로, next는 노드의 next로 이동하게 되며, lastReturned의 값을 반환을 해준다.
이런 식으로 iterator가 동작을 하게 된다.
2. for-each와 Iterator
많이 사용하는 for-each 문도 내부적으로는 Iterator를 사용한다.
1) for-each vs Iterator
- for-each는 읽기 전용 →
remove()같은 수정 불가- Iterator는 요소 삭제 가능 →
remove()지원
for-each (for (E e : collection))는 컴파일러에서 iterator로 변환한다.
- for-each 코드
for (String s : list) {
System.out.println(s);
}- iterator 코드
for (Iterator<String> it = list.iterator(); it.hasNext();) {
String s = it.next();
System.out.println(s);
}for-each로 작성했을 때, 위에 써진 iterator 코드로 작성된 거와 똑같이 동작한다.
2) 컴파일러 변환
for-each가 컴파일러에서 실제로 iterator로 변환을 하는지 알아보자
- 명령어
javac Main.java // 컴파일
javap -c Main.class // 디스어셈블- for-each 코드
public class Main {
static List<Integer> list;
public static void main(String[] args) throws IOException {
list=List.of(1,2,3,4);
for (int num : list) {
System.out.println(num);
}
}
}- 컴파일 후
Compiled from "Main.java"
public class find.Main {
static java.util.List<java.lang.Integer> list;
public find.Main();
Code:
0: aload_0
1: invokespecial #1 // Method java/lang/Object."<init>":()V
4: return
public static void main(java.lang.String[]) throws java.io.IOException;
Code:
0: iconst_1
1: invokestatic #7 // Method java/lang/Integer.valueOf:(I)Ljava/lang/Integer;
5: invokestatic #7 // Method java/lang/Integer.valueOf:(I)Ljava/lang/Integer;
8: iconst_3
9: invokestatic #7 // Method java/lang/Integer.valueOf:(I)Ljava/lang/Integer;
12: iconst_4
13: invokestatic #7 // Method java/lang/Integer.valueOf:(I)Ljava/lang/Integer;
16: invokestatic #13 // InterfaceMethod java/util/List.of:(Ljava/lang/Object;Ljava/lang/Object;Ljava/lang/Object;Ljava/lang/Object;)Ljava/util/List; 19: putstatic #19 // Field list:Ljava/util/List;
22: getstatic #19 // Field list:Ljava/util/List;
25: invokeinterface #25, 1 // InterfaceMethod java/util/List.iterator:()Ljava/util/Iterator;
30: astore_1
31: aload_1
32: invokeinterface #29, 1 // InterfaceMethod java/util/Iterator.hasNext:()Z
37: ifeq 63
40: aload_1
41: invokeinterface #35, 1 // InterfaceMethod java/util/Iterator.next:()Ljava/lang/Object;
46: checkcast #8 // class java/lang/Integer
49: invokevirtual #39 // Method java/lang/Integer.intValue:()I
52: istore_2
53: getstatic #43 // Field java/lang/System.out:Ljava/io/PrintStream;
56: iload_2
57: invokevirtual #49 // Method java/io/PrintStream.println:(I)V
60: goto 31
63: return
}code 0~22번까지는 list 초기화를 하고 있다.
이제 봐야할 것은 code 25번 invokeinterface다. java.util에 있는 Iterator를 불러오는 걸 볼 수 있다. 그 다음, hasNext를 호출한다. next 값이 있으면, Iterator의 next를 호출해, 다음 걸 보게 된다.
바이트 코드가 불편하면, intelliJ에서 .class 파일을 열 수 있다. 디컴파일된 “추측된 자바 코드” 보여준다.
- intelliJ로 본 추측 자바 코드
//
// Source code recreated from a .class file by IntelliJ IDEA
// (powered by FernFlower decompiler)
//
package find;
import java.io.IOException;
import java.util.Iterator;
import java.util.List;
public class Main {
static List<Integer> list;
public Main() {
}
public static void main(String[] var0) throws IOException {
list = List.of(1, 2, 3, 4);
Iterator var1 = list.iterator();
while(var1.hasNext()) {
Integer var2 = (Integer)var1.next();
System.out.println(var2);
}
}
}이런 식의 코드가 동작하는거라고 볼 수 있다.
그럼 iterator 코드도 똑같이 컴파일 되는지 보자
- iterator 코드
public class Main {
static List<Integer> list;
public static void main(String[] args) throws IOException {
list=List.of(1,2,3,4);
for (Iterator<Integer> it = list.iterator(); it.hasNext();) {
Integer num = it.next();
System.out.println(num);
}
}
}- 컴파일 후
public class find.Main {
static java.util.List<java.lang.Integer> list;
public find.Main();
Code:
0: aload_0
1: invokespecial #1 // Method java/lang/Object."<init>":()V
4: return
public static void main(java.lang.String[]) throws java.io.IOException;
Code:
0: iconst_1
1: invokestatic #7 // Method java/lang/Integer.valueOf:(I)Ljava/lang/Integer;
4: iconst_2
5: invokestatic #7 // Method java/lang/Integer.valueOf:(I)Ljava/lang/Integer;
8: iconst_3
9: invokestatic #7 // Method java/lang/Integer.valueOf:(I)Ljava/lang/Integer;
12: iconst_4
13: invokestatic #7 // Method java/lang/Integer.valueOf:(I)Ljava/lang/Integer;
16: invokestatic #13 // InterfaceMethod java/util/List.of:(Ljava/lang/Object;Ljava/lang/Object;Ljava/lang/Object;Ljava/lang/Object;)Ljava/util/List;
19: putstatic #19 // Field list:Ljava/util/List;
22: getstatic #19 // Field list:Ljava/util/List;
25: invokeinterface #25, 1 // InterfaceMethod java/util/List.iterator:()Ljava/util/Iterator;
30: astore_1
31: aload_1
32: invokeinterface #29, 1 // InterfaceMethod java/util/Iterator.hasNext:()Z
37: ifeq 60
40: aload_1
41: invokeinterface #35, 1 // InterfaceMethod java/util/Iterator.next:()Ljava/lang/Object;
46: checkcast #8 // class java/lang/Integer
49: astore_2
50: getstatic #39 // Field java/lang/System.out:Ljava/io/PrintStream;
53: aload_2
54: invokevirtual #45 // Method java/io/PrintStream.println:(Ljava/lang/Object;)V
57: goto 31
60: return
}똑같다.
3. Map 순회
Map은 직접 Iterator를 제공하지 않지만, keySet(), values(), entrySet()을 통해 순회할 수 있다.
Map<String, Integer> map = new HashMap<>();
map.put("A", 1);
map.put("B", 2);
for (Iterator<Map.Entry<String, Integer>> it = map.entrySet().iterator(); it.hasNext();) {
Map.Entry<String, Integer> entry = it.next();
System.out.println(entry.getKey() + "=" + entry.getValue());
}(참고)
entrySet() 순회가 keySet() + get()보다 성능상 유리하다.1. HashMap 구조
HashMap은Node<K,V>[] table이라는 배열을 가지고 있고, 각Node는(key, value, hash, next)정보를 갖고 있다.static class Node<K,V> implements Map.Entry<K,V> { final int hash; final K key; V value; Node<K,V> next; }키와 값은 같은 노드에 같이 들어있다.
2. keySet() 순회 + get()
for (String key : map.keySet()) { String value = map.get(key); ... }
keySet()은 내부적으로Iterator<K>를 돌려준다. 노드를 순회하면서 key만 꺼내는 것이다.
HashMap의 keySet()은 내부적으로 HashMap.KeyIterator를 반환한다. 이 Iterator는 Node<K,V>를 순회하면서 node.key만 반환하는 구조다.final class KeyIterator extends HashIterator<K> { public final K next() { return nextNode().key; } }keySet()의 iterator()는 Node를 직접 따라가므로 key만 바로 꺼내게 된다. 즉,
map.get(key)를 호출하면, key의 hash 계산해서 다시 Node를 찾고, value를 반환하게 된다. 결국, 한 요소 순회할 때마다 O(1) 조회 연산이 추가로 발생한다.3. entrySet() 순회
for (Map.Entry<String, String> e : map.entrySet()) { String key = e.getKey(); String value = e.getValue(); ... }
entrySet()은 Map.Entry를 반환한다. 즉, 아예 노드를 직접 참조한다.Node안에는key와value가 같이 있으므로, 이미 순회하는 순간value를 바로 가져올 수 있다. 따라서 추가 해시 탐색이 없고, 단순히 필드 참조만 하므로 더 빠르다.4. 언제 keySet()이 나을까?
value가 필요 없는 경우엔 keySet을 쓰는게 낫다. key만 순회하면 되기 때문에 더 빠를 수 있다.
4. ConcurrentModificationException (CME) 문제
알고리즘 풀 때, 많이 겪었던 문제일 것이다.
컬렉션을 반복하면서 구조적으로 변경할 때, CME가 발생한다.
List<String> list = new ArrayList<>(List.of("A", "B", "C"));
for (String s : list) {
if (s.equals("B")) list.remove(s); // CME 발생
}1) CME(ConcurrentModificationException)가 나는 이유
for-each에서는 왜 CME가 발생할까?
앞서, for-each는 결국 Iterator를 사용한 코드라고 했었다. 결국 이 밑의 두 코드 모두 CME 오류가 난다.
- for-each
for (String s : list) {
if (s.equals("B")) list.remove(s); // CME 발생
}- iterator
for (Iterator<Integer> it = list.iterator(); it.hasNext();) {
Integer num = it.next();
if (num==1) list.remove(num); // CME 발생
}문제는 여기서 list.remove(s)가 실행된다는 것이다.
이건 Iterator가 모르게 컬렉션을 직접 바꿔버리는 거라 modCount는 증가하지만 expectedModCount는 그대로이기 때문에 불일치가 발생하고, CME가 터지게 된다.
- LinkedList의 ListItr.class의 CME 확인 부분
final void checkForComodification() {
if (modCount != expectedModCount)
throw new ConcurrentModificationException();
}2) 해결 방법
그래서 Iterator.remove()를 사용해, Iterator가 직접 삭제 처리를 하게 해야 한다. expectedModCount 업데이트가 되기 때문에 안전하다.
Iterator<String> it = list.iterator();
while (it.hasNext()) {
if (it.next().equals("B")) it.remove();
}LinkedList의 Iterator의 경우, Iterator.remove()는 내부적으로 이렇게 구현돼 있다.
public void remove() {
checkForComodification();
if (lastReturned == null)
throw new IllegalStateException();
Node<E> lastNext = lastReturned.next;
unlink(lastReturned); // modeCount 증가
if (next == lastReturned)
next = lastNext;
else
nextIndex--;
lastReturned = null;
expectedModCount++;
}
/**
* Unlinks non-null node x.
*/
E unlink(Node<E> x) {
// assert x != null;
final E element = x.item;
final Node<E> next = x.next;
final Node<E> prev = x.prev;
if (prev == null) {
first = next;
} else {
prev.next = next;
x.prev = null;
}
if (next == null) {
last = prev;
} else {
next.prev = prev;
x.next = null;
}
x.item = null;
size--;
modCount++;
return element;
}unlink에서 요소를 삭제하면서 modCount를 증가시키고, 그 뒤 expectedModCount도 같이 증가시켜서 일치를 유지한다.
즉, Iterator가 변경 사실을 알고, 자기 상태를 업데이트하기 때문에 안전하게 동작한다.
4. ListIterator: 양방향 반복자
ListIterator는 List 전용 반복자로, Iterator보다 많은 기능을 제공한다.
- ListIterator 제공 method
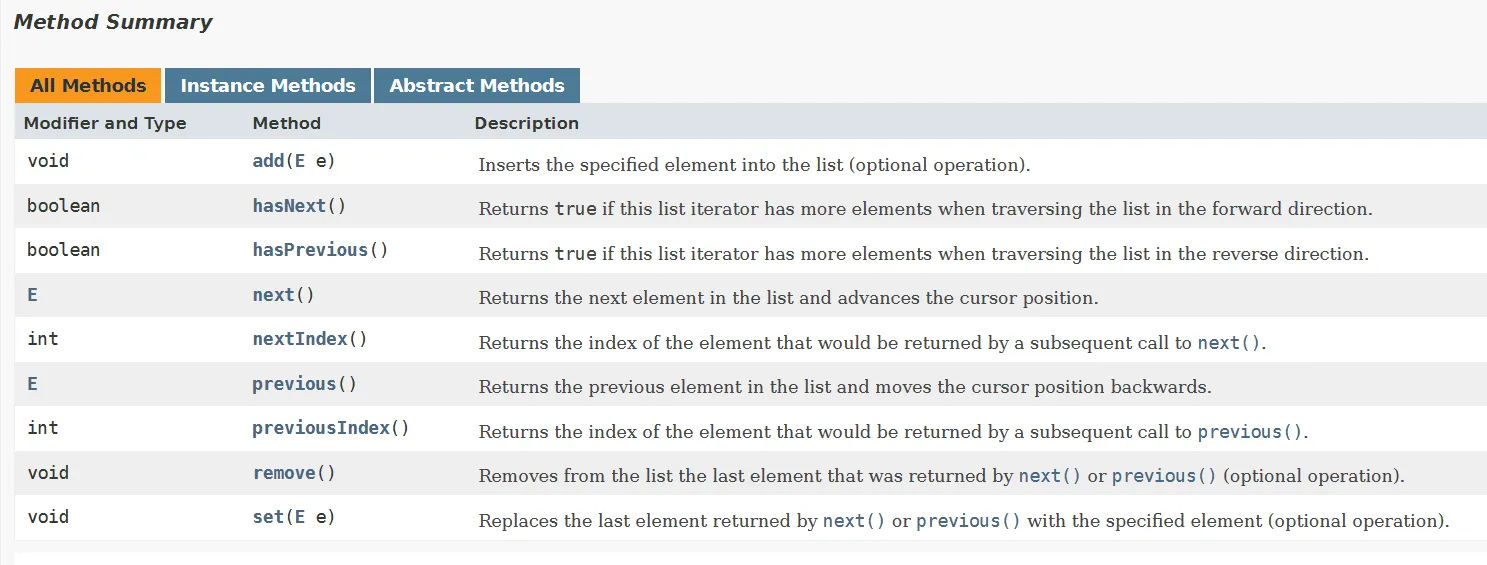
iterator랑 비교해서 보면 많은 기능을 제공하는 걸 볼 수 있다.
- Iterator 제공 method

가장 두드러지는 특징은 ListIterator에서는 perivious랑 add가 있다는 것이다.
| 메서드 | 설명 |
|---|---|
add(E e) | 현재 위치 바로 앞에 삽입한다. 삽입 후, iterator 위치는 삽입된 요수 뒤를 가리킨다 |
remove() | 이전에 previous, next를 호출에 따라 제거할 대상이 결정된다. previous를 호출했다면 이전 값이 삭제 되고, next를 호출했다면 다음 값이 삭제된다. |
5. Spliterator: 병렬을 위한 반복자
Java 8부터 등장한 Spliterator는 이름 그대로 Split + Iterator입니다. 컬렉션을 분할(splitting)하여 병렬 처리할 수 있도록 설계되었습니다.
주요 메서드
tryAdvance(Consumer action): 요소 하나 처리forEachRemaining(Consumer action): 남은 요소 모두 처리trySplit(): Spliterator 분할
예제
List<String> list = List.of("A", "B", "C", "D");
Spliterator<String> sp1 = list.spliterator();
Spliterator<String> sp2 = sp1.trySplit();
sp1.forEachRemaining(System.out::println);
sp2.forEachRemaining(System.out::println);
이러한 분할 기능 덕분에 Spliterator는 Stream API와 결합하여 병렬 스트림을 효율적으로 구현할 수 있습니다.
