❓ 스프링 배치란
스프링 배치(Spring Batch)는 대용량 데이터를 처리하기 위한 프레임워크로, 스프링 프레임워크 기반에서 작동한다.
일반적으로 배치 작업은 대량의 데이터를 처리하거나, 주기적이고 반복적인 작업을 실행하는 데 사용되며, 스프링 배치는 이러한 작업을 효율적이고 안정적으로 처리할 수 있는 프레임워크다.
🔎 스프링 배치의 내부 구조도
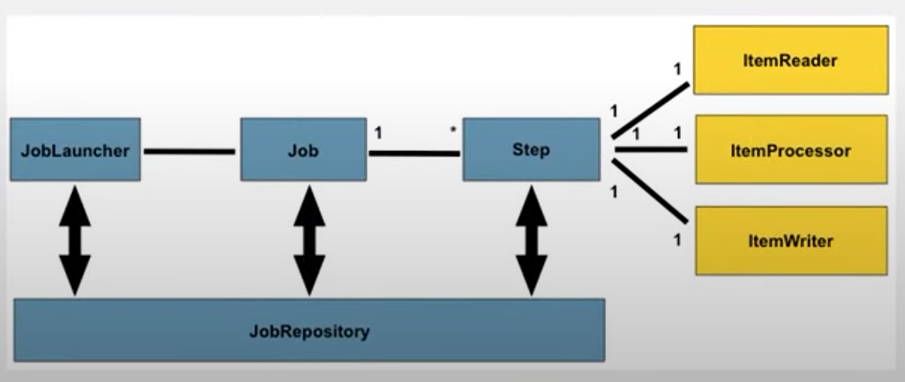
1. JobLauncher
- Job을 시작하는 부분
2. 실제 작업하는 부분 (정의해야 할 부분)
- Job > Step > ItemReader > ItemProcessor > ItemWriter
3. JobRepository
- 메타데이터 테이블에 접근해서 해당 작업이 얼만큼 진행되는지 참조해준다.
이제 스프링 배치를 구현할 준비를 해보자.
🚩 1. 구현 준비
1) 의존성 추가
implementation 'org.springframework.boot:spring-boot-starter-batch'
testImplementation 'org.springframework.batch:spring-batch-test'2) application.yml
spring:
batch:
job:
enabled: false # 프로젝트 실행 시 자동으로 배치 작업이 가동되는 것을 방지⚙️ 2. BatchConfig 클래스 생성
- 하나의 배치 Job을 정의할 클래스를 생성하고, Job 메서드를 등록해야 한다.
Job으로 하나의 배치 작업을 정의하고,
실제 배치 처리는 Job 아래에 존재하는 하나의 Step에서 수행한다.
Step에서 "읽기 > 처리 > 쓰기" 과정을 구상해야 하며, Step을 등록하기 위한 Bean을 등록해야 한다.
0. 먼저, 배치 작업 시 사용할 Repository 의존성들을 필드에 주입받는다.
@Configuration
@EnableBatchProcessing // 스프링 배치를 작동시켜준다.
@RequiredArgsConstructor
public class BatchConfig {
private final JobRepository jobRepository;
private final PlatformTransactionManager platformTransactionManager;
private final BeforeRepository beforeRepository;
private final AfterRepository afterRepository;
}1) Job (작업 정의)
- Job 정의는 아주 간단하게 메서드로 정의하면 된다.
@Bean
public Job firstJob() {
// 첫번째 매개변수 : 해당 Job을 지칭할 이름 선언 ("firstJob")
// 두번째 매개변수 : 해당 작업에 대한 트래킹을 진행하기 위해 jobRepository를 넣어주면
// 스프링 배치가 자동으로 작업이 진행되는지를 메타 데이터 테이블에 기록해준다.
return new JobBuilder("firstJob", jobRepository)
.start(firstStep) // 이 작업에서 처음 시작할 Step 선언
.next(secondStep) // Step이 1개 이상일 때, next()로 이후의 Step을 선언
.build(); // build()로 마무리하면 해당 작업이 정의된다.
}2) Step (실제 데이터 처리)
- chunk
- 대량의 데이터를 끊어서 처리할 최소 단위 (1회 호출 시 응답받을 데이터 수)
- 읽기 > 처리 > 쓰기 작업은 청크 단위로 진행된다.
- PlatformTransactionManager
- 청크가 진행되다가 실패했을 때, 롤백을 진행한다든지 다시 처리할 수 있도록 세팅해준다.
@Bean
public Step firstStep() {
return new StepBuilder("firstStep", jobRepository)
// <[Reader에서 읽어들일 데이터 타입], [Writer에서 쓸 데이터 타입]>
.<BeforeEntity, AfterEntity>chunk(10, platformTransactionManager)
.reader(beforeReader) // 읽는 메서드 자리
.processor(middleProcessor) // 처리 메서드 자리
.writer(afterWriter) // 쓰기 메서드 자리
.build();
}3) RepositoryItemReader (읽기)
- BeforeEntity 테이블에서 읽어오는 작업을 수행한다.
- 청크 단위까지만 읽기 때문에 findAll을 하더라도 전부 읽지 않고 chunck 개수 만큼 사용하게 된다.
따라서, 자원 낭비를 방지하기 위해 Sort를 진행하고, pageSize() 단위를 설정해 findAll이 아닌 페이지 만큼 읽어올 수 있도록 설정한다.
@Bean
public RepositoryItemReader<BeforeEntity> beforeReader() {
return new RepositoryItemReaderBuilder<BeforeEntity>()
.name("beforeReader")
.pageSize(10)
.methodName("findAll") // Repository의 findAll 메서드
.repository(beforeRepository)
.sorts(Map.of("id", Sort.Direction.ASC))
.build();
}4) ItemProcessor (중간 처리)
- Reader에서 읽어오는 Data를 처리한다.
- 큰 작업을 수행하지 않을 때는 굳이 ItemProcessor를 정의하지 않고 ItemReader에서 바로 읽어서 ItemWriter로 보내도 된다.
@Bean
public ItemProcessor<BeforeEntity, AfterEntity> middleProcessor() {
// <[Reader에서 읽어들일 데이터 타입], [Writer에서 쓸 데이터 타입]>
return new ItemProcessor<BeforeEntity, AfterEntity>() {
// process 메서드를 통해 item(BeforeEntity)에 읽어들인 데이터가 담기게 됨
@Override
public AfterEntity process(BeforeEntity item) throws Exception {
AfterEntity afterEntity = new AfterEntity();
afterEntity.setName(item.getName()); // 읽어들인 데이터를 쓸 데이터에 옮겨담음
return afterEntity;
}
};
}5) RepositoryItemWriter (쓰기)
- AfterEntity에 처리한 결과를 저장한다.
@Bean // RepositoryItemWriter<[저장될 엔티티]>
public RepositoryItemWriter<AfterEntity> afterWriter() {
return new RepositoryItemWriterBuilder<AfterEntity>()
.repository(afterRepository) // afterRepository를 통해서
.methodName("save") // save 쿼리 실행
.build();
}🧑🏻💻 3. jobLauncher 구현
application.yml에서 배치 자동 실행에 대한 변수 값을 false로 설정했기 때문에
배치를 실행시키기 위한 Job 실행도구,jobLauncher를 구현해야 한다.
❓ false로 설정한 이유
- 서버가 실행되자마자 배치가 실행되면, 원하는 날짜에 실행할 수 없다.
원하는 특정 일자에 배치를 실행하기 위해 스케줄링 혹은 특정 API 호출을 통해 실행되도록 설정한다.
1. API 방식으로 실행시키는 방법
1) Controller 생성
@Controller
@RequiredArgsConstructor
public class ApiController {
private final JobLauncher jobLauncher;
private final JobRegistry jobRegistry;
@GetMapping("/first")
public String firstApi(@RequestParam("value") String value) throws Exception {
// 쿼리 파라미터로 받아온 value 값을 date 변수에 넣어준다.
JobParameters jobParameters = new JobParametersBuilder()
.addString("date", value)
.toJobParameters();
// "firstJob" : 2-1 Job(작업 정의)에서 Bean으로 정의한 Job의 이름
jobLauncher.run(jobRegistry.getJob("firstJob"), jobParameters);
return "ok";
}
}2) API 호출
1개의 Job에 대해 한 번 호출한 파라미터는 재사용이 불가하다.
-
http://localhost:8080/first?value=a호출 시,
배치 작업이 실행되어 BeforeEntity -> AfterEntity로 Insert 작업이 수행된다. -
한 번 더
http://localhost:8080/first?value=a호출 시, 예외가 발생한다.
이미 a라는 파라미터가 들어갔기 때문에 해당 배치가 실행되지 않는다. -
http://localhost:8080/first?value=b호출 시, 배치가 제대로 실행된다.
2. Scheduler로 실행시키는 방법
1) 메인 Application 파일에 @EnableScheduling 어노테이션 부착
@SpringBootApplication
@EnableScheduling // 스케줄링 어노테이션 활성화 설정
public class MainApplication {
public static void main(String[] args) {
SpringApplication.run(MainApplication.class, args);
}
}2) ScheduleConfig 클래스 생성
- 클래스 생성 후 서버를 실행하면 정해놓은 cron 주기마다 배치 작업이 실행된다.
- JobParameters를 주는 방법은 커스텀을 해야 한다.
예시처럼 계속 new를 통해 값을 넣으면 매번 새롭게 실행되기 때문에,
년도-월-일까지만 받는 등의 방법을 통해 해당 배치가 특정 조건만 갖춰서 파라미터를 받아 실행될 수 있도록 JobParameters를 잘 구성해야 한다.
@Configuration
@RequiredArgsConstructor
@Slf4j
public class ScheduleConfig {
private final JobLauncher jobLauncher;
private final JobRegistry jobRegistry;
// 한국 시간 기준으로 10초마다 배치 작업 실행
@Scheduled(cron = "10 0 0 * * *", zone = "Asia/Seoul")
public void runFirstJob() throws Exception {
log.info("first schedule start");
SimpleDateFormat dateFormat = new SimpleDateFormat("yyyy-MM-dd-hh-mm-ss");
String date = dateFormat.format(new Date());
JobParameters jobParameters = new JobParametersBuilder()
.addString("date", date)
.toJobParameters();
// "firstJob" : 2-1 Job(작업 정의)에서 Bean으로 정의한 Job의 이름
jobLauncher.run(jobRegistry.getJob("firstJob"), jobParameters);
}
}* Table 'xxx.BATCH_JOB_INSTANCE' doesn't exist 오류 발생 시 해결 방법
🔗 https://velog.io/@ryuneng2/Spring-Batch-스프링-배치-Table-xxx.BATCHJOBINSTANCE-doesnt-exist-오류-해결-방법
References

잘 읽었습니다.