생각하던 연구와 매우 비슷한 주제로 연구를 수행한 논문이 있어 해당 논문을 분석하는 과정을 글로 남겨 보았다.
Abstract
아시다시피, Multi-View Stereo method는 연속적인 calibrated image들을 통해 dense한 point cloud를 복원하는 것을 목적으로 한다.
하지만, 현재 존재하는 MVS는 texture-less 지역이나, 반사면과 같은 곳에서 feature matching이 성공하지 못해 어려움을 겪는다. (homography warping을 한 후에 photometric loss를 구해야 하는데, edge가 없으면 소스 뷰에서 어떤 곳이 참조 뷰에서의 어떤 곳인지 알 길이 없어서 photometric loss를 구하기가 힘들다...)
반대로, monocular depth estimation은 feature matching을 요구하지 않으므로, 해당 지역에서 비교적 robust한 relative depth estimation을 수행하게 해 준다. (대신 여기서의 depth는 한 뷰의 픽셀들의 깊이 대소관계만 보장한다)
이 두 갭을 메우기 위해서, monocular depth estimation의 강력한 prior를 MVS로 가져오겠다.
- mono.refView의 feature가 srcView의 feature로 attention을 통해 통합된다. 이 과정에서 새롭게 디자인된 cross-view position encoding 사용.
- mono.refView가 샘플링 절차에서 edge region들이 될 만한 깊이 후보들을 동적으로 업데이트시키기 위해 정렬된다.
- relative consistency loss가 새로 디자인되는데, 이는 monocular depth가 depth prediction 과정에 관여하기 위함이다.
더 나아간 실험들은 MonoMVSNet이 DTU와 Tank-and-Temples 데이터셋에 대해서 sota performance를 내는 것을 확인했다.
Experiments
평가 데이터셋은 DTU와 tank-and-temples를 사용한다.
평가 메트릭은 포인트 클라우드와, depth map에 대해서 두 개에 대해서 모두 수행한다.
| 평가 요소 | 데이터셋 | 방법 설명 |
|---|---|---|
| pointcloud | dtu | official MATLAB 코드 사용 |
| pointcloud | t&t | website에 submission |
| depthmap | dtu | MAE(Mean Absolute Error)와 depth error ratio 사용 |
Related Work
1. 학습 기반 MVS
MVS <- 다른 viewpoint에서 캡처된 여러 이미지들을 통해 dense point cloud로 3D reconstruction을 하는 것.
MVSNet: 내가 바로 처음으로 등장한 학습 기반 MVS
MVSNet이 제시한 방법
1. feature extraction
2. cost volume construction
3. cost volume regularization
4. depth prediction
MVSNet의 한계
1. 3번 과정에 쓰이는 3D CNN의 높은 메모리 요구.
2. reconstruction quality.
한계 1은 RNN based regularization과 cascade-based approach로 어느 정도 해결.
2. Feature Reperesentation in MVS
효과적인 feature 표현은 MVS performance에 지대한 영향을 미친다.
여기서 언급하는 것이
cascade based methods(Cascade cost volume for high-resolution multi-view stereo and stereo matching, CVPR 2020)
아까 MVSNet의 한계 1을 해결하는 방법으로도 언급되었다.
이는 multi-scale feature extraction을 위해 FPN(Feature Pytamid Network)을 활용한다.
feature들을 Transformer를 통해 서로 다른 뷰에 대해 attention을 수행하는 것도 등장하였다. (srcView와 refView의 feature들에 대해서 attention을 수행하는 것이다.) 특히, MVSFormer는 사전학습된 ViT를 고해상도 이미지로 파인튜닝했는데, 이는 더 나은 특징 표현을 위함이었다. MVSFormer++는 더 나아가 cross-view 정보를 사전학습된 DINOv2에 주입하므로서, 특징을 더욱 개선하였다.
이와 반대로, MonoMVSNet은 pretrained monocular foundation models에서 나온 monocular feature들을 FPN feature들과 attention을 수행한다. 단, refView에 대해서만 수행한다. 그리고 이 feature들을 srcView에게 전달하는데, 이 과정에서 cross-view position encoding이 사용된다. 사용되는 이유는 feature 표현의 robustness를 높이고, overhead를 줄이기 위함이다.
3. Depth Sampling in MVS
depth sampling 전략은 정확한 MVS 방법에서 정확한 cost volume을 만드는 데에 매우 중요하다.
depth 후보들을 depthrange에 대해서 선별해 놓고, srcView의 feature map을 refView의 depthrange에 대응하는 가정평면으로 워핑시킨다.
MVSNet은 dense한 depth sampling을 수행하는데, 이건 비효율적이다. CasMVSNet은 coarse-to-fine depth sampling strategy를 소개한다.
이걸 바탕으로 뒤의 연구들은 메모리 효율성과 추론 속도를 늘릴 수 있게 되었다.
MaGNet은 monocular depth 확률 분포에 기반하여 샘플링을 수행하게 된다.
이 방법들은 모두 후보들을 적게 뽑아서 메모리 효율성과 추론 속도를 늘리려고 한다.
근데 우리는 monocular depth를 depth sampling process에 동적으로 관여하도록 한다. 이는 더 나은 후보를 제공하고, 복원 성능을 높인다.
4. MDE (Monocular Depth Estimation)
MVS 방법들의 발전에도 불구하고, 텍스쳐 없고, 깊이가 불연속적이며, 반사면에서 정확하게 복원하는 과제는 항상 힘들었다.
최근에, monocular depth estimation이 굉장한 진보를 했다.
- MiDaS (zero-shot generalizaiton)
- DPT (fine-grained estimation이 가능한 Transformer)
- DepthAnythingV1 (large number of unlabeled image)
- DepthAnythingV2 (achieved robust depth prediction across complex scenarios)
하지만!! MDE의 치명적인 단점, scale ambiguity (direct use in downstream tasks) (3D 복원에는 못 쓴다)
Methodology
그래서 MDE의 장점과, MVS의 장점을 적절히 뽑아서 잘 활용하는 것이 목표이다.
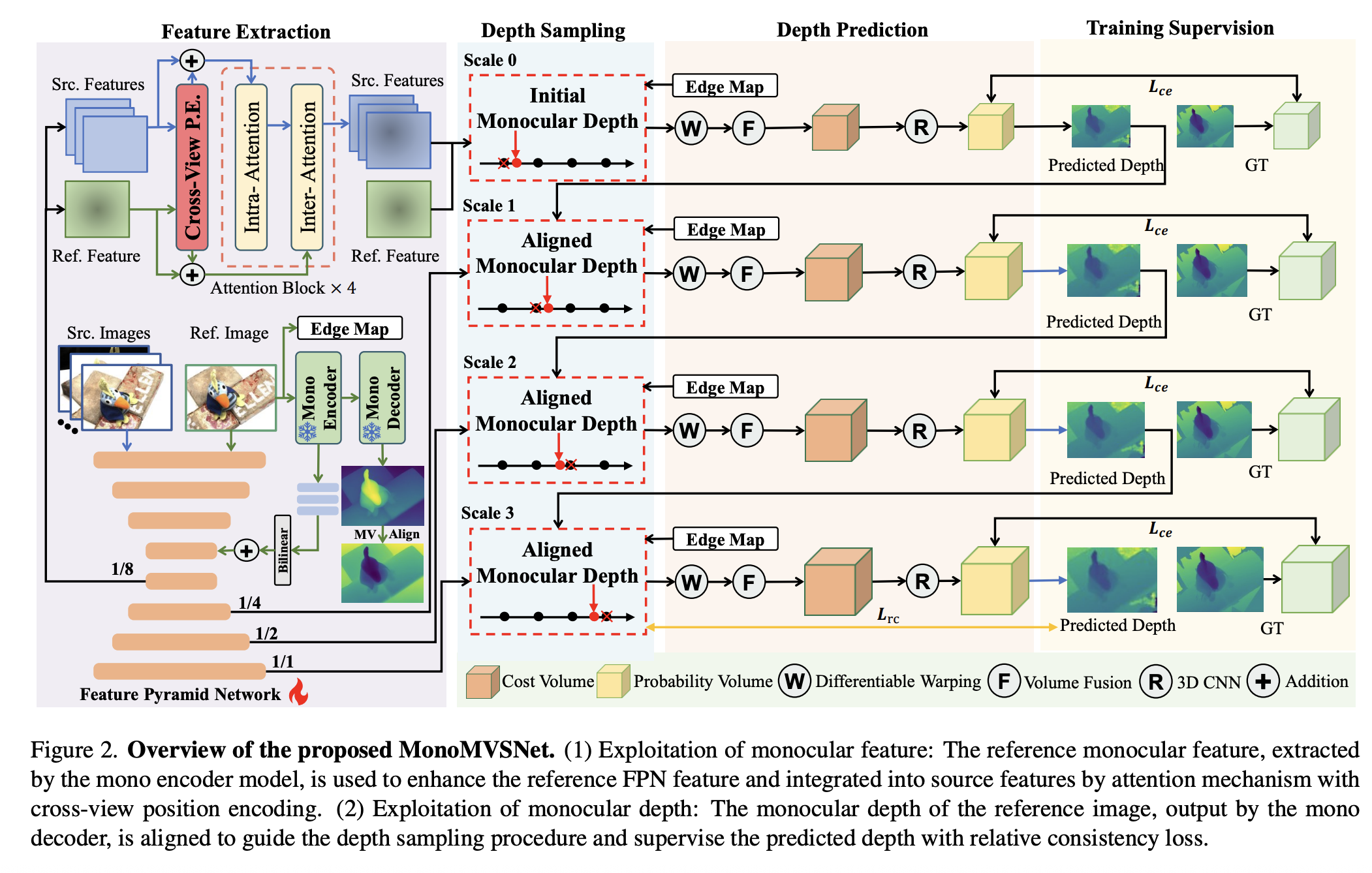
a. 일단 mono encoder의 output이 FPN의 중간에 들어가서 bilinear interpolation 된 후, 1/8에 들어간 것을 볼 수 있다. 해당 정보가 더해진 feature들은 1/8을 제외하고 전부 scale로 타고 들어간다. 얘네는 추후에 depth aligment에 관여하니까, 잠시 뒤에 살펴보자.
먼저 눈으로 따라가야 할 건 1/8 크기의 feature들이 srcView feature와 refView feature로 각각 뽑혀 가는 부분이다. (아마 여기서 MVS의 pair등의 정보가 포함될 것이다.)
여기서 Cross View Positional Encoding이 나오게 된다! 이 정보는 feature들에 더해져서 들어가게 된다.
intra attention 수행(srcView끼리), inter attention 수행(refView끼리)하게 된다.(여기서 attention block은 4개) 결론적으로 정보가 모두 반영된 SrcFeature과 RefFeature가 나오게 된다.
이게 이제 initial monocular depth로 들어가게 되는데, 여기서 coarse-produced 된 depth 후보들을 이용한다. 이는 unreliable position을 제외하는 역할을 수행한다. aligned monocular depth는 edge region 근처에 있는 depth 후보들을 없애는 역할을 수행한다. 그리고 depth를 relative consistency loss를 통해 관리하는 역할 또한 수행한다.
Monocluar Feature for Feature Extraction
N-1 개의 srcView image
1개의 refView image (I_0)
Feature Extraction for Different Images
4-layer의 FPN을 source image에 사용한다.
FPN feature는 다음과 같이 표현될 수 있다.
s는 scale index
C는 channel dimesionality
MonoMVSNet은 오직 refView image에 대해서만 pretrained된 monocular depth estimation model에 넣고, 이것을 bilinear upsampling operation을 통해 1/8에 있는 에 대해서 덧셈을 통해 합치게 된다.
이후 FPN decoder를 통해 나오게 된 feature들은 다음과 같이 표현한다.
Cross-View Position Encoding for Attention
MVS 연구에서 srcView feature들을 발전시키기 위해 intra, inter-view attention을 수행하는 것은 일반적인 방법론이다.
하지만 기존 연구들은 3D 공간 정보의 중요성을 무시하고 단순한 relative or absolute position encoding을 attention 과정에서 사용한다.
이것을 한 단계 끌어올리기 위해서, 우리는 CVPE(Cross-View Position Encoding)을 제안한다. intra, inter attention 상호작용을 강화시켜서, refView의 prior를 srcView feature에 더 효과적이게 적용한다.
의미적으로는, 두 뷰의 각 픽셀이 가리키는 3D 공간에서의 픽셀 정보를 encoding 정보로 사용하여, attention 과정에서 srcView feature들을 더 잘 고를 수 있게 해 준다. (srcView의 이 패치가 refView의 어떤 패치와 관련이 있을까? 이때 NN에게 3d 공간에서의 이들 위치 정보도 같이 주어야 겠다.)
srcView feature들은 depth hypothesis들에 대해 모두 warp되어져 오고, 이 과정에서 n번째 view의 camera intrinsic과 extrinsic 파라미터가 모두 사용된다.
우리는 warped 된 feature들을 다음과 같이 표시한다.
D_0는 depth plane 수 (후보 수)
8로 가로세로가 나눠지는건 FPN의 bottleneck의 크기가 원본의 1/8이었으니까, 당연하다.
는 n번째 srcView의 Feature의 좌표. (0은 scale)
warped 2d coordiante는
는 i번째 depth hypothesis plane의 2d좌표를 의미하는데, 이는 다음과 같이 결정된다.
which means,
(3) 식이 좀 많이 헷갈리긴 하는데, Python 식이라고 생각하면 이해가 편하다.
좌변은 4차원 값이고, 우변은 3차원 값이다. D_0가 빠졌으므로 i가 없다.
refView의 feature 은 n-th srcView로 워프된다. 그냥 hat붙이고 변환의 방향을 바꾼 것 뿐이다.
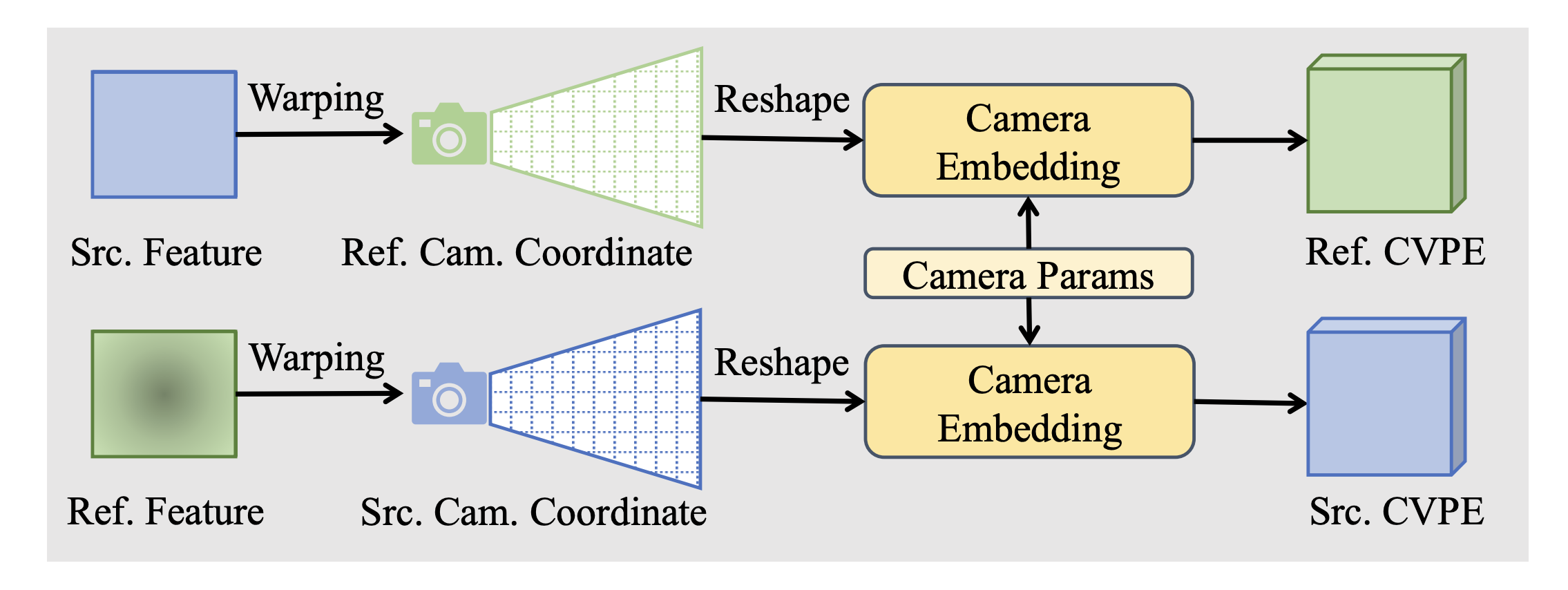
Camera Embedding은 MLP인데, 얘는 image-to-world 좌표계 변환을 수행하는 카메라 파라미터를 인코딩 하는 역할을 한다. (이미지가 ref일 때도 동작하고 src일 때도 동작)
이 프로세스는 카메라 파라미터와 관련된 공간 정보를 특징에 삽입한다. 또, 깊이 차원에 대해서 특징을 압축하게 된다. 이들의 결과로
가 탄생하게 된다. 각 F'은 CVPE를 의미한다.
이들은 으레 positional encoding이 그렇듯이, 각각 이들의 원본 feature들과 더해지게 된다.
그리고 이들은 Intra-Attention과 Inter-Attention으로 들어가게 된다.
최종 output은 enhanced 된 feature 이 되게 된다. (n-th view in the 0th scale)
각 scale과 각 source view에 대해서 enhanced 된 feature들을 다음과 같이 표현한다.
convolution을 타고, bilinear upsampling을 하고
다음 scale의 FPN feature들로 들어가게 된다.
Dynamic Depth Sampling을 위한 단안 깊이
단안 깊이 추정의 scale ambiguity 문제를 해결할 aligment method를 제시하였다.
0번째 scale에서는 미리 주어진 min_depth와 max_depth로 monocular depth가 scale된다. mvs에서 나온 depth가 monodepth를 다음 스테이지(스케일)에 사용할 D_mono를 align 시킨다.
Monocular Depth alignment
monocular depth alignment에서 사용하는 input은 다음과 같다
- 현재 scale의
- 이전 scale에서 추정한 previous scale depth.
hat은 항상 현재 스케일의 해상도에 맞췄다는 표현과 같다.
도 MVS에서의 스케일과 보통 같지 않으니 맞춰 주어야 한다.
이전 scale 에서 뽑은 confidence map을 바탕으로 가장 confidence가 높은 80% 의 pixel들만 사용하게 된다.
와 가 least squares optimization을 통해 a와 b를 구한다.
상위 80% 픽셀에 대해서 데이터 모델을 구하고, monodepth에 어떤 일차 계수와 bias를 통해서 실제 모델로 보낼 것인지 정한다.
Monocular Dynamic Depth Sampling
disparity 말하는 depth의 inverse에 대하여 equation
을 만족하는 R들을 깊이 후보로 삼는다.
가벼운 edge 추정 네트워크를 통해서 edge confidence map을 만든다. 이 edge map에서 confidence가 높은 것들만 thresholding을 통해 남긴다.
그리고 여기서 구해진 엣지 부분의 을 구해서 이와 abs error가 가장 적은 특정 깊이 후보를 찾아 그 후보를 이 값으로 바꾼다.
edge에 대해서는 전 단계(Monocular Depth Alignment)에서 추정한 align depth를 믿고 후보로 사용하는 것이다.
그런데 이게 해당 픽셀들에 대해서만 깊이 후보를 이렇게 사용하는 것이 아니라, 깊이 후보가 edge값들에 대해 변경되게 되면, 같은 이미지에 있는 깊이 후보들도 다 영향을 받아서 바뀌게 된다.
Depth Prediction with Cost Volume
cost volume을 만드는 과정은 다음과 같다. (이전과 같다)
(1) srcView feature을 refView로 warp
(2) 특징 공분산으로 cost volume 생성
(3) cost volume 기반으로 depth 추정
앞에서 PVE할때도 warping 수행했는데, 해당 정보를 캐싱해두는지는 잘 모르겠다.
여기서 가벼운 3D UNet regularization network로 들어가게 되는데, 각 depth 후보에 대해서 softmax를 취해 주는 것이다.
그래서 결과로 나오는 것이 probability volume 이는 winners-take-all strategy를 통해 가장 큰 확률 값을 가진 index의 depth가 predicted depth가 되게 한다.
Training Objective with Relative Consistency
마지막으로, monocular의 대소 관계 정보를 predicted depth에 주입시킬 것이다. 새로운 Relative consistency loss를 적용하여 이를 주입한다. 관계 일관성 손실 함수.
사실상 픽셀들 중 일부를 샘플링 한 뒤, 이들의 기댓값의 차를 loss로 두는 것이다.
monocular depth estimation에서 나온 픽셀에 대한 depth 기댓값과, multi-view 정보를 바탕으로 나온 픽셀의 depth 기댓값의 차이를 픽셀들에 대해서 합한 것이 relative consistency loss이다.
최종 loss는 다음과 같이 정의할 수 있다.
모든 scale에 대한 cross-entropy loss와 relative consistency loss의 가중합이다.
