
"앞으로 강화학습에 다루게 될 포스팅은 Google DeepMind에서 제공하는 RL Cource by David Silver 강의를 듣고 강의자료를 참고하여 개인적으로 리뷰하는 내용입니다. 개인적인 학습 및 리뷰가 주된 목적이므로 강의의 모든 내용을 포함하지 않을 수 있으며 핵심적이거나 제가 이해하기 어려웠던 내용들을 다룰 것임을 포스팅에 앞서 알립니다."
How it started
저는 2023학년 3학년 2학기를 마치고 자대 CAM(Connected&Autonomous Mobility) Lab에서 학부연구생 인턴을 시작하였습니다. 인턴 활동 중에 관심 분야인 자율주행/임베디드 시스템 개발 로드맵과 연구동향에 대해서 찾아보던 중 자율주행(인지, 판단, 제어)의 모든 분야는 물론 자율주행 상용화를 위한 시뮬레이션 등의 관련분야에서 AI-머신러닝, 딥러닝-모델을 활용한 연구가 활발히 진행되고 있음을 알 수 있었습니다. 이를 계기로 Reinforcement Learning의 기초에 대해서 학습하고자 오픈소스에 대해 찾아보았고 강화학습의 기초를 다질 수 있는 Google DeepMind의 David Silver의 강의를 듣기 시작했습니다.
Machine Learning
머신러닝은 행동심리학에서 Trial and Error를 통한 "강화,Reinforcement" 개념을 모티브로 연구가 시작된 분야입니다. 컴퓨터 게임과 인공지능 분야의 개척자인 아서 사무엘은 머신러닝을 "기계가 일일이 코드로 명시하지 않은 동작을 데이터로부터 학습하여 실행할 수 있도록 하는 알고리즘을 개발하는 연구 분야"라고 정의하였습니다.
Branches of Machine Learning
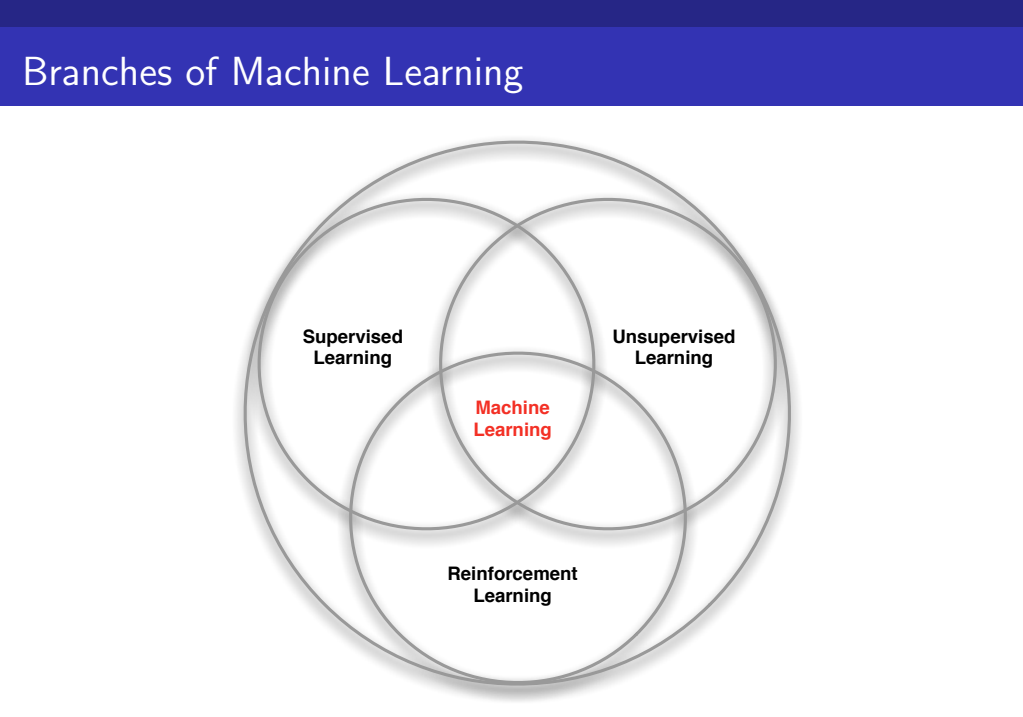
머신러닝은 크게 3가지 범주-Supervised Learning, Unsupervised Learning, Reinforcement Learning-로 나뉘어 집니다.
1. Supervised Learning
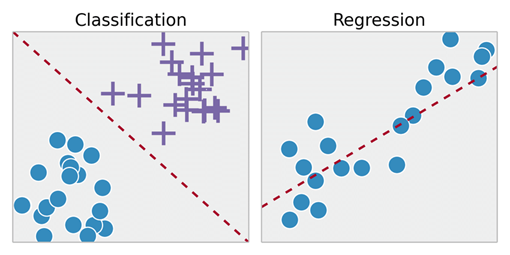
Supervised Learning은 머신러닝에서 desired output값. 즉, 정답이 정해져 있는 학습방법입니다.
학습을 통해 정해진 desired output값이 도출되기를 기대하는 학습방법으로 대표적인 예시로는 확률통계론 개념인 분류(Classification), 회귀(Regression) 등이 있습니다.
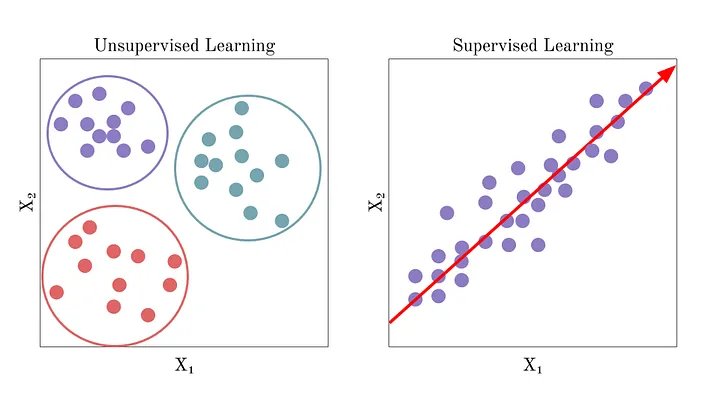
2. Unsupervised Learning
Unsupervised Learning은 머신러닝에서 desired output값이 정해져 있지 않고 주어진 데이터로만 학습하는 방법입니다. Supervised Learning과 비교하면 레이블이 정해져 있지 않기 때문에 보다 복잡한 데이터를 처리할 수 있다는 장점이 있습니다.
대표적인 예로는 군집화(Clustering)가 있습니다.
3. Reinforcement Learning
Reinforcement Learning(강화학습)은 Supervised Learning, Unsupervised Learning과는 구분되는 머신러닝의 한 종류로, Trial and Error를 통한 보상(Reward)을 통하여 학습합니다. 강화학습에서는 학습자 역할을 하는 Agent가 자신이 하는 행동(Action)에 대하여 나타나는 보상(Reward)을 최대화하기 위한 방향으로 학습합니다.
강화학습이 다른 머신러닝 방법들과 다른 특징으론 다음과 같이 4가지가 있습니다.

- There is no supervisor, only a reward signal.
강화학습에는 desired output이 존재하지 않는데, 이를 지도자 superviosr가 존재하지 않는다고 표현합니다. supervisor가 없으므로 직접적인 정답에 대한 오차를 계산하는 방식으로 학습하지 않고, 오직 보상을 최대화하기 위한 방향으로 학습합니다. - Feedback is delayed, not instantaneous.
강화학습의 초기에는 reward가 어느 상황에서 높아지는가에 대한 데이터가 없기 때문에 적절한 피드백은 즉각적이지 않고 지연된다는 특징이 있습니다. 시스템의 복잡성에 따라 짧게는 하루에서 이틀, 길게는 몇 달 이상의 시간이 걸릴 수 있습니다. - Agent's actions affect the subsequent data it receives.
Agent의 행동이 차후 받은 데이터에 영향을 미칩니다.
EX) 강화학습이 적용된 대표적인 예로는 Fly stunt manoeuvres in a helicopter, Manage an investment portfolio, Make a humanoid robot walk 등이 있습니다.
Terminologies of Reinforcement Learning
다음으로 차후 강화학습의 학습을 위해 필요한 용어와 개념을 정리하겠습니다. 용어 정리는 앞으로 강화학습 내용 이해를 위해 매우 중요하므로 정확하게 짚고 넘어갈 필요가 있습니다.
Rewards
Reward(Rt)는 scalar feedback signal로 강화학습을 하는 주체인 Agent가 step t동안 얼마나 잘 행동했는가를 나타냅니다. Agent는 reward를 최대화하기 위한 방향으로 학습합니다.
강화학습은 현실의 모든 상황을 RL모델로 데이터화하기 위한 가설에 기반하여 이루어집니다.
Reward Hypothesis
All goals can be described by the maximisation of expected
cumulative reward.
Agent
에이전트 Agent란 강화학습을 하는 주체로, 강화학습을 통해 학습하는 컴퓨터가 Agent입니다.
Sequential Decision Making
강화학습은 supervisor가 존재하지 않습니다. 해결할 문제에 대해 Agent가 이해할 수 없다면(Reward Hypothesis를 만족하지 않는다면) 강화학습은 무의미한 결과를 낳을 수 있습니다.
따라서 강화학습은 해결할 문제에 대해 쉽게 정의할 수 있는 Sequential Decision Making에 강점이 있습니다. Sequential Decision Making의 목적은 "미래의 cumulative reward를 최대화하는 방향으로 action을 선택하는 것"입니다. 목적을 달성하기 위해서는 더 나은 total reward를 얻기 위하여 즉각적인 reward는 희생하는 것이 나을 수도 있습니다.
Sequential Decision Making 문제 정의를 위한 구성요소는 다음과 같습니다.
Agent and Environment
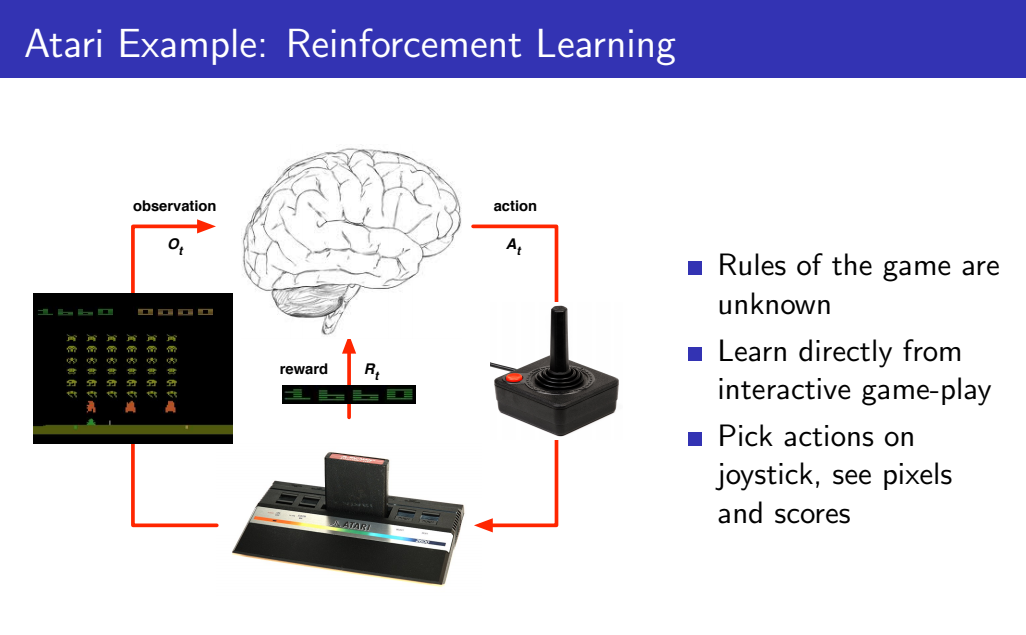
아래 사진은 강화학습 Reinforcement Learning에서 Agent와 Environment의 상호작용을 표현한 다이어그램입니다.
def)
- observation : Agent의 action을 선택하기 위해 필요한 정보(State의 일부분)
- action : Agent가 observatio과 reward를 바탕으로 하는 행동
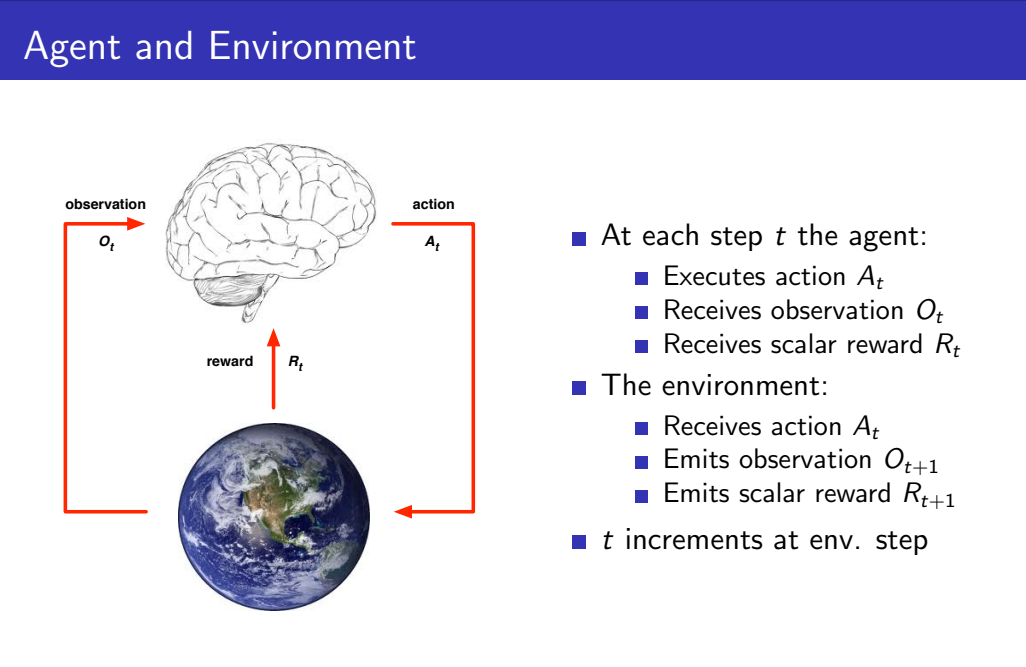
다이어그램에서 뇌가 강화학습을 통해 학습하는 "Agent"이고 지구는 "Environment"를 나타냅니다. step t시간에 Agent는 t시간에 대한 observation과 reward를 받고, 얻은 데이터를 바탕으로 action을 선택하여 Environment에 전송합니다. Environment에서는 t시간에 대한 action은 받고, 받은 action을 바탕으로 (t+1)시간에 대한 observation과 reward를 Agent에게 전송합니다.
History
History란 강화학습 과정에서 보내고 받는 정보인 observations, actions, rewards의 기록,Sequence을 나타냅니다.
State
상태, State란 Agent 혹은 Environment가 다음 행동-action, observation, reward-을 결정하기 위한 "모든" 정보입니다. State는 Agent관점에서, Environment관점에서 표현한 정보를 포함하는 Agent State와 Environment State로 나뉘어 집니다. step t에 대한 Agent State는 수식으로 다음과 같이 표현될 수 있습니다.
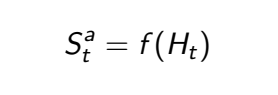
Information State/Markov State
 Information State(또는 Markov State)는 history로부터 유용한 모든 정보를 포함하고 있습니다. 이는 위와 같이 조건부확률로 나타내어질 수 있습니다.
Information State(또는 Markov State)는 history로부터 유용한 모든 정보를 포함하고 있습니다. 이는 위와 같이 조건부확률로 나타내어질 수 있습니다.
위 식처럼 step t 이전 시간에 대한 정보는 받아들여진 이후로 버려지게 되므로, Markov State는 바로 직전의 step t에 관한 정보를 포함합니다.
즉, 미래의 state는 과거의 state에 대하여 independent하며 현재 state(미래에 대한 직전의 state)로만 결정됩니다.
Markov Decision Process(MDP)
MDP란 Sequential Decision Making 문제를 정의할 때 사용하는 대표적인 방법입니다. MDP는 문제상황을 Reward Hypothesis를 만족하도록 수학적으로 정의하여 강화학습할 수 있도록 도와줍니다. MDP는 다음과 같은 특징이 있습니다.
Full Observability
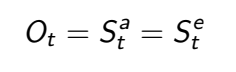 MDP에서는 각각 Agent관점, Environment관점의 state가 동일합니다. 즉, Agent는 Environment state를 직접적으로 관찰할 수 있습니다.
MDP에서는 각각 Agent관점, Environment관점의 state가 동일합니다. 즉, Agent는 Environment state를 직접적으로 관찰할 수 있습니다.
** 이와 반대되는 개념은 Partial observibility로 Agent는 Environment state를 직접적으로 관찰할 수 없습니다. Partial observibility의 예시는 다음과 같습니다.
EX) 카메라를 장착한 로봇이 절대적인 위치 정보를 얻을 수 없다.

Major Components of an RL Agent
Sequential Decision Making 문제해결을 위한 강화학습에서 Agent의 3가지 주요 구성요소는 다음과 같습니다.
- Policy
Policy에 대해 강의에서는 agent's behavior function이라 표현하고 있습니다. 즉, 문제상황에 대하여 Agent가 어떤 action을 선택해야 하는가에 관해 정해놓은 것입니다.
강화학습의 궁극적인 목적은 문제상황에 대하여 Reward를 최대화 하기 위한 "Optimal policy"를 얻는 것입니다.
- Value Function
Value Function이란 David Silver 교수님의 말을 빌리자면 prediction of expected future reward 라고 할 수 있습니다. Value Function은 policy를 평가하고 reward가 최대가 되는 Optimal policy를 찾기 위해 활용됩니다.
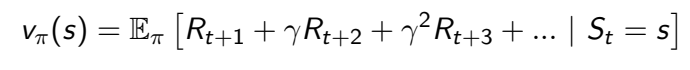
- Model
Model이란 how the agent thinks environment works 또는 Agent's view of environment라고 할 수 있습니다. 따라서 Model이라는 개념은 실제상황과 다르게 완전하지 않을 수 있습니다.
Policy와 Value Function, Model 설명을 위하여 아주 간단한 미로 게임을 예시로 들어봅시다. 미로를 최소한의 시간으로 탈출하기위하여 reward는 -1로 설정하였고, Agent는 동서남북 방향으로 움직일 수 있으며, Agent가 미로에서 존재하는 위치가 유일한 State에 해당합니다.
먼저 미로에 대한 Policy는 각 location에 대한 action으로 동서남북 방향의 화살표가 Policy를 나타냅니다. 함수 policy는 s(state)를 매개변수로 하는 함수로 파이로 아래와 같이 표현됩니다.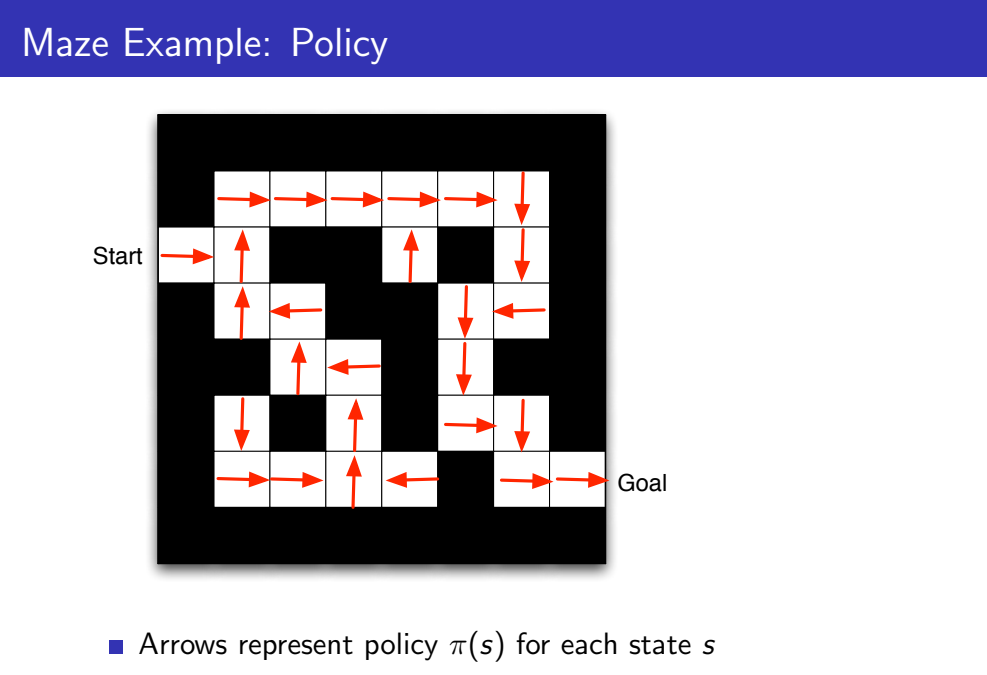
다음으로 Value Function은 설정한 reward에 대해 다음과 같이 계산될 수 있습니다. Agent는 Value값이 최대가 되는 방향으로 policy를 평가하고 적절한 action을 선택해야 합니다.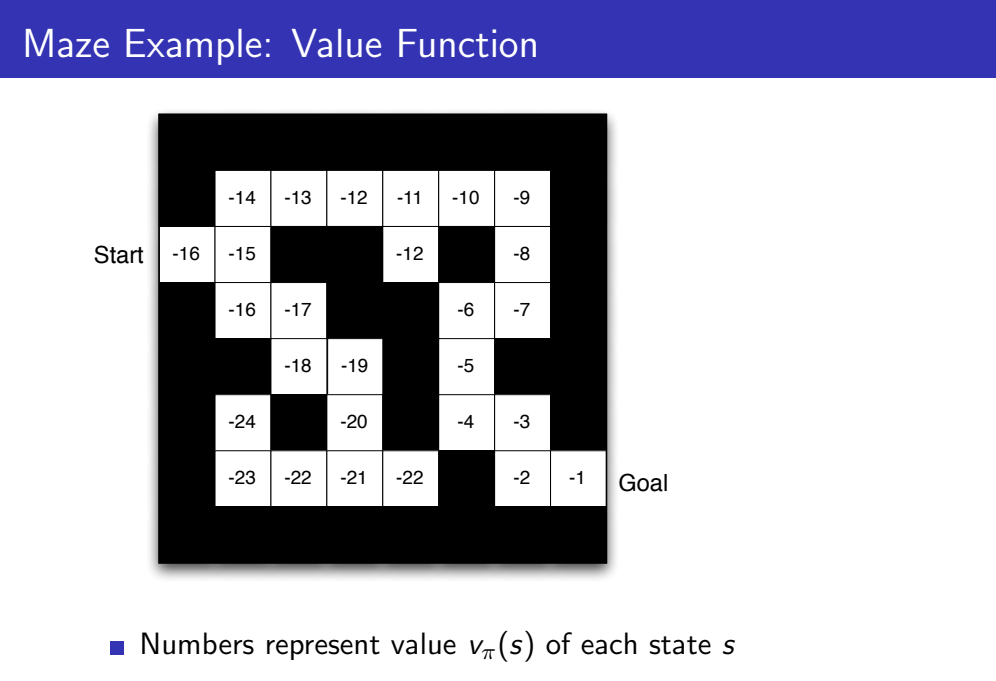
마지막으로 미로게임에 대한 Model은 다음과 같습니다. Agent는 Value Function을 통해 Policy를 평가하고 reward가 최대가 되는 방향으로 action을 선택하므로 기존에 주어진 문제상황과 다르게 Model은 완전하지 않을 수 있습니다.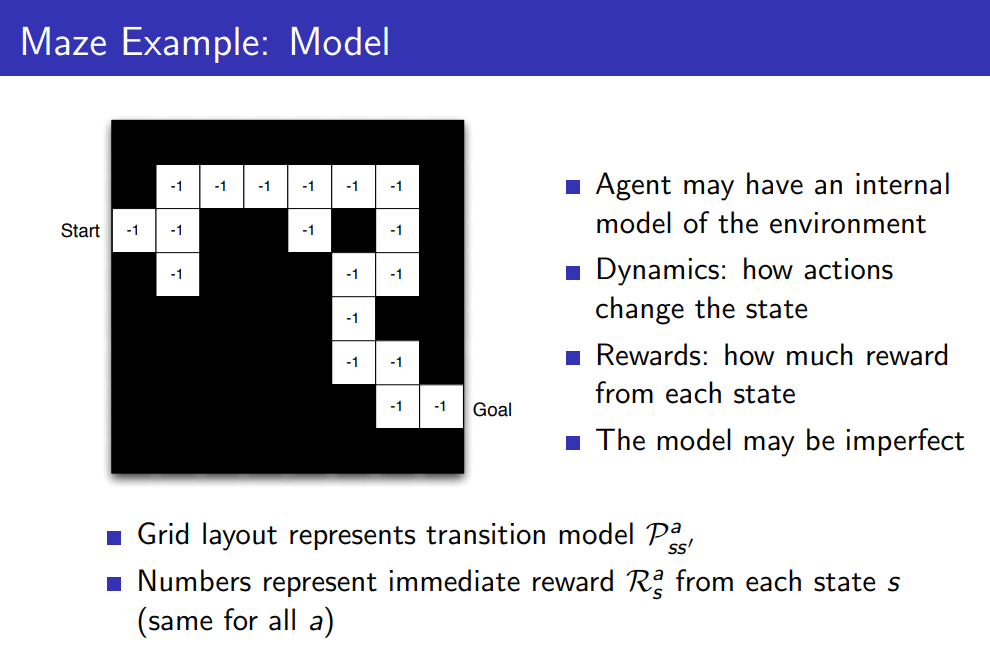
Problems within RL
강화학습을 활용하여 Sequential Decision Making 문제해결에는 2가지 유형의 문제 - Reinforcement Learning, Planning - 가 존재합니다.
- Reinforcement Learning
먼저 우리가 흔히 말하는 강화학습은 첫번째 유형인 Reinforcement Learning에 해당합니다. RL에서는 MDP의 초기 Environment를 알지 못합니다. 따라서 Agent는 Environment와 상호작용하면서 reward를 최대화하는 policy를 결정하며 개선해나가야 합니다.
EX) Atari 게임을 예시로 들면 다음과 같습니다. 강화학습 초기 Agent는 게임에 대한 규칙을 하나도 알지 못합니다. 따라서 게임을 무작위하게 플레이하면서 action에 대한 reward값을 받으며 직접적으로 상호작용합니다.
- Planning
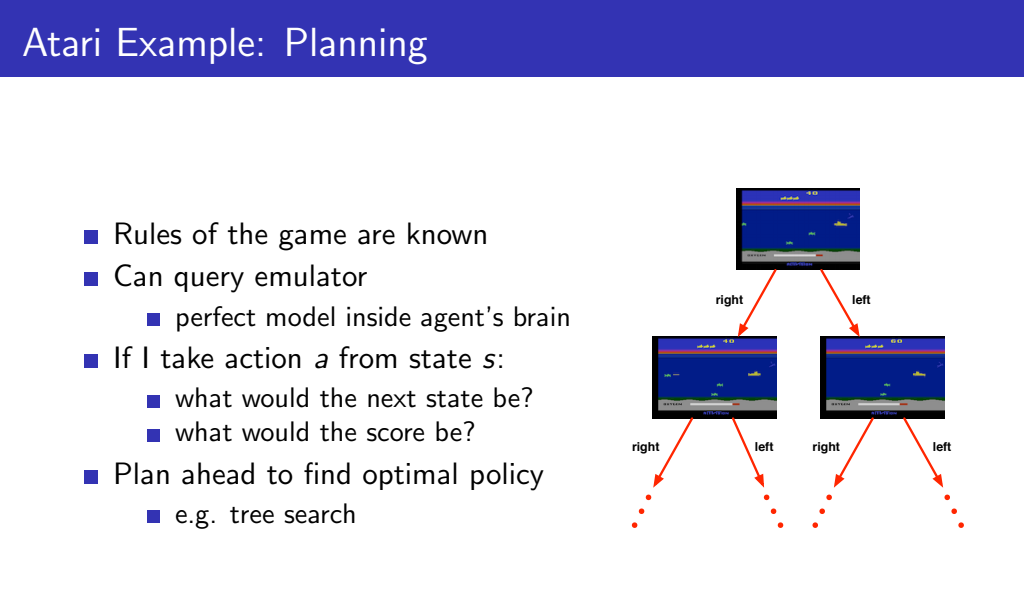
두번째 유형인 Planning은 학습 초기에 Environment에 대한 모델을 알고 있는 학습상황입니다. Agent는 초기 Environment에 기반하여 상호작용하며 계산을 수행합니다.
EX) Atari 게임을 예시로 들면 다음과 같습니다. Reinforcement Learning에서는 조이스틱의 작동에 따라 player가 어떻게 움직이는지도 몰랐다면, Planning에서는 게임의 규칙과 작동 방식에 대해 강화학습의 초기 학습상황부터 알고 있습니다. 아래 그림과 같이 이러한 규칙은 Binary Search Tree와 같이 표현될 수 있으며, 모든 상황을 탐색하여 optimal policy를 찾아낼 수 있습니다.
* Reference
https://ko.wikipedia.org/wiki/%EA%B8%B0%EA%B3%84_%ED%95%99%EC%8A%B5
https://www.researchgate.net/figure/Classification-vs-Regression_fig9_326175998
Supervised/Unsupervised Image : https://towardsdatascience.com/a-brief-introduction-to-unsupervised-learning-20db46445283
Robot with camera : https://wccftech.com/riley-robot-camera/
