메모리의 속도 & 크기: trade-off 존재
- 큰 메모리(예: 하드디스크)는 저렴하지만 매우 느림
- 빠른 메모리(예: SRAM)는 비싸고 용량이 작음
가장 저렴한 메모리의 크기를 가지면서, 가장 빠른 메모리의 속도를 얻는 것
Principle of Locality
프로그램은 어떤 순간에도 전체 주소 공간 중 아주 일부분만 반복적으로 접근함
Temporal Locality
최근에 접근한 데이터는 곧 다시 접근될 가능성이 높다
- 반복문 안에서 사용하는 명령어
- 루프 변수(Induction variable)
Spatial Locality
어떤 데이터에 접근했다면, 그 근처의 데이터도 곧 접근될 가능성이 높다
- 명령어는 보통 순차적으로 실행됨
- 배열 요소 접근 시 연속된 주소 사용
Memory Hierarchy Levels
- 모든 데이터를 디스크(lowest level)에 저장한다
- 최근에 접근한(또는 그 근처의) 데이터를 디스크에서 DRAM(메인 메모리)으로 복사한다
- 더 자주 접근한(또는 그 근처의) 데이터를 DRAM에서 더 작은 SRAM(캐시 메모리)으로 복사한다
디스크 → DRAM → 캐시 → CPU
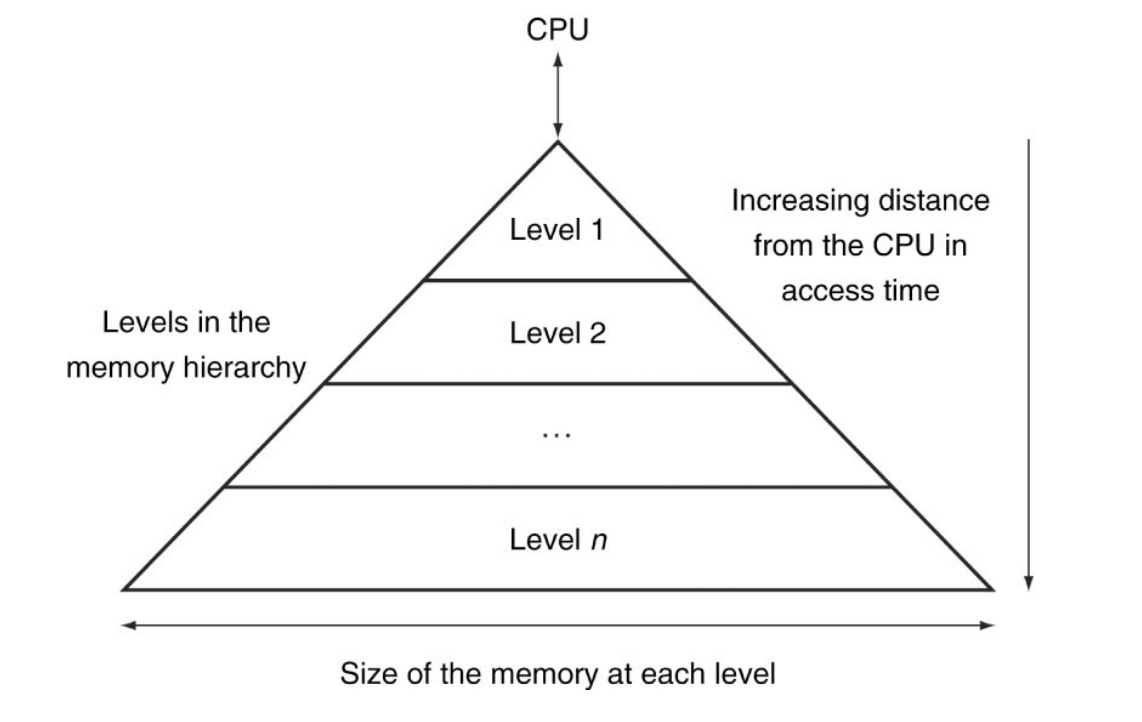
- Data is copied between only two adjacent levels at a time
- Lowest level must have all the data
Block
- Unit of copying: 메모리 계층 사이에서 데이터를 옮길 때 사용하는 단위
- 여러 개의 워드(word)를 포함할 수 있음
Hierarchical Access
✔ Hit
CPU가 원하는 데이터가 상위 레벨(예: 캐시)에 이미 있으면
→ 접근 성공(빠르게 동작)
✔ Miss
상위 레벨에 데이터가 없으면
→ 하위 레벨(예: DRAM)에서 블록을 통째로 복사해 가져옴
→ 그 후 CPU는 상위 레벨에서 데이터를 받게 됨
Memory Technology
| 구분 | 접근 시간 | 가격(GB당) | 특징 | 주요 용도 |
|---|---|---|---|---|
| SRAM | 0.5ns ~ 2.5ns (가장 빠름) | $2000 ~ $5000 (매우 비쌈) | 매우 빠르지만 용량 작고 가격이 비쌈 | CPU 캐시(L1/L2/L3) |
| DRAM | 50ns ~ 70ns | $20 ~ $75 | SRAM보다 20~100배 느리지만 저렴하고 용량 큼 | 메인 메모리(RAM) |
| Magnetic Disk (HDD) | 5ms ~ 20ms (매우 느림) | $0.2 ~ $2 (가장 저렴) | 속도 가장 느리지만 용량 가장 큼 | 대용량 저장장치(파일 저장) |
SRAM Technology
IC 내부에 6~8개의 트랜지스터로 데이터를 저장
- 빠르지만 고가
- Fixed access time - 모든 데이터에 대한 접근 시간이 일정
- refresh가 필요 없음
- 대부분 캐시에 사용되고, CPU 칩 내부에 통합됨
DRAM Technology
DRAM은 전하(charge)를 축전기(capacitor)에 저장하여 데이터를 유지하는 메모리
- 단일 트랜지스터 + 축전기로 한 비트를 저장
- 축전기의 전하는 시간이 지나면 자연적으로 새어 나감(leak)
- 데이터를 유지하려면 주기적으로 새로 읽고 다시 쓰는 (read & write-back를 refresh) 과정이 필요
Synchronous DRAM (SDRAM)
클럭을 사용하는 DRAM, 향상된 대역폭(bandwidth)
rising edge에서만 데이터 전송
Double Data Rate (DDR) DRAM
rising and falling edges 모두에서 데이터 전송
| 기술 | 의미 | 성능 효과 |
|---|---|---|
| SDRAM | CPU와 같은 클럭 박자에 맞춰 동작하는 DRAM | 더 효율적인 동작, 대역폭 증가 |
| DDR DRAM | 클럭의 상승/하강 에지 모두에서 데이터 전송 | 전송 속도 2배 증가 |
Flash Storage
비휘발성 반도체 저장장치 - Non-volatile Semiconductor Storage (a type of EEPROM)
- 디스크보다 100배 ~ 1000배 빠름
- 더 작고, 전력 소모가 적고, 내구성이 높음
- 하지만 GB당 가격은 더 비쌈 (디스크와 DRAM 사이)
- EEPROM(Electrically Erasable Programmable Read-Only Memory)
- 전원이 꺼져도 데이터를 유지함
종류
-
NOR Flash : NOR 게이트처럼 생긴 셀 구조
랜덤 읽기/쓰기 가능
임베디드 시스템의 명령어 메모리로 사용 -
NAND Flash : NAND 게이트처럼 생긴 셀 구조
Denser bits/area ratio, 하지만 블록 단위 접근
GB당 가격이 더 저렴
USB, 저장 매체 등에 사용
Flash 비트는 수천 번 접근하면 마모됨
direct RAM으로 부적합
Wear leveling : 덜 사용된 블록으로 데이터를 재배치하여 수명 연장
Disk Storage
Nonvolatile(비휘발성), Rotating Magnetic Storage
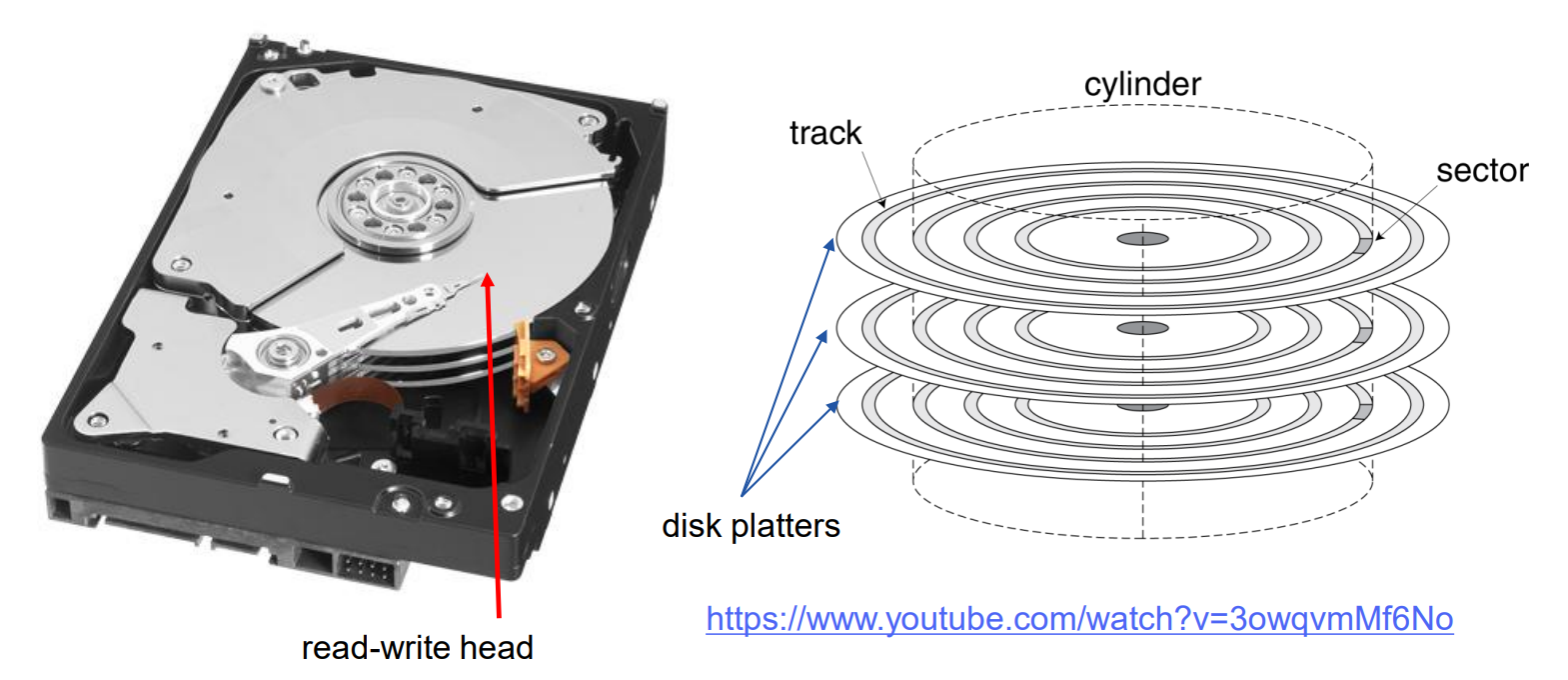
Each Sector records
- 섹터 ID
- 데이터 (512바이트, 4096바이트 제안됨)
- 오류 정정 코드(ECC)
- 동기화 필드와 간격
Access to Sector involves
- Seek: 헤드를 이동시키는 과정
- 회전 지연(Rotational latency) (평균 = 0.5회전)
- 데이터 전송
- 컨트롤러 오버헤드

섹터 크기: 512B
회전 속도: 15,000 rpm
평균 탐색 시간(seek time): 4 ms
전송 속도(transfer rate): 100 MB/s
컨트롤러 오버헤드: 0.2 ms
디스크는 idle 상태(다른 지연 없음)
총 읽기 시간 = 탐색 시간 + 회전 지연 + 전송 시간 + 컨트롤러 지연
Average Read Time = 4ms seek time
½ / (15,000/60) = 2ms rotational latency
512 / 100MB/s = 0.005ms transfer time
0.2ms controller delay
= 6.2ms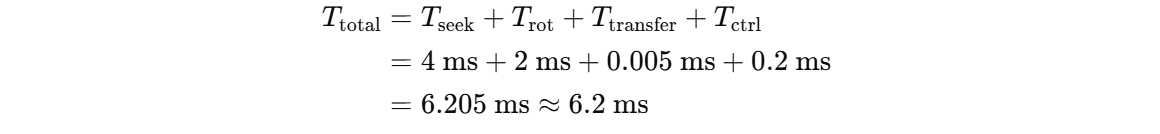
Disk Performance Issues
-
제조업체는 평균 탐색 시간을 제시함
모든 가능한 탐색(seek)을 기반으로 함
지역성과 OS 스케줄링으로 인해 실제 평균 탐색 시간은 더 작아짐 -
스마트 디스크 컨트롤러는 디스크의 물리적 섹터를 할당함
호스트에게 논리적 섹터 인터페이스를 제공
SCSI, ATA, SATA -
디스크 드라이브에는 캐시가 포함됨
접근을 예상하여 섹터를 미리 가져옴(prefetch)
탐색 및 회전 지연을 피함
Cache Memory: Basics
- 제조업체는 평균 탐색 시간을 제시함
모든 가능한 탐색을 기반으로 함
지역성과 OS 스케줄링 덕분에 실제 평균 탐색 시간은 더 작아짐
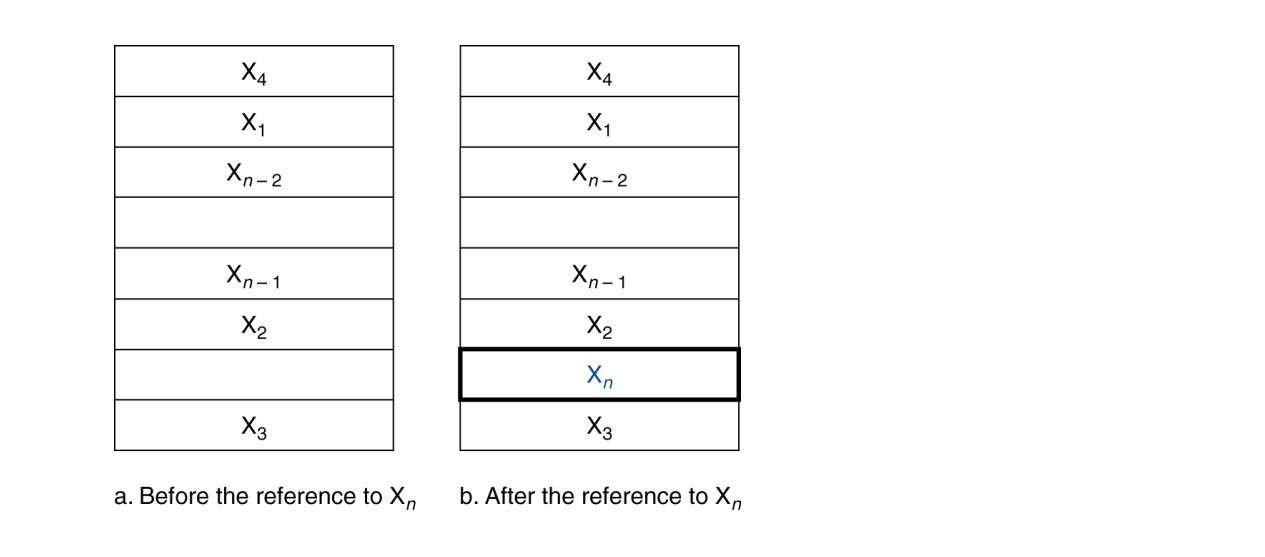
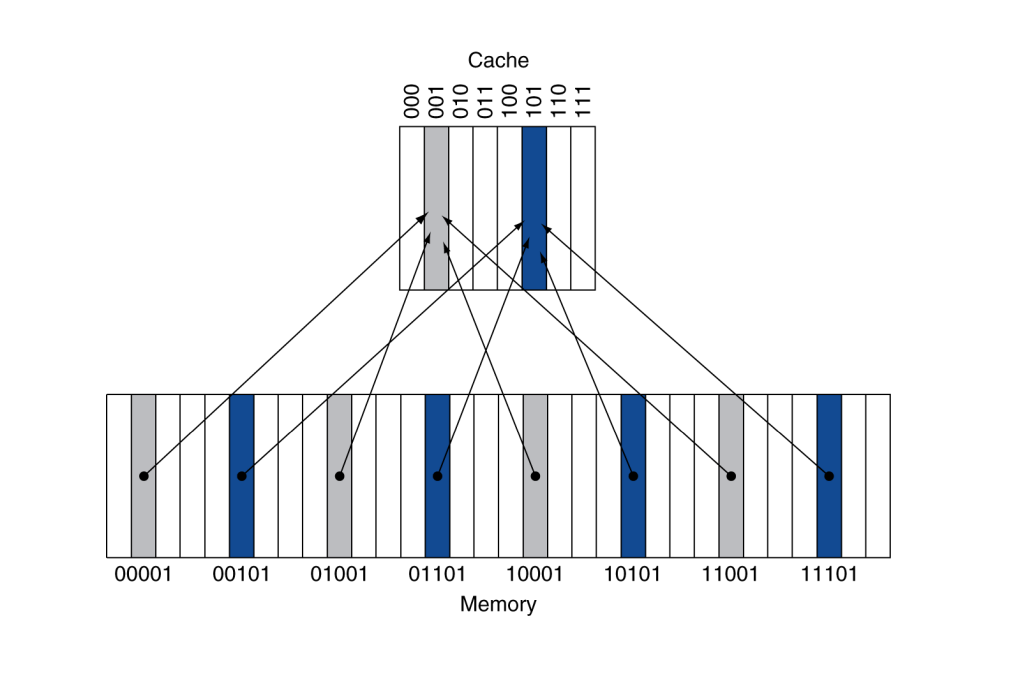
Cache Example
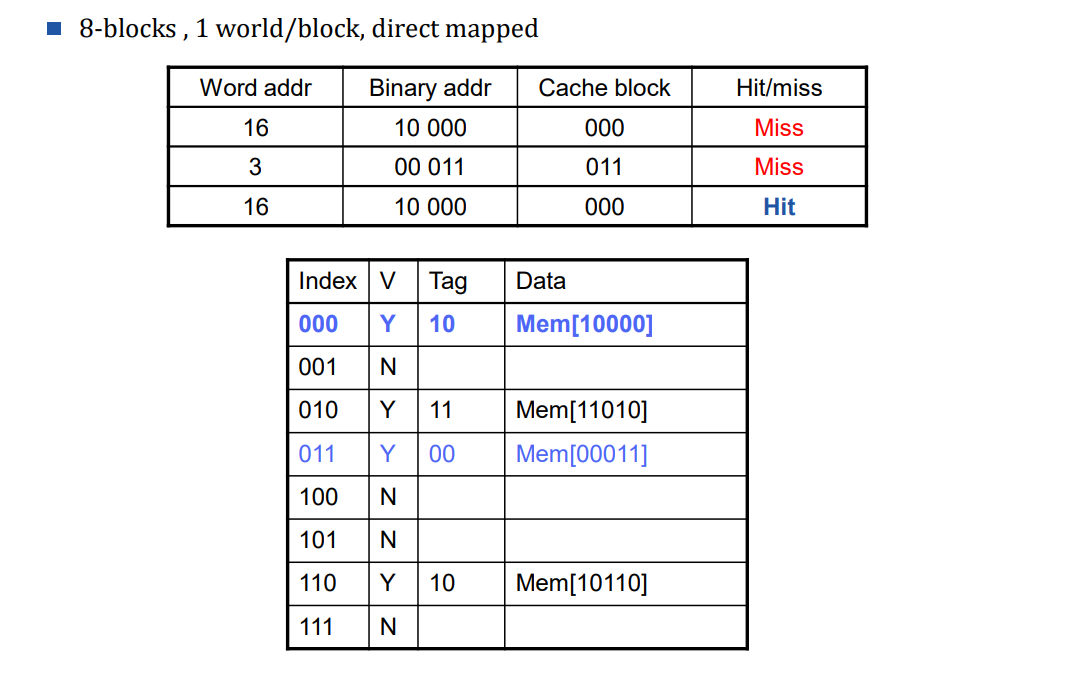
8-blocks , 1 world/block, direct mapped
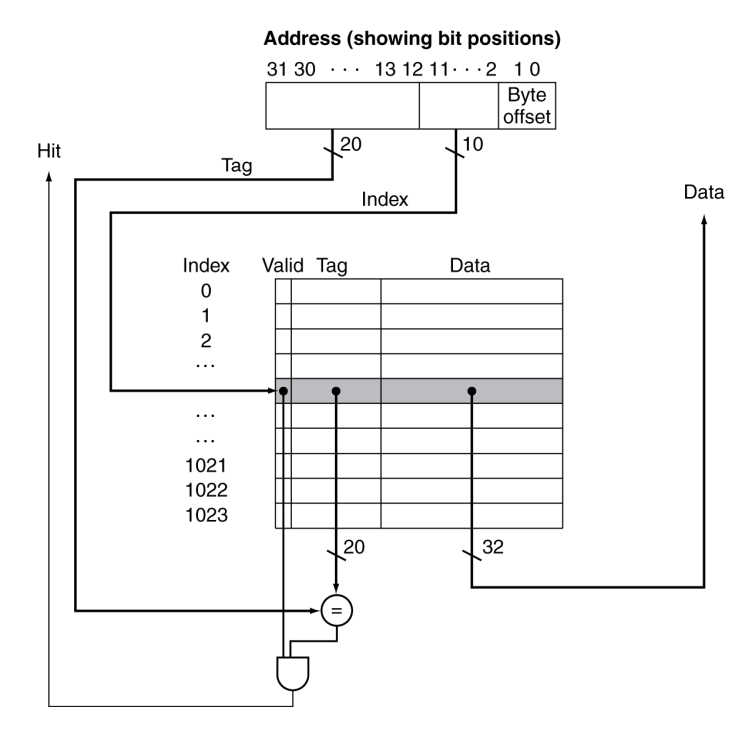
Address Subdivision
주소를 Tag / Index / Offset으로 나누지 않으면 캐시가 데이터를 빨리 찾을 수 없으므로, 메모리 계층 구조를 효율적으로 사용하려면 주소 분할이 필수
| 용어 | 의미(설명) |
|---|---|
| Tag | 주소의 가장 상위 비트 - 캐시에 저장된 블록이 원하는 메모리 블록과 일치하는지 확인하는 데 사용됨 |
| Index | 주소의 중간 비트 - 이 값이 캐시의 어느 블록(슬롯) 에 해당 주소가 저장되는지를 결정 (예에서는 캐시 크기가 2¹⁰이므로 인덱스 길이는 10비트) |
| Block Offset | 주소의 가장 하위 비트 - 하나의 캐시 블록 안에서 정확히 몇 번째 바이트인지를 지정 |
즉...
| 부분 | 역할 |
|---|---|
| Tag | 내가 찾는 데이터가 맞는지 확인하는 이름표 |
| Index | 캐시의 슬롯에 들어있는지 알려줌 |
| Offset | 그 슬롯 안의 정확한 위치 |
Block Size 선택 시 고려해야 할 점
1. 블록이 커지면 Miss rate은 줄어들음
이유: Spatial Locality(공간 지역성)
→ 프로그램이 어떤 위치를 읽으면 그 근처 데이터도 곧 사용할 가능성이 높다.
2. 하지만 fixed-size cache 일 때 문제 발생
- 블록이 크면, 블록 개수는 줄어든다
예: 캐시가 32B이고,
블록 크기 4B → 8개 블록
블록 크기 16B → 2개 블록- Conflict miss 증가 - 큰 블록은 더 자주 서로를 덮어 씀
- Cache Pollution - 큰 블록을 가져오면 필요 없는 데이터까지 너무 많이 들어옴
- Cache Pollution - 가져온 블록 안의 데이터 대부분을 사용하지 않으면 → 매번 큰 블록을 다시 읽어오게 되어 낭비가 커짐
3. 큰 블록은 Miss penalty(미스 패널티)를 증가 시킴
미스가 발생하면 블록 전체를 메모리에서 캐시로 읽어와야 함 → 블록이 크면 전송 시간 길어짐 → miss penalty 증가
- Early restart: 필요한 word만 먼저 CPU에 전달
- Critical-word-first: 진짜 필요한 단어를 가장 먼저 가져오게 요청
| 블록 크기 증가 시 장점 | 블록 크기 증가 시 단점 |
|---|---|
| Miss rate 감소 (공간 지역성 활용) | 캐시에 저장 가능한 블록 개수 감소 |
| Conflict miss 증가 | |
| Cache pollution 증가 | |
| Miss penalty(미스 비용) 증가 |
Cache Read Misses
1. Cache hit
CPU는 그냥 캐시에서 바로 읽고 정상적으로 진행됨
2. Cache miss
① Fetch block from next level of hierarchy
메인 메모리에게 “이 주소 읽어와!”라고 요청
메모리가 가져올 때까지 기다림
가져온 데이터를 캐시에 저장 (data + tag + valid bit 업데이트)
② Restart cache access
Instruction cache miss → PC를 원래 값으로 되돌리고 명령어 다시 fetch
Data cache miss → 필요한 데이터 읽기 완료 후 CPU에게 전달
Cache Write Misses
Cache write hit
캐시에 해당 데이터가 already 존재하는 경우
그냥 캐시에 있는 값만 업데이트하면 됨!
Cache write miss
캐시에 데이터가 없으므로 고민해야 함
CPU가 캐시에만 값을 써버리면
→ 메모리에 있는 값과 캐시 값이 서로 달라져 버림
→ 데이터 불일치(Inconsistency) 문제 발생
쓰기 정책 필요: Write-through vs. Write-back
Write-Through
캐시와 메모리를 동시에 업데이트
캐시에 먼저 쓰고, 바로 메인 메모리에도 반영
구조가 단순하고 메모리와 항상 일관성 유지됨
단점: 느리다
ex) CPI = 1
명령어 중 10%가 store
메모리 쓰기 = 100 cycles
➡ 실제 CPI = 1 + 0.1 × 100 = 11 → 엄청 느림!
해결책: Write Buffer
쓰기 요청을 버퍼에 잠시 저장
CPU는 기다리지 않고 다음 명령 실행
버퍼가 꽉 찰 때만 stall 발생
Write-Back
캐시에만 먼저 쓰고, 메모리에는 나중에 반영
캐시 블록이 교체될 때만 메모리에 쓰기
이때 수정된 블록: Dirty block
과정
캐시에 write hit 발생 → 캐시 블록만 수정
해당 블록이 캐시에서 쫓겨날 때(eviction)
→ Dirty bit 확인
→ Dirty 라면 메모리에 블록 전체를 다시 저장(write-back)
장점
메모리에 쓰는 횟수가 매우 줄어듦 → 성능 빠름
많은 CPU에서 사용하는 방식
단점
구조가 복잡함
miss를 먼저 감지해야 캐시에 덮어쓰기 가능 → 추가 cycle 필요
메모리와 캐시 내용이 일시적으로 다를 수 있음 → coherence 관리가 어려워짐
| 방식 | 캐시에 쓰기 | 메모리에 쓰기 | 장점 | 단점 |
|---|---|---|---|---|
| Write-Through | 즉시 | 즉시 | 단순, 메모리와 항상 동일 | 매우 느림 → write buffer 필요 |
| Write-Back | 즉시 | 교체될 때 | 빠름, 메모리 쓰기 감소 | 복잡함, dirty 관리 필요 |
Write Allocation
write miss: CPU가 어떤 주소에 Write(저장) 하려고 하는데, 그 블록이 캐시에 없는 상황
선택지
1. Allocate on miss: 미스가 나면 블록을 가져온다
2. Write-Around: 블록을 가져오지 않는다
Write-back에서는 보통 블록을 가져온다
Measuring Cache Performance
CPU Time = (CPU Execution Time) + (Memory-stall time)
CPU Execution Time = 프로그램 실행 사이클 (캐시 히트 시간 포함)
Memory Stall Cycles = 주로 캐시 미스에서 발생

Cache Performance Example


Average Access Time
Hit time이 왜 중요한가
Hit time = 캐시에서 데이터가 있을 때(access hit) 걸리는 시간
CPU가 명령어를 계속 실행할 때 매번 캐시를 접근하니까 hit time이 작아야 전체 속도가 빨라짐
Average Memory Access Time (AMAT)
AMAT = Hit time + Miss rate × Miss penalty
AMAT = 1 + 0.05×20 = 2ns