[번역] Fundamentals of Data Visualization - 6 Visualizing amounts
Fundamentals of Data Visualization

6 Visualizing amounts
많은 상황에서 우리는 특정 숫자 집합의 크기에 관심을 가집니다. 예를 들어, 다양한 자동차 브랜드의 총 판매량을 시각화하거나, 다양한 도시의 총 인구 수를 시각화하거나, 또는 다양한 스포츠에 참여하는 올림픽 선수들의 나이를 시각화할 수 있습니다. 이러한 경우를 "visualizing amounts"라고 부르며, 이러한 시각화에서 주요 초점은 정량적 값의 크기입니다. 이 시나리오에서 표준 시각화 도구는 막대 그래프이며, 여기에는 단순 막대뿐만 아니라 그룹화된 막대와 누적 막대와 같은 여러 변형이 있습니다. 막대 그래프의 대안으로는 점 그래프와 히트맵이 있습니다.
6.1 Bar plots

표는 2017년 크리스마스 주말에 가장 높은 티켓 판매량을 기록한 상위 다섯 편의 영화들을 보여줍니다. 영화 "스타워즈: 라스트 제다이"는 그 주말에 가장 인기 있는 영화였으며, 네 번째와 다섯 번째로 순위에 오른 영화 "위대한 쇼맨"과 "페르디난드"의 판매량을 거의 10배 가까이 능가했습니다.
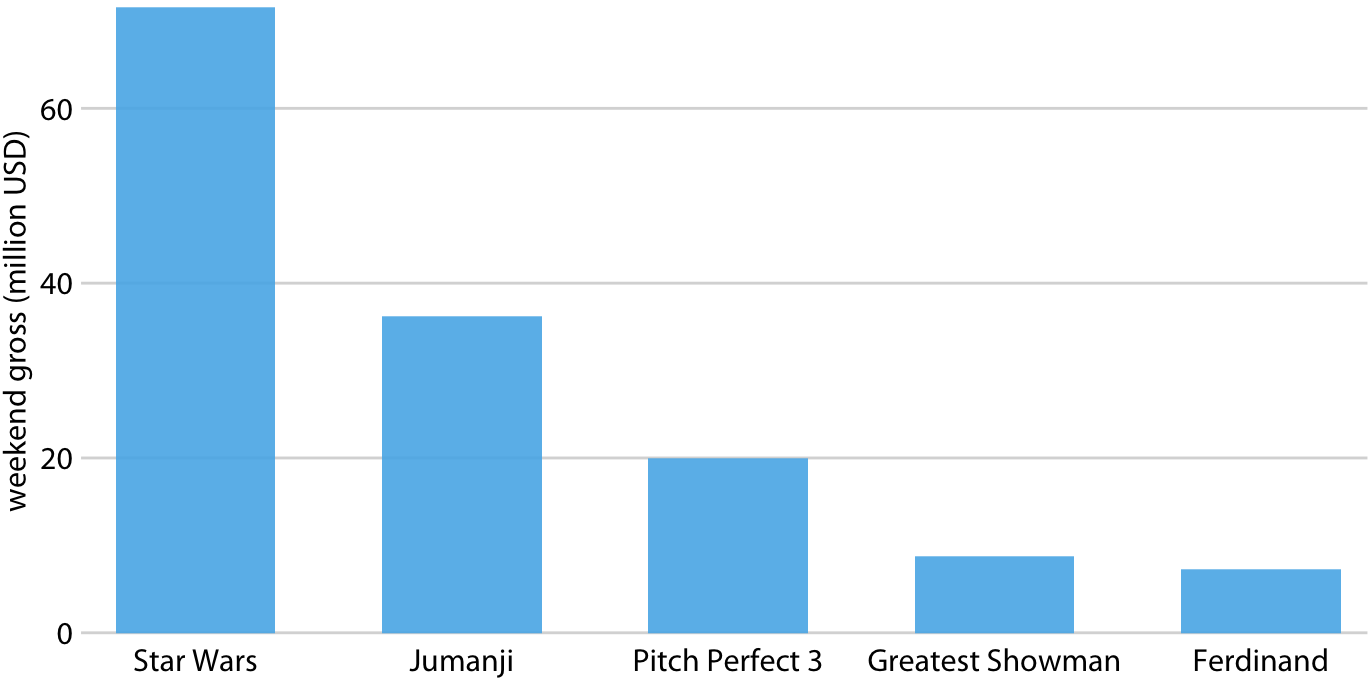
이러한 종류의 데이터는 일반적으로 세로 막대를 사용하여 시각화됩니다. 각 영화에 대해 막대를 그리는데, 이 막대는 0에서 시작하여 해당 영화의 주말 총 수익에 해당하는 금액까지 확장됩니다. 이러한 시각화는 막대 그래프 또는 막대 차트라고 불립니다.
세로 막대 그래프에서 흔히 겪는 문제 중 하나는 각 막대를 식별하는 라벨들이 많은 가로 공간을 차지한다는 점입니다.
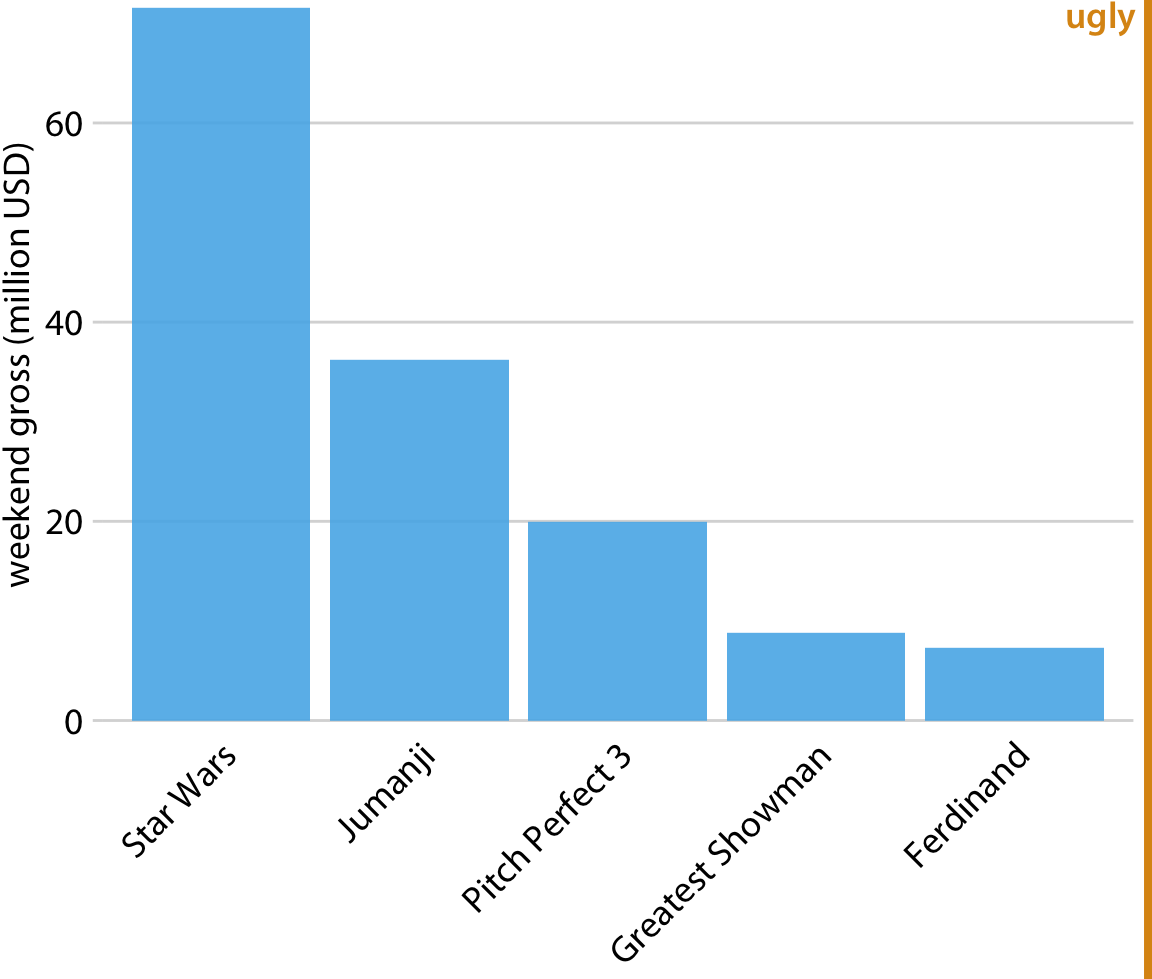
2017년 12월 22-24일 주말 동안 가장 높은 수익을 기록한 영화들을 회전된 축 눈금 라벨과 함께 막대 그래프로 표시한 것입니다. 회전된 축 눈금 라벨은 읽기 어려우며, 그래프 아래에 어색한 공간 사용을 요구합니다.
긴 라벨에 대한 더 나은 해결책은 보통 x축과 y축을 교환하여 막대가 가로로 표시되도록 하는 것입니다
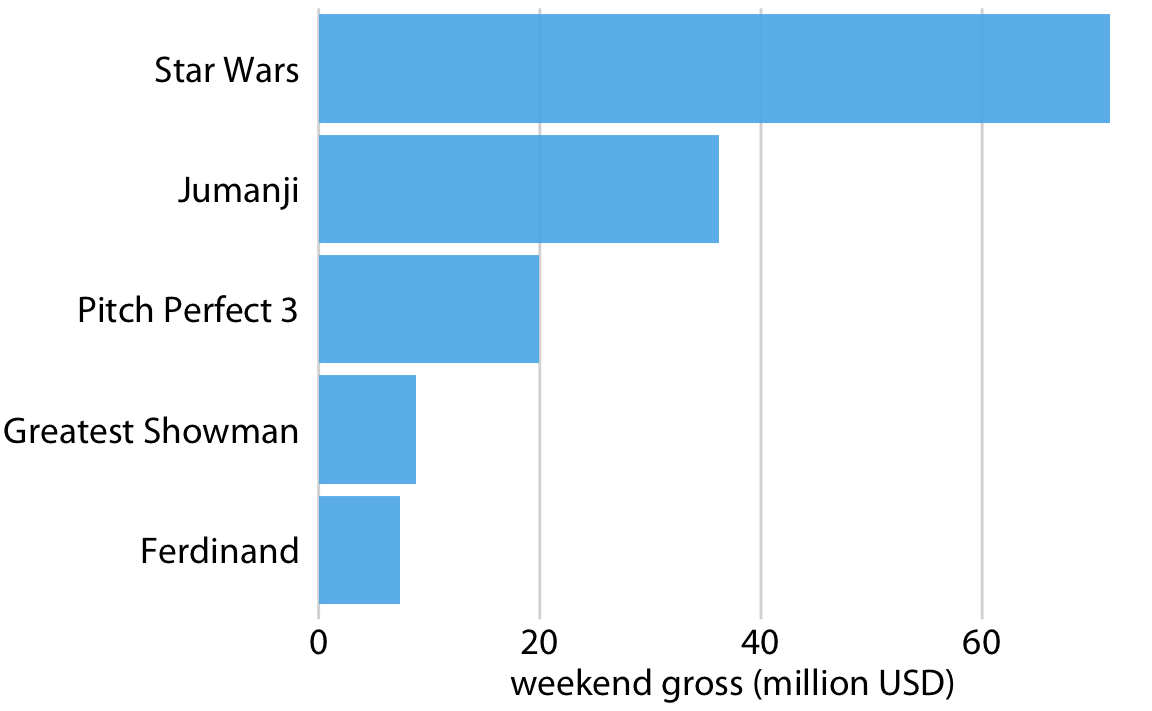
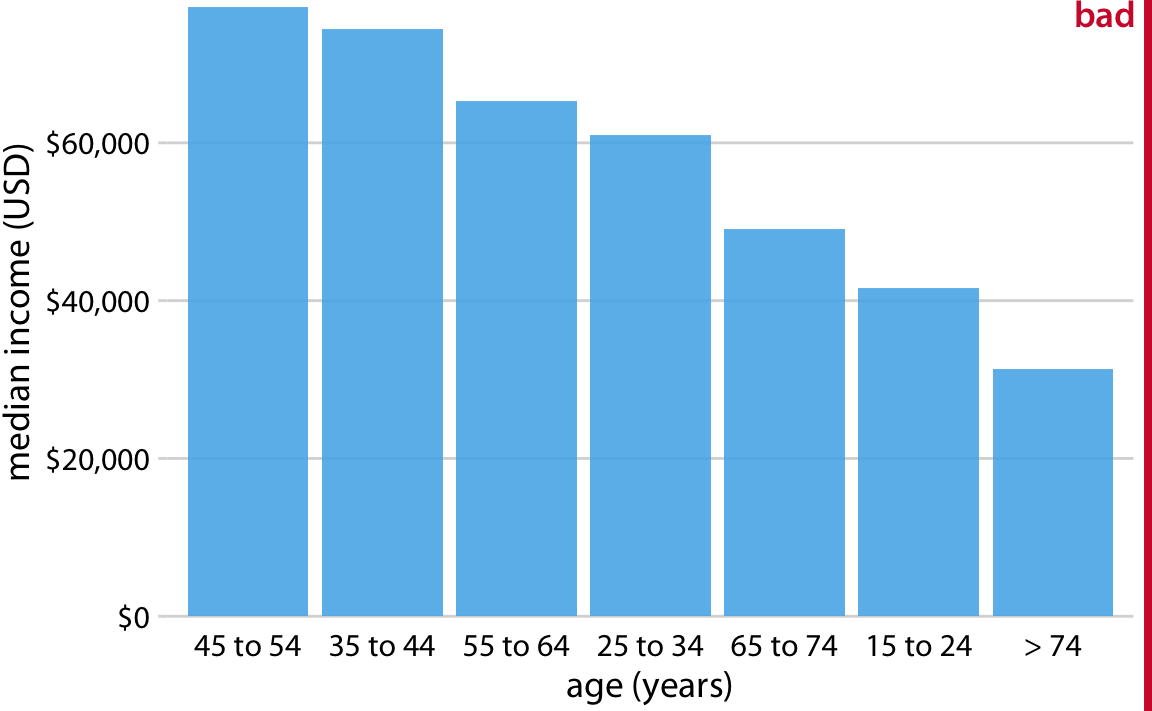
막대를 세로로 배치하든 가로로 배치하든, 막대의 배열 순서에 주의를 기울여야 합니다.
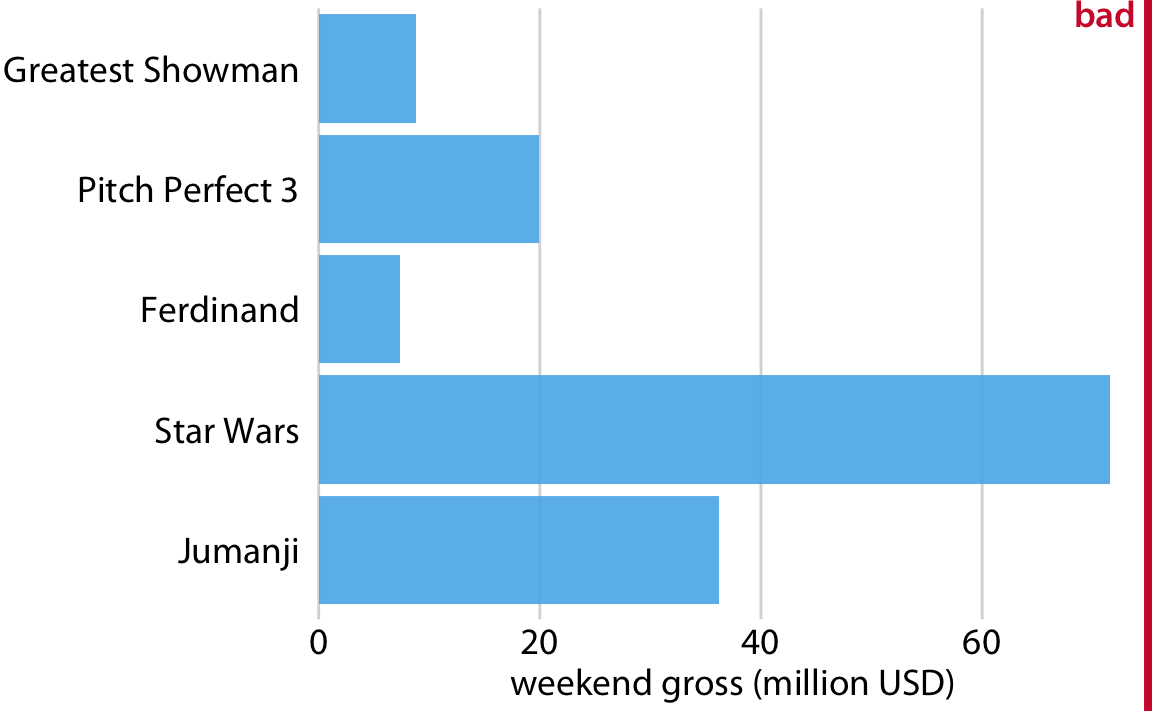
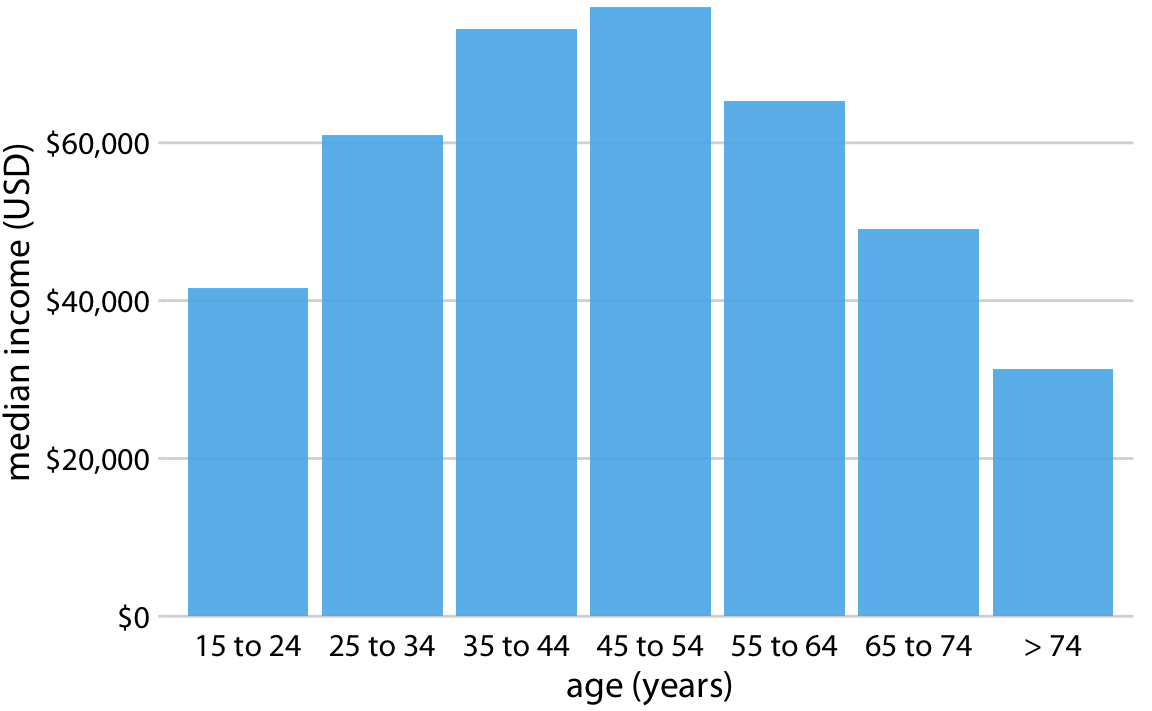
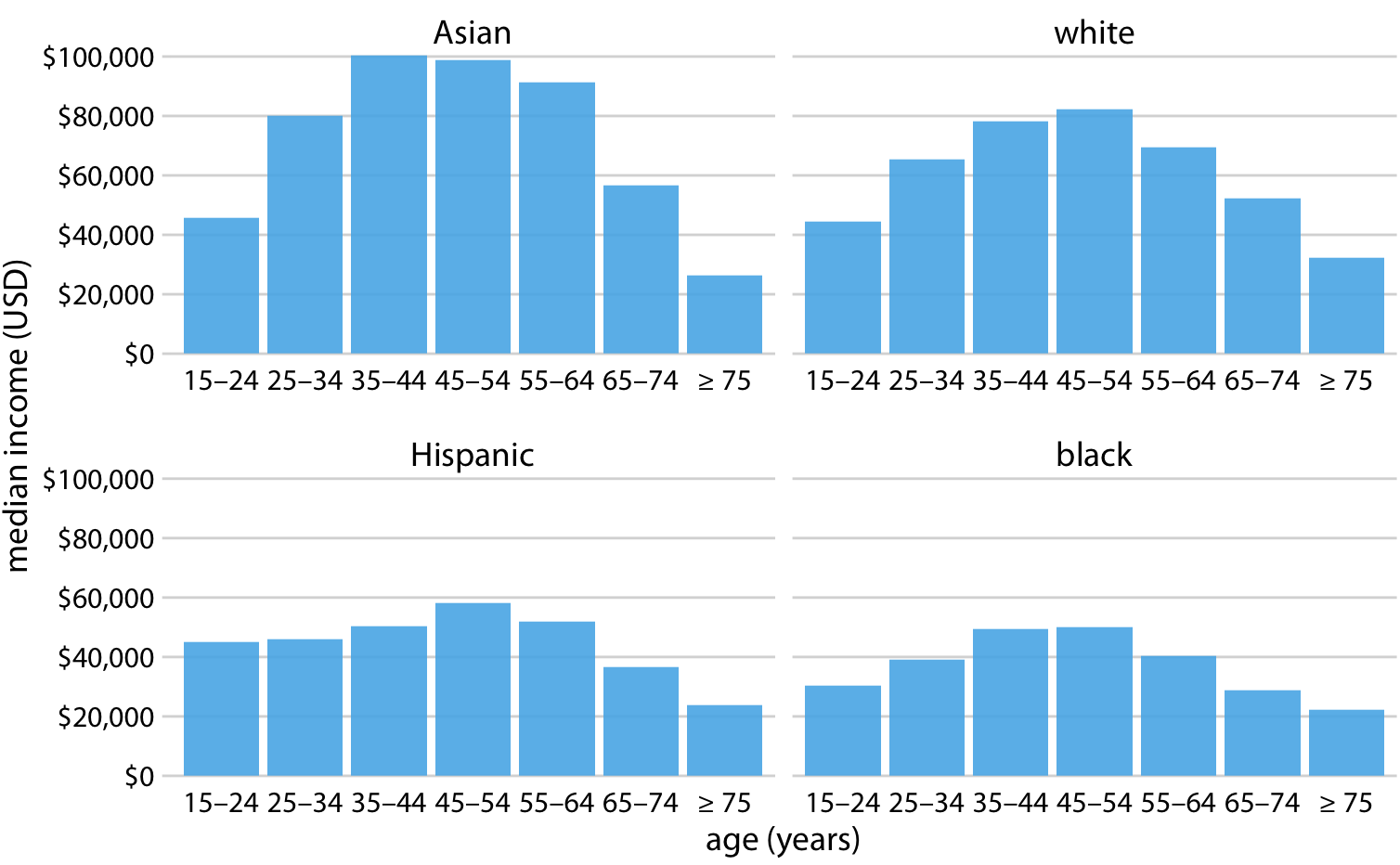
그러나 막대를 재배열할 때는 막대가 나타내는 카테고리에 자연스러운 순서가 없을 때만 그렇게 해야 합니다. 카테고리가 자연스러운 순서를 가지고 있을 때(즉, 범주형 변수가 순서가 있는 요인일 때)는 그 순서를 시각화에서 유지해야 합니다. 예를 들어, 아래의 그림 연령대별로 미국에서의 연간 중위 소득을 보여줍니다. 이 경우, 막대는 연령이 증가하는 순서대로 배열되어야 합니다. 연령대를 섞어가며 막대 높이에 따라 정렬하는 것은 의미가 없습니다.
6.2 Grouped and stacked bars
우리는 종종 두 개의 범주형 변수에 동시에 관심을 갖게 됩니다.
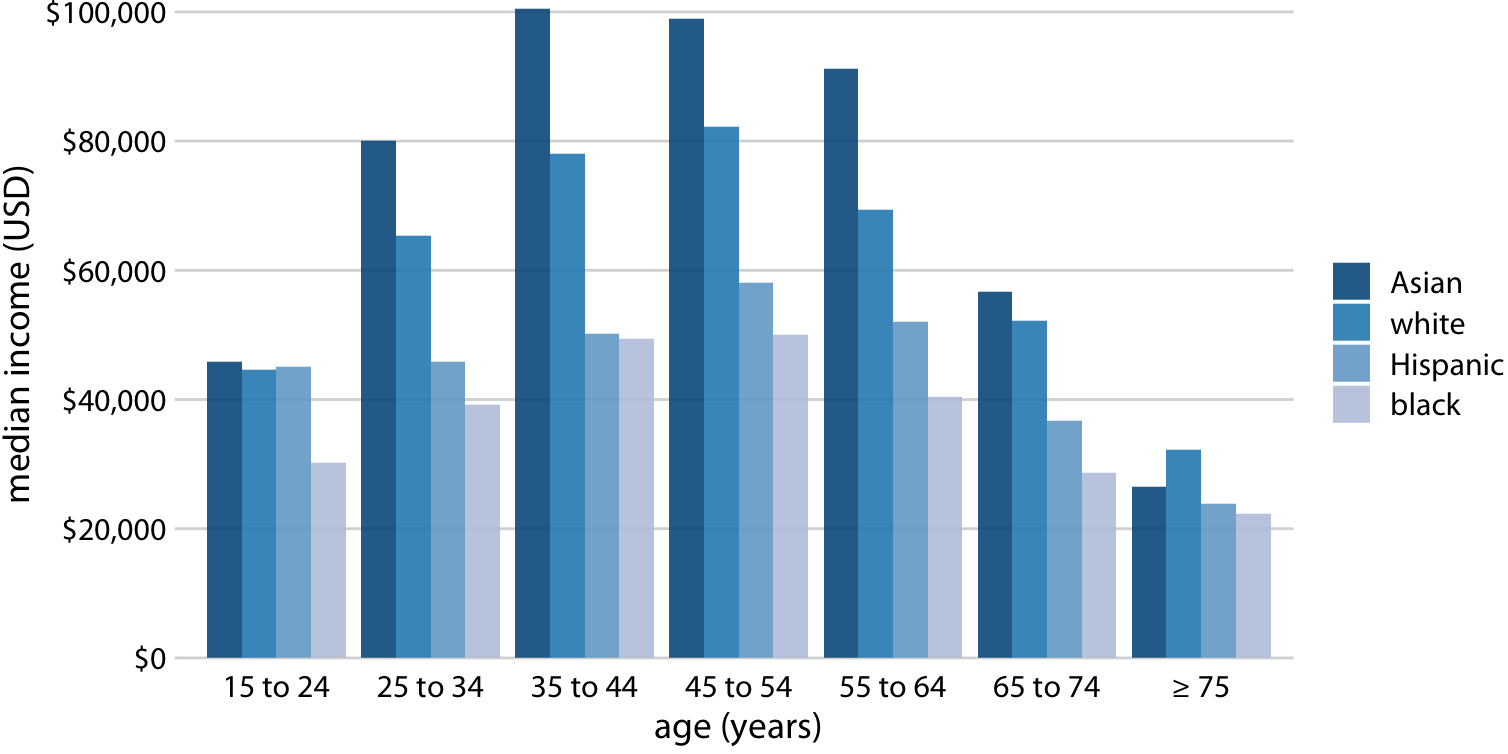
2016년 미국 연간 가구 중위 소득과 연령대 및 인종 간의 관계를 나타낸 그래프입니다. x축에는 연령대가 표시되어 있으며, 각 연령대에 대해 아시아인, 백인, 히스패닉, 흑인의 중위 소득에 해당하는 네 개의 막대가 각각 표시됩니다. 데이터 출처: 미국 인구조사국.
그룹화된 막대 그래프는 한 번에 많은 정보를 보여주기 때문에 혼란스러울 수 있습니다. 위 그림은 특정 인종 그룹에 대해 연령대별 중위 소득을 비교하기가 어렵습니다. 따라서 특정 연령대에 대해 인종 그룹 간 소득 수준의 차이에 주로 관심이 있는 경우에 적합합니다.
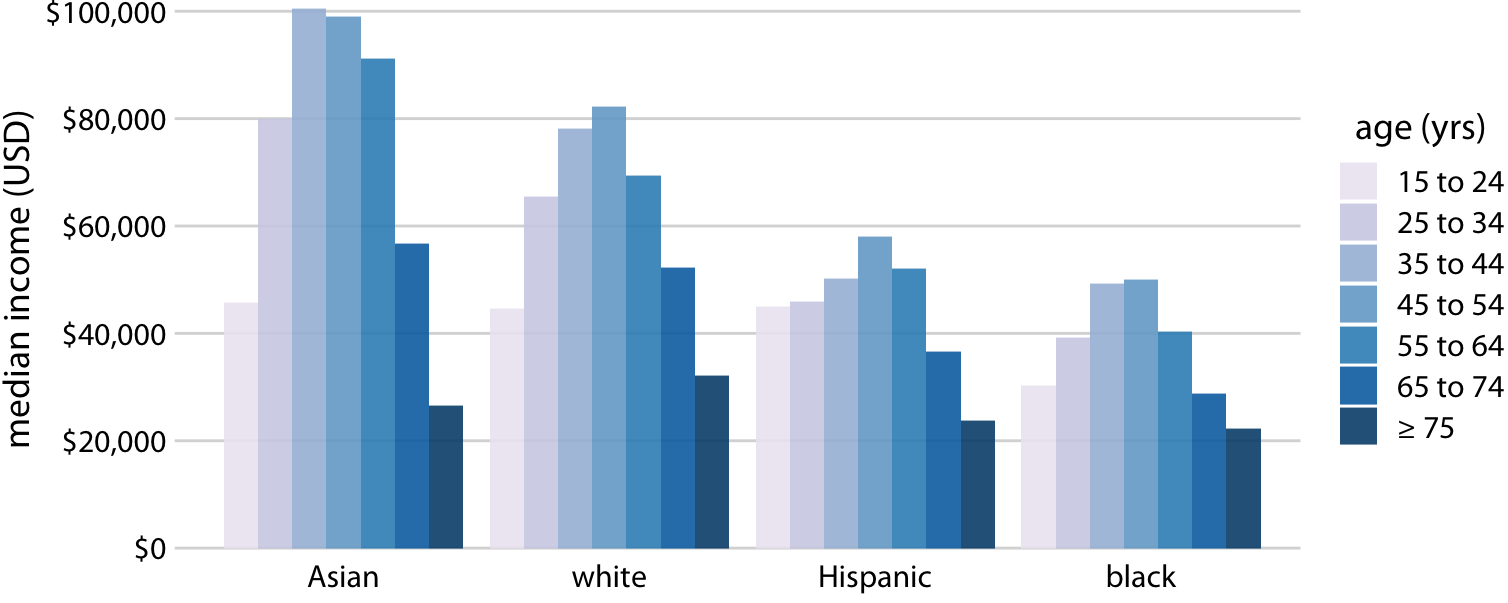
만약 인종 그룹 간 소득 수준의 전반적인 패턴에 더 관심이 있다면, x축에 인종을 표시하고 각 인종 그룹 내에서 연령대를 구분하여 막대를 보여주는 것이 더 나을 수 있습니다.
위 두 경우 모두 위치에 의한 인코딩은 읽기 쉽지만, 색상에 의한 인코딩은 더 많은 정신적 노력이 필요합니다. 왜냐하면 우리는 막대의 색상을 범례의 색상과 정신적으로 매칭해야 하기 때문입니다. 이러한 추가적인 정신적 노력을 피하기 위해 하나의 그룹화된 막대 그래프 대신 아래의 네 개의 개별적인 막대 그래프를 보여줄 수 있습니다.
막대 그룹을 나란히 그리는 대신, 때로는 막대를 서로 위에 쌓는 것이 더 좋을 수 있습니다. 막대를 쌓는 것은 개별적으로 쌓인 막대들이 나타내는 값들의 합이 그 자체로 의미 있는 값일 때 유용합니다.
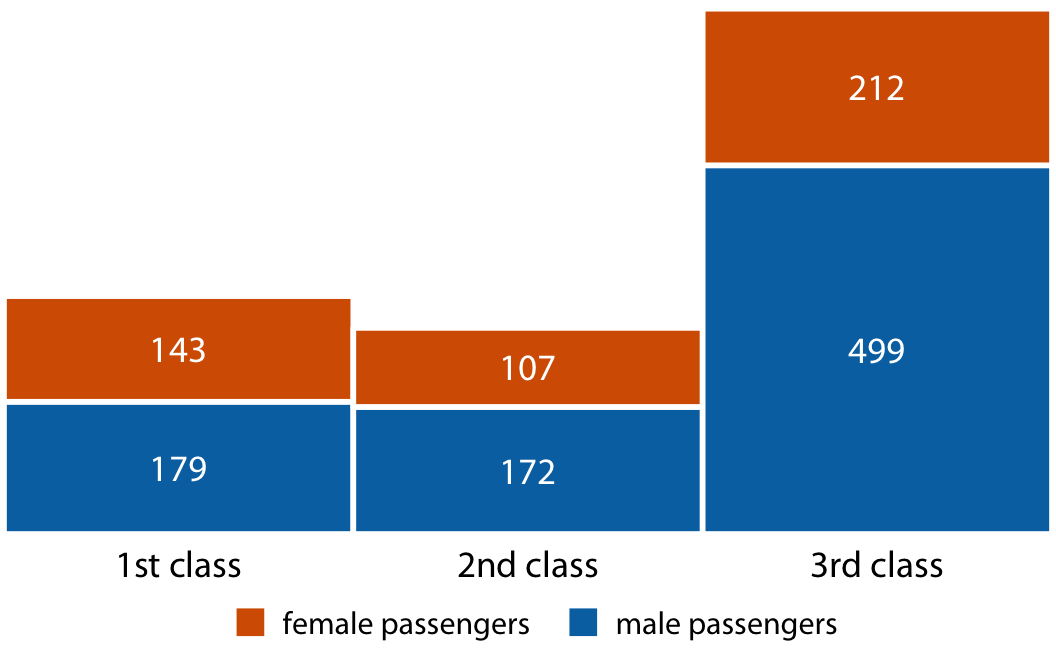
1912년 4월 15일에 침몰한 대서양 횡단 여객선 타이타닉호의 승객들에 대한 데이터를 사용하겠습니다. 승무원을 제외한 약 1300명의 승객이 탑승해 있었으며, 이 승객들은 1등석, 2등석, 3등석 중 하나에서 여행하고 있었습니다. 배에는 여성보다 남성 승객이 거의 두 배 더 많았습니다. 승객들을 등급과 성별로 분류하기 위해, 각 등급과 성별에 대해 개별적인 막대를 그리고, 여성 승객을 나타내는 막대를 남성 승객을 나타내는 막대 위에 쌓아 각각의 등급에 대해 따로 표시할 수 있습니다.
6.3 Dot plots and heatmaps
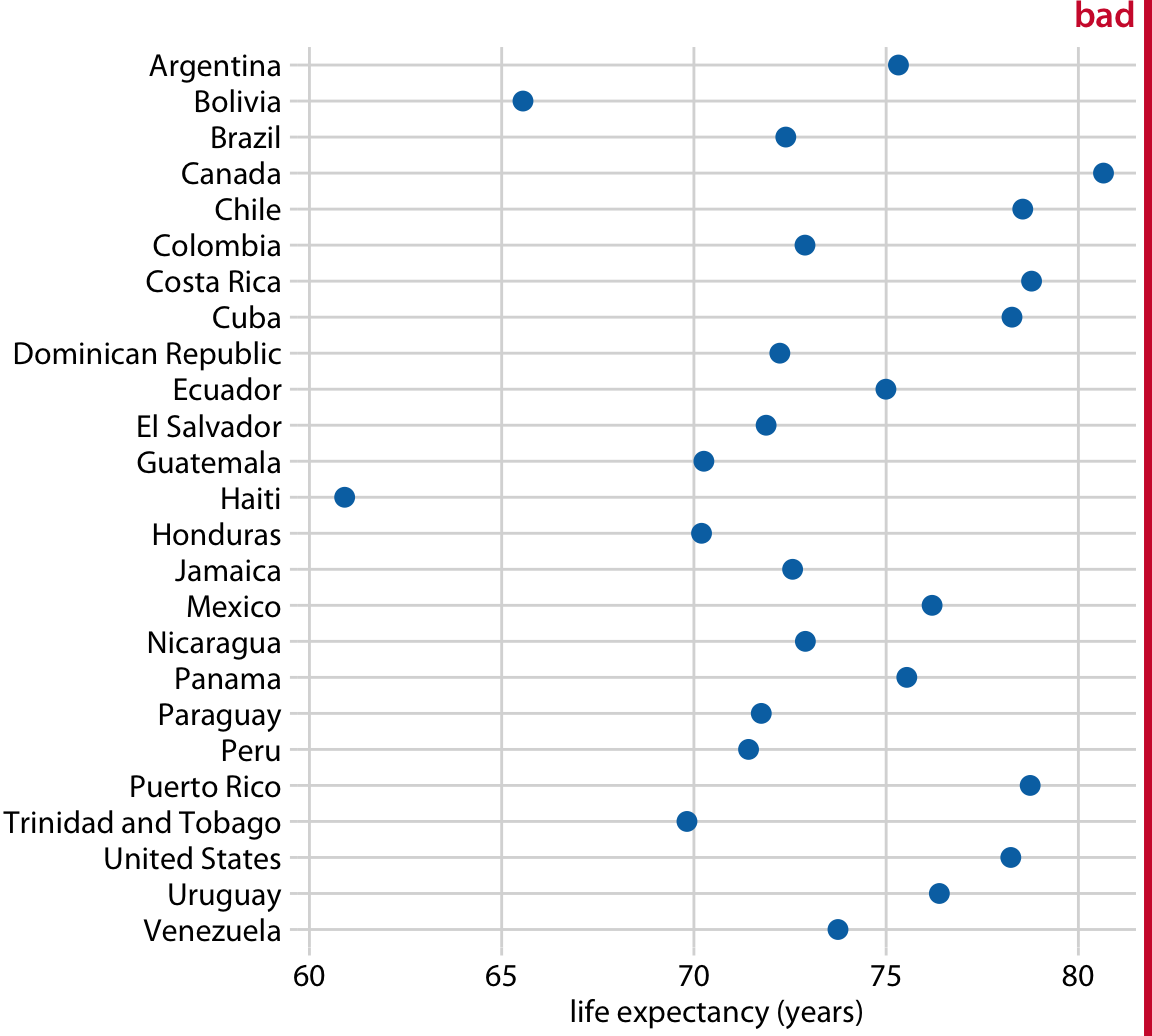
막대의 중요한 제한 중 하나는 막대 길이가 표시된 금액에 비례하도록 막대가 0에서 시작해야 한다는 점입니다. 일부 데이터셋에서는 이것이 비실용적이거나 중요한 특징을 가릴 수 있습니다. 이 경우, amount를 x축이나 y축을 따라 적절한 위치에 점을 배치하여 나타낼 수 있습니다.
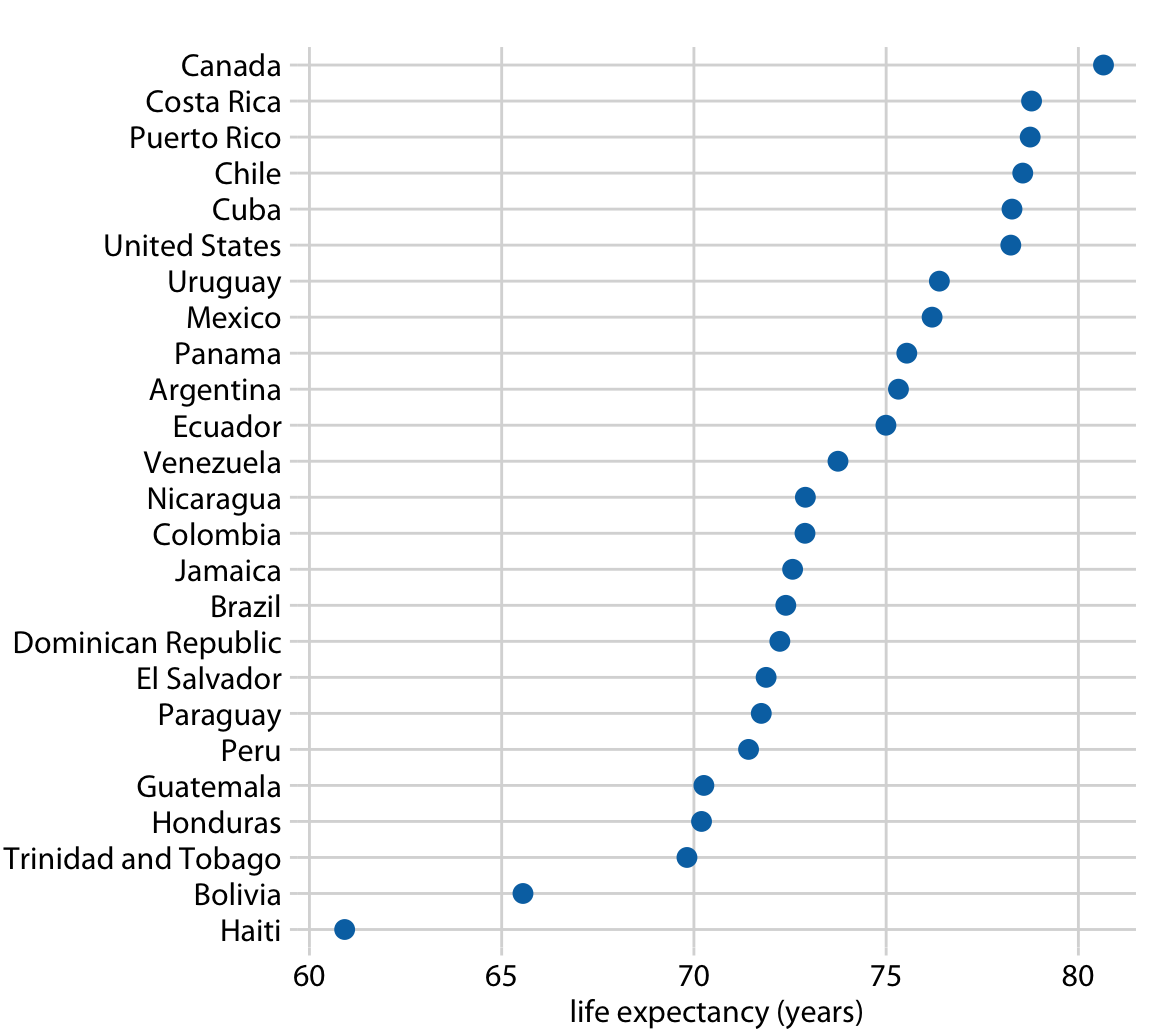
25개의 아메리카 국가에서의 기대 수명 데이터셋에 대해 이러한 시각화 접근 방식을 보여줍니다. 이 국가들의 기대 수명은 60년에서 81년 사이이며, 각 개별 기대 수명 값은 x축의 적절한 위치에 파란색 점으로 표시되어 있습니다. 축의 범위를 60년에서 81년으로 제한함으로써 이 그림은 데이터셋의 주요 특징을 강조합니다.
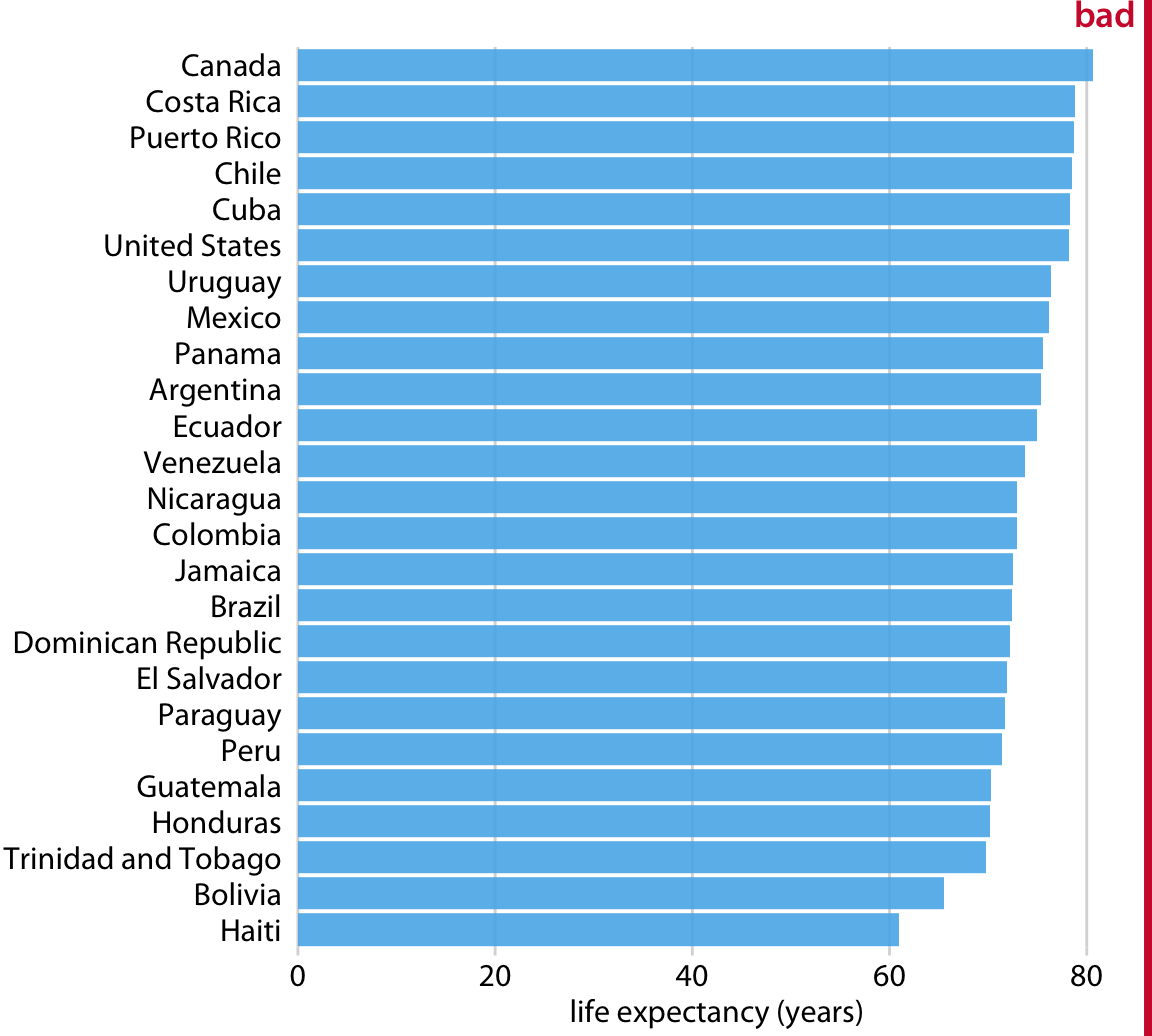
이 그림에서 막대가 너무 길고 거의 동일한 길이를 가지기 때문에, 눈은 막대의 끝이 아닌 중간 부분으로 집중되며, 이로 인해 그림이 전달하려는 메시지가 흐려지게 됩니다.
그러나 막대나 점을 사용하든 상관없이, 데이터 값의 정렬 순서에 주의를 기울여야 합니다.
지금까지의 모든 예시는 막대의 끝점이나 점의 위치를 통해 위치 척도를 따라 amount를 나타냈습니다. 그러나 매우 큰 데이터셋에서는 이러한 방법이 적합하지 않을 수 있습니다. 왜냐하면 결과적으로 도표가 너무 복잡해지기 때문입니다.
막대나 점을 통해 위치에 데이터를 매핑하는 것 대신, 데이터 값을 색상에 매핑할 수 있습니다. 이러한 도표를 히트맵이라고 부릅니다.
이 방법을 사용하여 1994년부터 2016년까지 23년 동안 20개국에서의 인터넷 사용자 비율을 보여줍니다. 이 시각화는 정확한 데이터 값을 파악하기는 어렵게 만들지만(예: 2015년 미국의 인터넷 사용자 비율은 정확히 얼마인가?), 더 넓은 추세를 강조하는 데 탁월한 효과를 발휘합니다. 어느 국가에서 인터넷 사용이 일찍 시작되었고, 그렇지 않았는지를 명확하게 볼 수 있으며, 또한 데이터셋의 마지막 해인 2016년에 어느 국가들이 높은 인터넷 보급률을 가지고 있는지도 명확하게 알 수 있습니다.
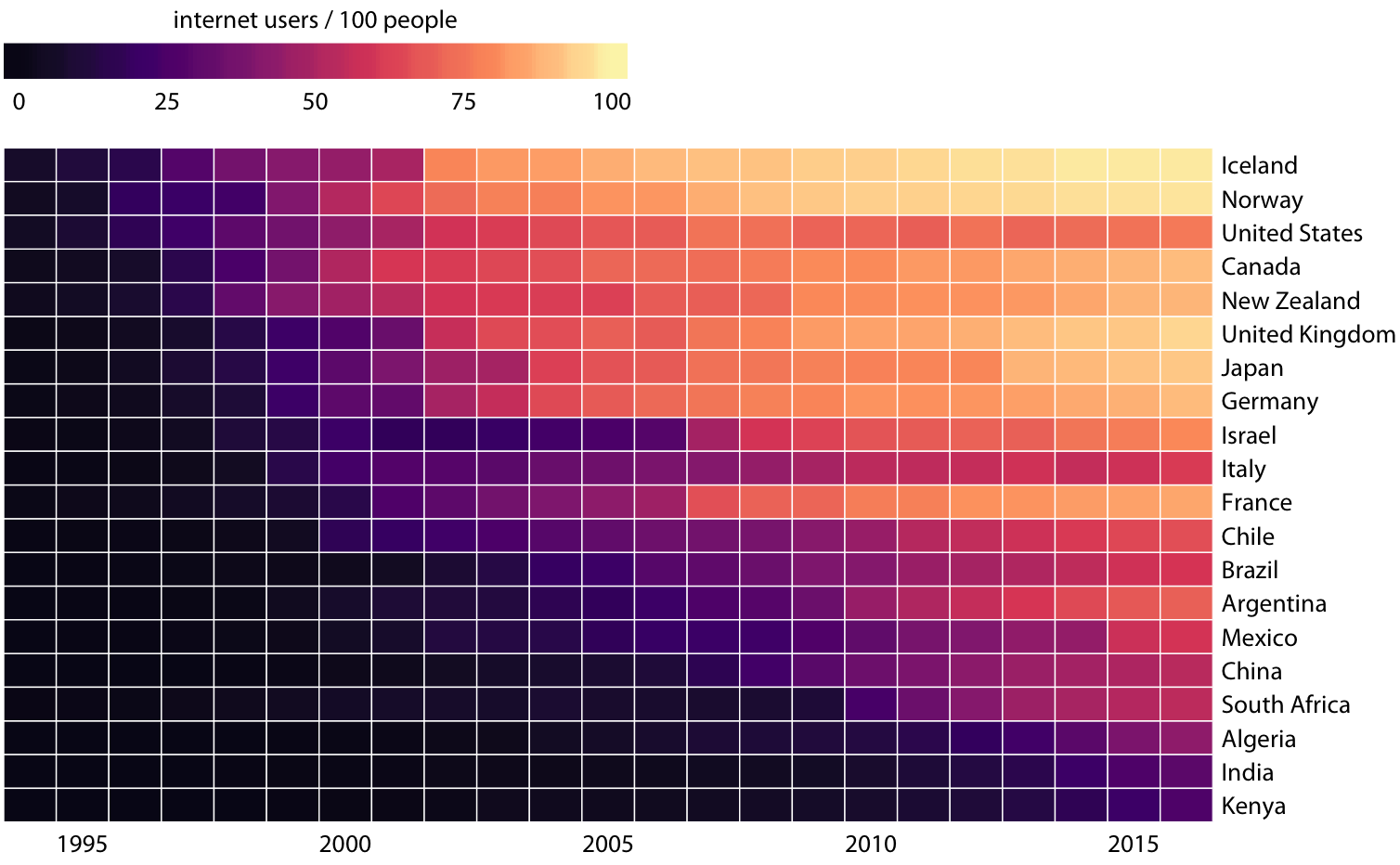
이 장에서 논의된 다른 모든 시각화 방법과 마찬가지로, 히트맵을 만들 때도 범주형 데이터 값의 정렬에 주의를 기울여야 합니다.
위 그림은 국가들을 인터넷 사용이 처음으로 20%를 넘은 연도에 따라 정렬하였습니다.
