
ODQA 프로젝트 진행 중 다양한 Retrieval을 알게 되었다. 그 중 ColBERT와 관련된 내용을 작성해본다.
colBERT란 dense retrieval에서 일반적으로 사용하는 벡터 임베딩 기법과 sparse retrieval의 효율성을 결합한 모델이다.
4가지 단계로 진행된다.
-
training
문서와 쿼리 사이의 의미적 유사성을 반영하는 임베딩을 학습한다.
쿼리 및 문서 임베딩: ColBERT는 쿼리와 문서를 각각 BERT를 사용해 임베딩 벡터로 변환한다. 이때 단순히 하나의 벡터로 문서나 쿼리를 표현하는 것이 아니라, 각 토큰마다 임베딩 벡터를 생성한다. 즉, 문서와 쿼리 모두 여러 개의 임베딩 벡터로 표현된다.
MaxSim Loss: 훈련 시 쿼리와 문서 간의 유사도를 계산할 때, 쿼리와 문서의 각 토큰 임베딩을 비교하여 가장 유사한 토큰 페어의 유사도를 활용한다. 이를 통해 세밀한 토큰 수준에서 상호작용을 고려할 수 있다. -
indexing
문서 컬렉션에 포함된 모든 문서의 임베딩을 미리 계산하고 저장하는 과정이다. 이 단계는 검색 시 빠른 성능을 제공하기 위해 매우 중요하다.
문서 토큰 임베딩 계산: 훈련이 완료된 ColBERT 모델을 사용해, 데이터베이스에 있는 모든 문서의 각 토큰에 대한 임베딩을 계산한다. 일반적인 dense retrieval 모델은 문서 전체를 하나의 벡터로 변환하지만, ColBERT는 각 문서의 모든 토큰에 대해 개별 임베딩 벡터를 계산한다. -
searching
검색과정에서는 주어진 쿼리와 데이터베이스에 있는 문서들 간의 유사도를 계산해 관련 문서를 반환한다.
쿼리 토큰 임베딩 계산: 사용자가 입력한 쿼리에 대해 BERT를 사용하여 각 토큰의 임베딩 벡터를 계산한다. 이 벡터들은 인덱스에 저장된 문서 토큰 임베딩과 비교되어야 한다.
유사도 계산 및 정렬: 문서의 모든 토큰에 대해 쿼리의 모든 토큰과 비교한 후, 가장 높은 유사도를 가진 토큰 간의 매칭 결과를 기반으로 문서 전체의 유사도를 계산한다. 이 유사도를 바탕으로 관련성이 높은 문서들을 정렬하여 검색 결과로 반환한다.
-
inference
reader 부분만 실행하면 된다.
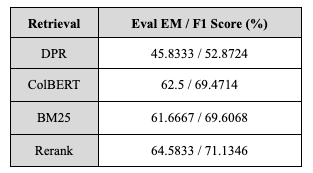
실험 결과, DPR보다 colBERT의 성능이 더 우수했다. 이는 DPR이 문서나 쿼리를 단일 벡터로 표현하는 것과 달리, colBERT는 각 토큰마다 임베딩 벡터를 생성하여 문서와 쿼리를 여러 개의 임베딩 벡터로 표현함으로써 더 풍부한 문맥 정보를 반영할 수 있기 때문이라고 생각된다. 또한 BM25와 유사한 성능을 보였으며, Elastic Search를 사용한 Rerank를 Retrieval로 사용했을 때보다는 성능이 낮았다. Elastic Search의 Rerank가 colBERT보다 더 나은 성능을 보인 이유는, Rerank 과정에서 검색 결과의 품질을 추가로 향상시키고, Elastic Search가 대규모 데이터에서 더 효율적이고 최적화된 Retrieval을 제공하기 때문이라고 생각한다.
프로젝트의 마감일이 다가왔을 때 ColBERT를 사용하여 실험을 진행하였고 BM25만큼 성능이 잘 나오는 것을 확인해서 제출해보지 못한 것과 코드를 베이스라인 코드에 이식하지 못한 것이 아쉬움으로 남아있다.
