
선행후기 (먼저 실행하고 나중에 기록한다.) ✍️
부스트캠프 AI Tech NLP 트랙 기업 해커톤에서 HyperClovaX를 활용한 자동 콘텐츠 생성 서비스를 개발하였다.
이 서비스는 카피라이트와 음악을 포함한 다양한 콘텐츠를 자동으로 생성한다. 🎵✨
🎯 음악과 관련된 작업
1️⃣ 음악 생성 모델 리서치
2️⃣ 생성된 음악을 평가하기
먼저, LLM을 활용한 음악 생성 기능을 구현하기 위해 음악 생성 모델을 조사하였다.
후보로 검토한 모델은 다음과 같다.
🎶 음악 생성 모델 후보
✔️ MusicGen
✔️ AudioLDM2
✔️ MusicLDM
이 중, 나는 Meta의 MusicGen과 관련된 논문을 분석하며 해당 모델의 구조와 작동 방식을 연구하였다.
📖 논문 원문: Simple and Controllable Music Generation
🤯 솔직한 후기
솔직히 말해, 논문의 절반 이상을 완전히 이해하지 못했다... 😭
코드북 패턴(Codebook pattern), 인터리빙(Interleaving) 등 처음 접하는 개념이 많았기 때문이다.
🔎 논문에서 주목한 내용
가장 중요한 부분 중 하나는, 음악 샘플, 코드, 모델이 오픈소스로 공개되어 있다는 점이다.연구자와 개발자는 아래 깃허브 리포지토리를 통해 이를 활용할 수 있다.
🔗 GitHub - facebookresearch/audiocraft
또한, 생성된 음악의 품질이 만족스럽지 않을 경우, 파인튜닝(Fine-tuning)이 필요할 수도 있다.이 점에서 MusicGen은 오픈소스 모델이라는 강점이 있다.
하지만 실험 결과,MusicGen은 추가적인 파인튜닝 없이도 충분히 고품질의 음악을 생성할 수 있었다.
📊 MusicGen과 다른 음악 생성 모델 비교 평가
🔍 비교 대상 모델
✔️ Riffusion
✔️ Mousai
✔️ MusicLM
✔️ Noise2Music
📌 평가 메트릭
객관적 평가
Fréchet Audio Distance (FAD) → 생성된 오디오의 품질(현실감) 평가
Kullback-Leibler Divergence (KL) → 생성된 음악과 원본 음악의 유사성 평가
CLAP Score → 생성된 음악과 텍스트 설명 간의 정렬 평가
주관적 평가
Overall Quality (OVL) → 전반적인 오디오 품질 평가
Relevance to Text Input (REL) → 생성된 음악이 입력 텍스트와 얼마나 관련 있는지 평가
📈 평가 결과
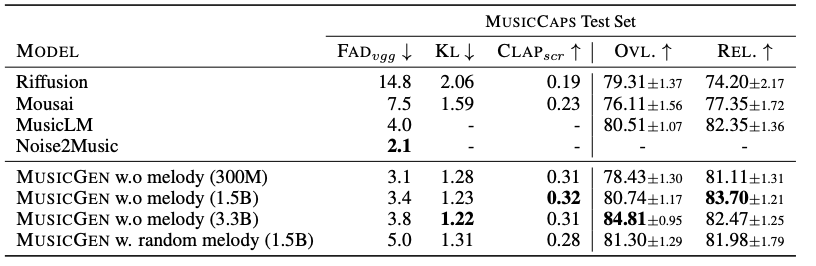
💡 MusicGen 성능 요약
✅ 오디오 품질과 텍스트 관련성에서 기준 모델들보다 우수
✅ Noise2Music은 FAD에서 가장 낮은 점수를 기록했지만, MusicGen은 인간 평가에서 더 나은 성과를 보임

📊 모델 크기별 성능 분석
✅ 모델 크기가 클수록 성능이 개선됨
✅ 주관적 품질(OVL)은 1.5B 모델에서 최적, 큰 모델(3.3B)은 텍스트 입력을 더 잘 이해.
🎵 실험 및 최종 선택
musicgen 데모 사이트에서 다양한 모델로 생성된 음악을 직접 들어볼 수 있었다.
팀원들과 블라인드 테스트를 진행한 결과, MusicGen의 선호도가 가장 높았다!
⚠️ 다른 모델들은 기계음이 강하거나 노이즈가 많았음.
📌 결론
최종적으로 MusicGen을 프로젝트에 적용하였다.
그 이유는 논문에서도 확인된 인간 평가에서의 우수한 성능 때문이었다.
📌 MusicGen을 프로젝트에서 어떻게 활용했는가?
영어로 프롬프트를 입력하면 해당 내용에 맞는 음악을 생성한다.
다음에는,
프롬프트를 생성하는 방법과
생성된 음악을 평가하는 방법에 대한 글을 작성하려고 한다.
