[번역] Fundamentals of Data Visualization - 8 Visualizing distributions: Empirical cumulative distribution functions and q-q plots
Fundamentals of Data Visualization

8 Visualizing distributions: Empirical cumulative distribution functions and q-q plots
히스토그램이나 밀도 그래프(density plot)와 같은 전통적인 방법들은 직관적이고 시각적으로 매력적이지만, 사용자가 선택해야 하는 매개변수(예: 히스토그램의 bin 폭이나 밀도 그래프의 대역폭)에 크게 의존합니다.
대안으로, 모든 데이터 포인트를 개별적으로 점으로 표시하는 방법도 있지만, 데이터셋이 매우 큰 경우 이 방법은 다루기 어려워집니다. 또한 개별 데이터 포인트보다는 분포의 속성을 강조하는 집계 방법에 가치가 있습니다. 이 문제를 해결하기 위해 통계학자들은 경험적 누적 분포 함수(ecdf)와 분위수-분위수(q-q) 플롯을 고안했습니다. 이 시각화 방법들은 임의의 매개변수 선택이 필요 없으며, 데이터를 한 번에 모두 보여줍니다. 그러나 이 방법들은 히스토그램이나 밀도 그래프보다 직관적이지 않아서, 기술적인 출판물 이외에서는 자주 사용되지 않습니다. 그럼에도 불구하고, 통계학자들 사이에서는 매우 인기가 있으며, 데이터 시각화에 관심이 있는 사람이라면 이러한 기술을 익혀야 한다고 저자는 주장합니다.
8.1 Empirical cumulative distribution functions
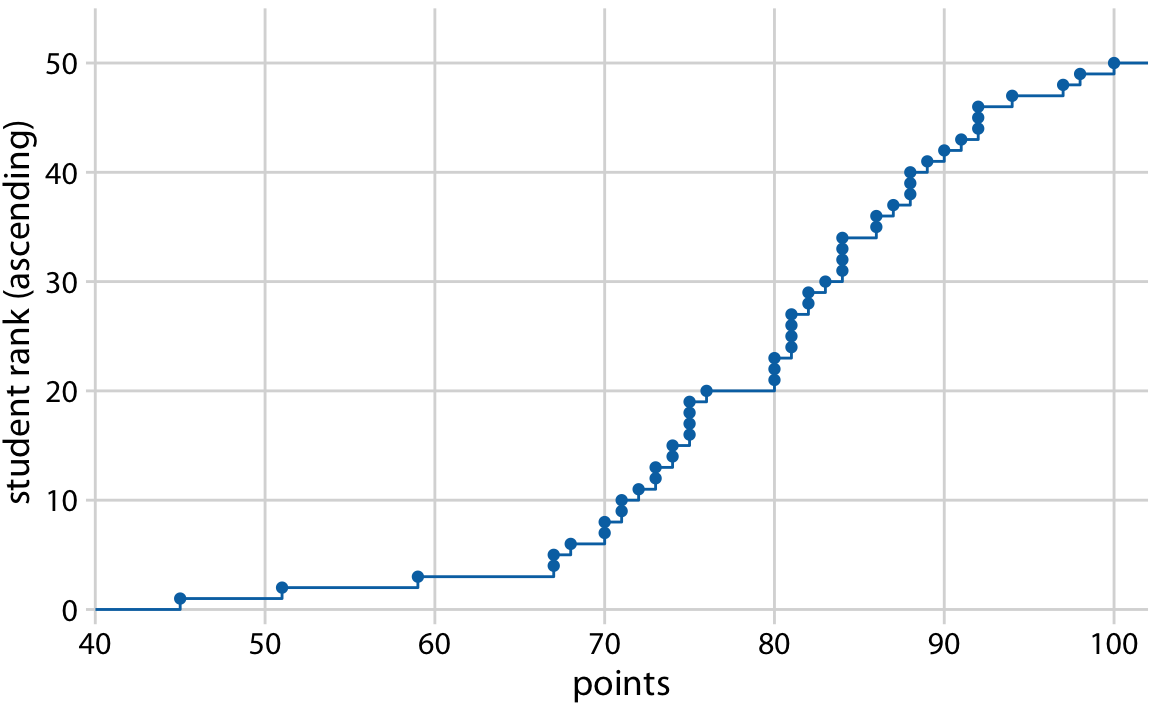
저자는 50명의 학생이 시험을 본 가상의 데이터를 사용하여 이 개념을 설명합니다. 학생들이 0에서 100점 사이에서 점수를 받았고, 이 점수 분포를 시각화하는 방법을 탐구합니다. 누적 경험적 분포 함수는 특정 점수 이하를 받은 학생의 총 수를 모든 가능한 점수에 대해 나타내는 그래프입니다. 이 그래프는 점수가 0일 때 0에서 시작하여, 점수가 100일 때 50에서 끝나는 상승 곡선이 됩니다.
실제 응용에서는, 개별 데이터 포인트를 강조하지 않고 ecdf를 그리는 경우가 많으며, 순위를 최대 순위로 정규화하여 y축이 누적 빈도를 나타내도록 하는 것이 일반적입니다. Figure 8.3은 이러한 방식으로 그린 ecdf를 보여줍니다. 이 방법은 데이터를 보다 간결하게 표현할 수 있으며, y축이 누적 빈도를 나타내기 때문에 분포의 형태를 직관적으로 파악할 수 있습니다.
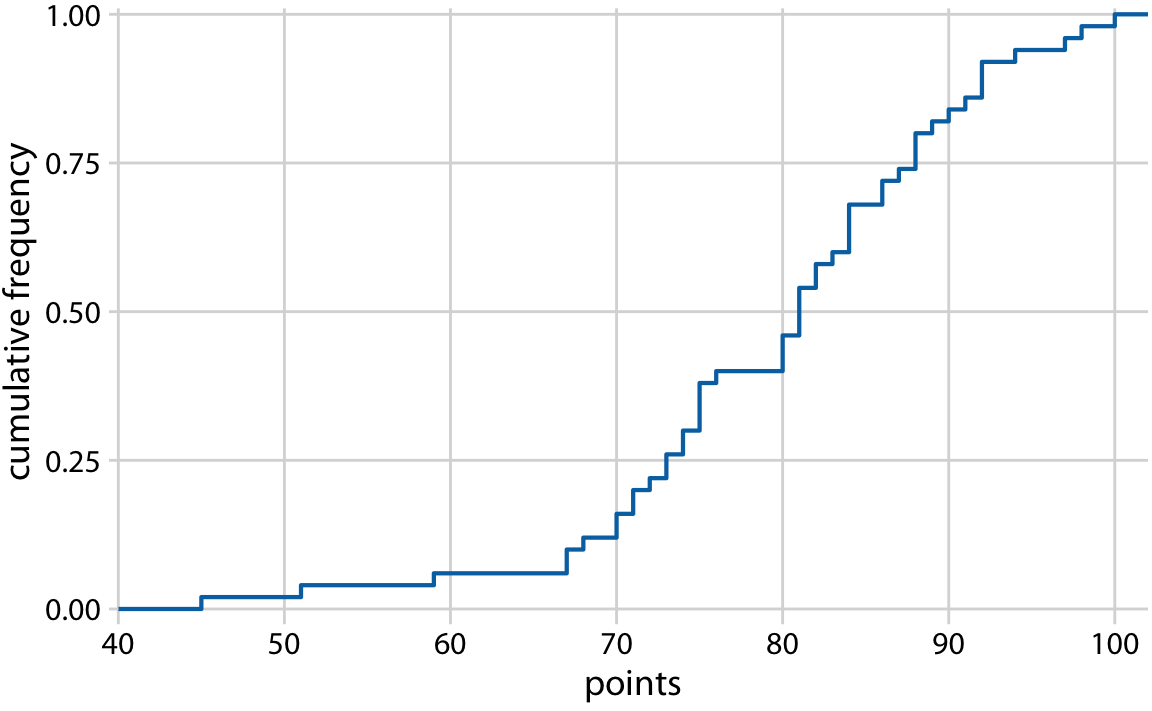
이 그래프에서 우리는 학생 성적 분포의 중요한 속성을 직접 읽어낼 수 있습니다. 예를 들어, 약 25%의 학생들이 75점 미만을 받았으며, 중앙값(누적 빈도가 0.5에 해당하는 점수)은 81점입니다. 또한, 약 20%의 학생들이 90점 이상을 받았습니다.
8.2 Highly skewed distributions
많은 실증적 데이터셋은 오른쪽으로 긴 꼬리를 가지는 매우 편향된 분포를 보여주며, 이러한 분포는 시각화하기 어렵습니다.
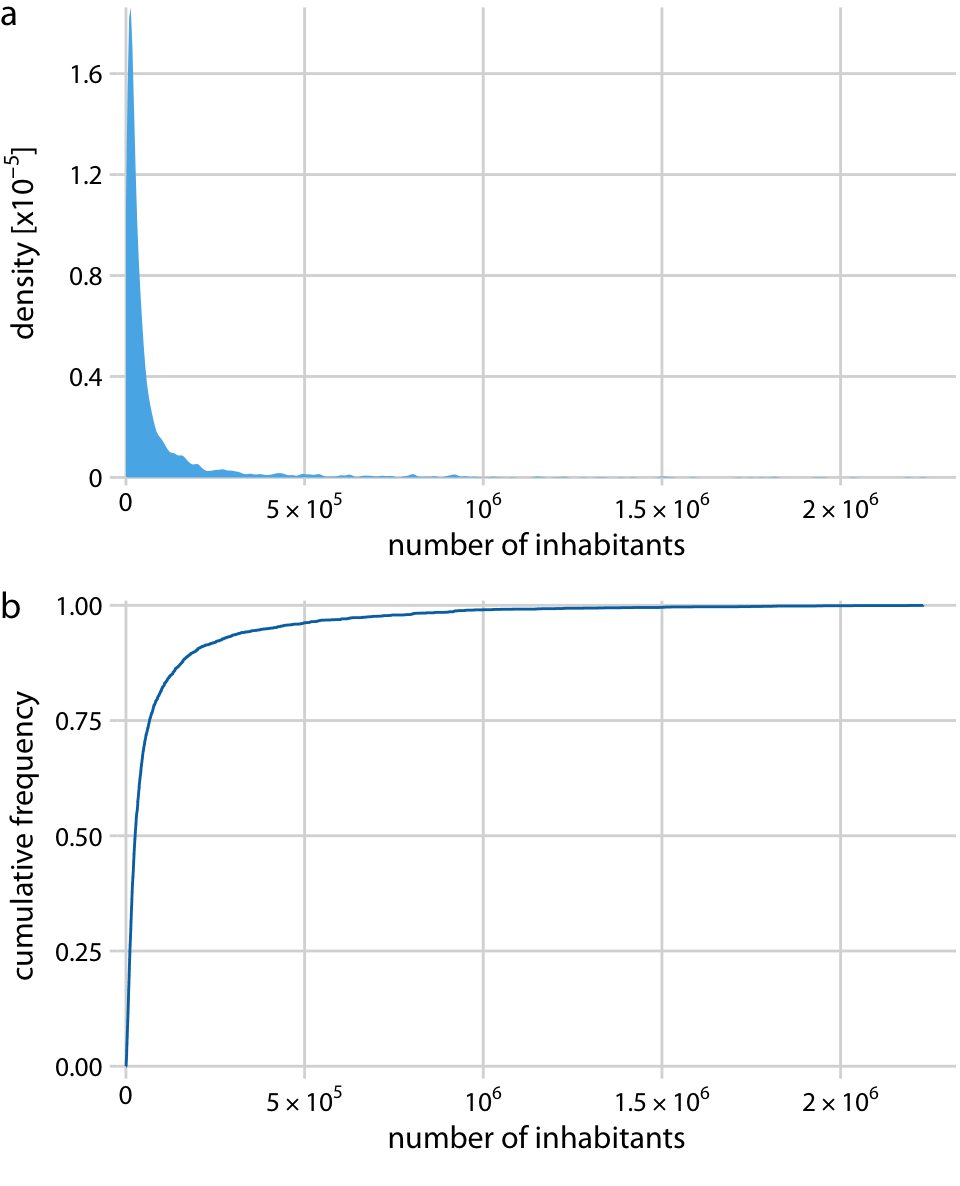
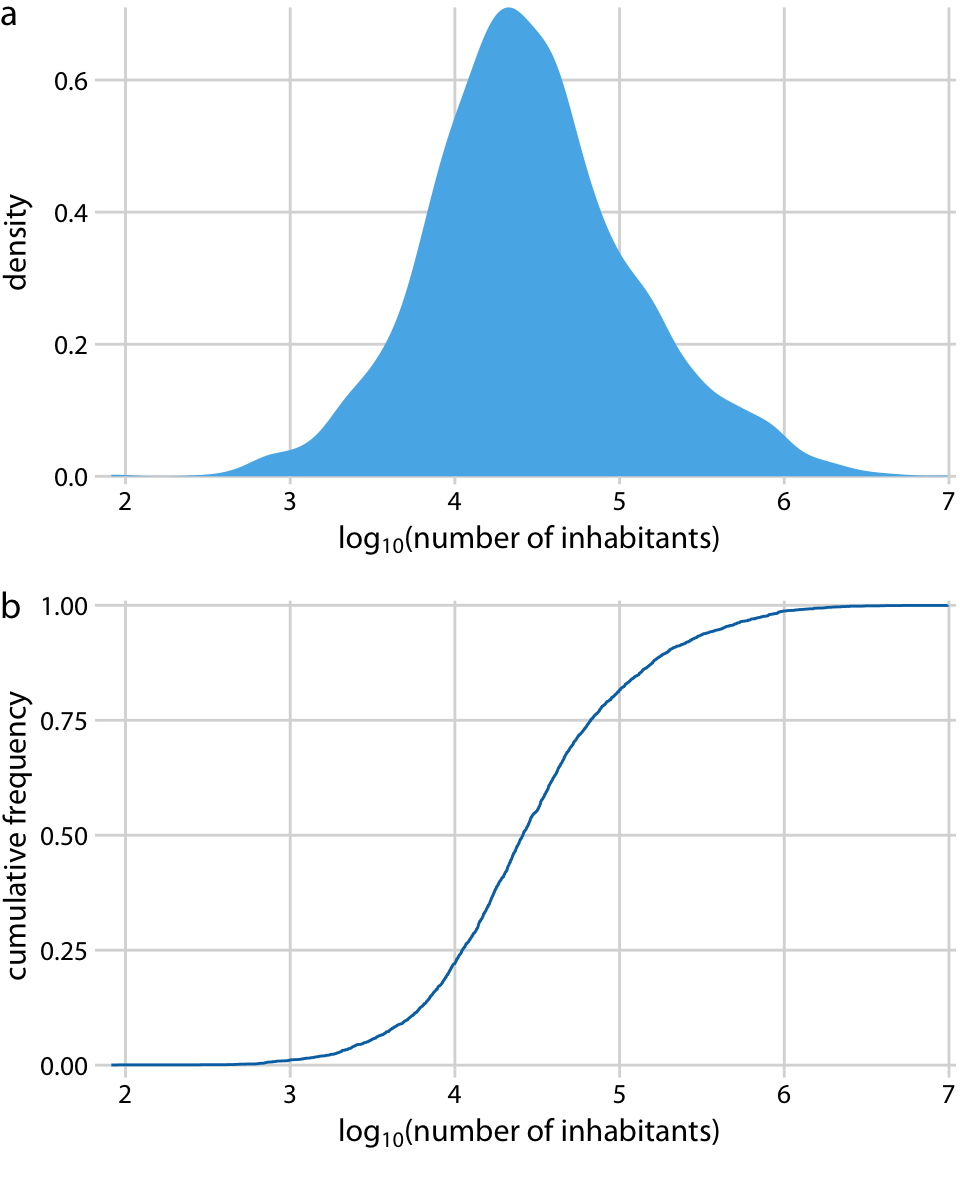
미국 각 군의 인구 수를 시각화한 그래프에 대해 설명하고 있습니다. (a)는 밀도 그래프를, (b)는 경험적 누적 분포 함수(ecdf)를 나타냅니다. 밀도 그래프에서는 0 근처에서 급격한 피크가 나타나고, 분포의 세부 사항은 거의 보이지 않습니다. 마찬가지로, ecdf도 0 근처에서 급격한 상승을 보여주며, 분포의 세부 사항을 파악하기 어렵습니다.
이러한 특정 데이터셋에 대해서는 로그 변환을 적용하고, 로그 변환된 값을 시각화하는 것이 유용합니다. 이 변환은 각 군의 인구 수가 실제로 멱법칙을 따르지 않고, 거의 완벽한 로그 정규 분포를 따르기 때문에 효과적입니다.
8.3 Quantile–quantile plots
q-q 플롯은 데이터가 주어진 분포를 얼마나 잘 따르는지를 확인할 때 유용한 시각화 도구입니다. ecdf와 마찬가지로, q-q 플롯도 데이터의 순위를 기반으로 하지만, 순위를 직접 플롯하는 대신 순위를 사용하여 주어진 분포를 기준으로 데이터 포인트가 어디에 위치할지 예측합니다.
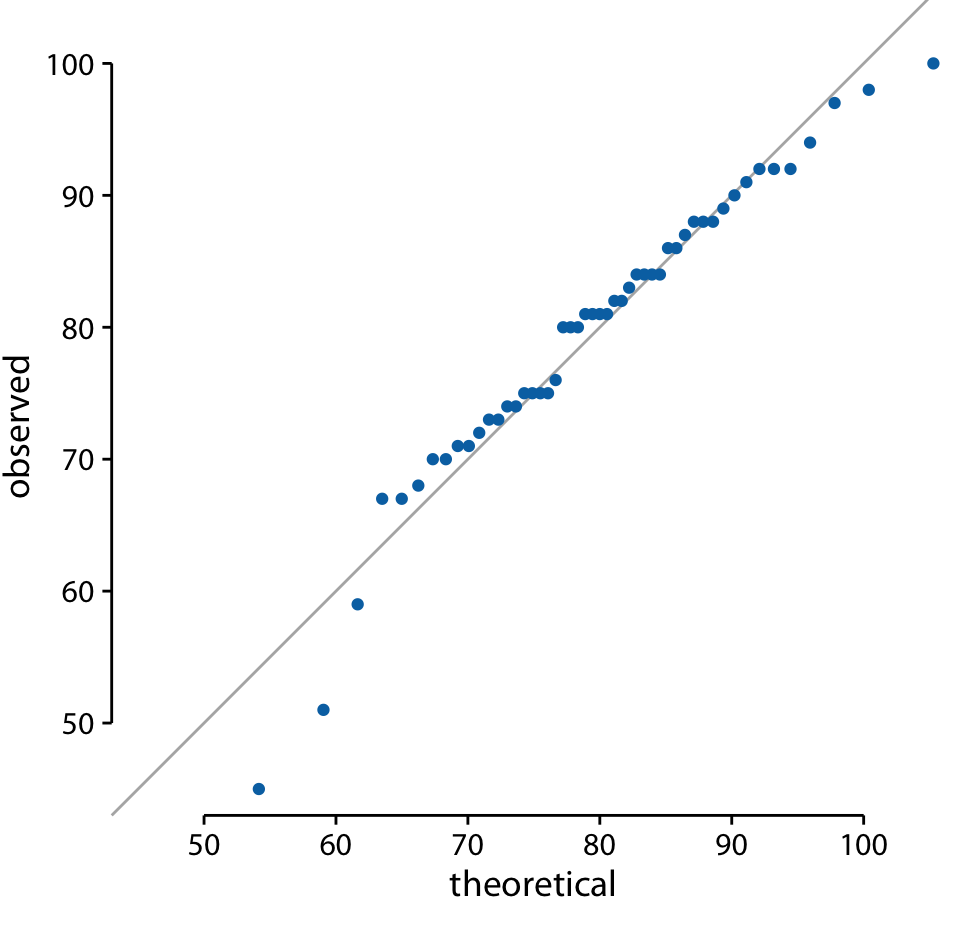
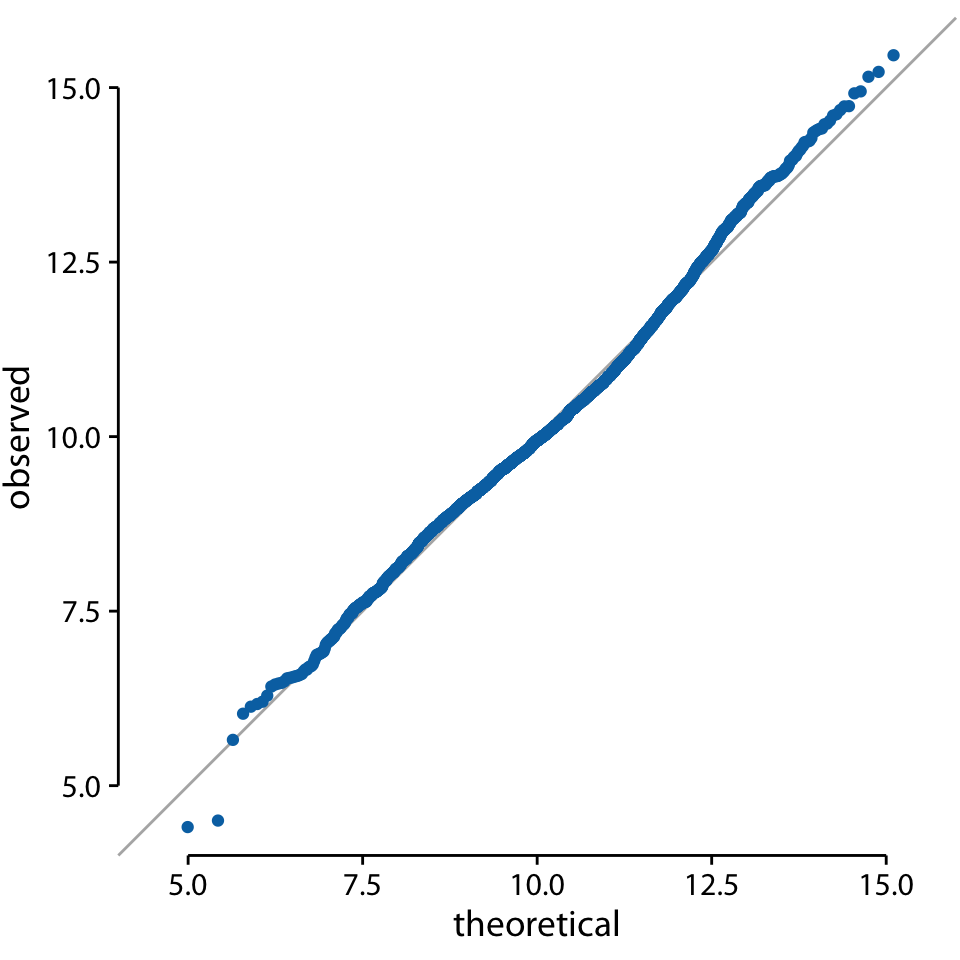
q-q 플롯을 통해 학생 성적이 얼마나 정규 분포에 가까운지를 시각적으로 평가할 수 있습니다. 여기에서 실선은 회귀선이 아니라, x값과 y값이 동일한 지점을 나타내는 선입니다, 즉, 관찰된 값이 이론적으로 예상된 값과 일치하는 지점을 나타냅니다. 데이터 포인트가 이 선에 가까울수록, 데이터는 가정된 분포(이 경우 정규 분포)를 잘 따르고 있음을 의미합니다.
q-q 플롯은 또한 이전에 언급한 미국 각 군의 인구 수가 로그 정규 분포를 따른다는 가설을 테스트하는 데에도 사용할 수 있습니다. 만약 이 인구 수가 로그 정규 분포를 따른다면, 로그 변환된 값들은 정규 분포를 따르며, 따라서 x = y 선에 정확히 일치해야 합니다. 이 플롯을 그려보면, 관찰된 값과 이론적 값 간의 일치도가 매우 뛰어남을 확인할 수 있습니다. 이는 미국 각 군의 인구 수 분포가 실제로 로그 정규 분포임을 시사합니다.